社区
西工大网安实践教学社区
帖子详情
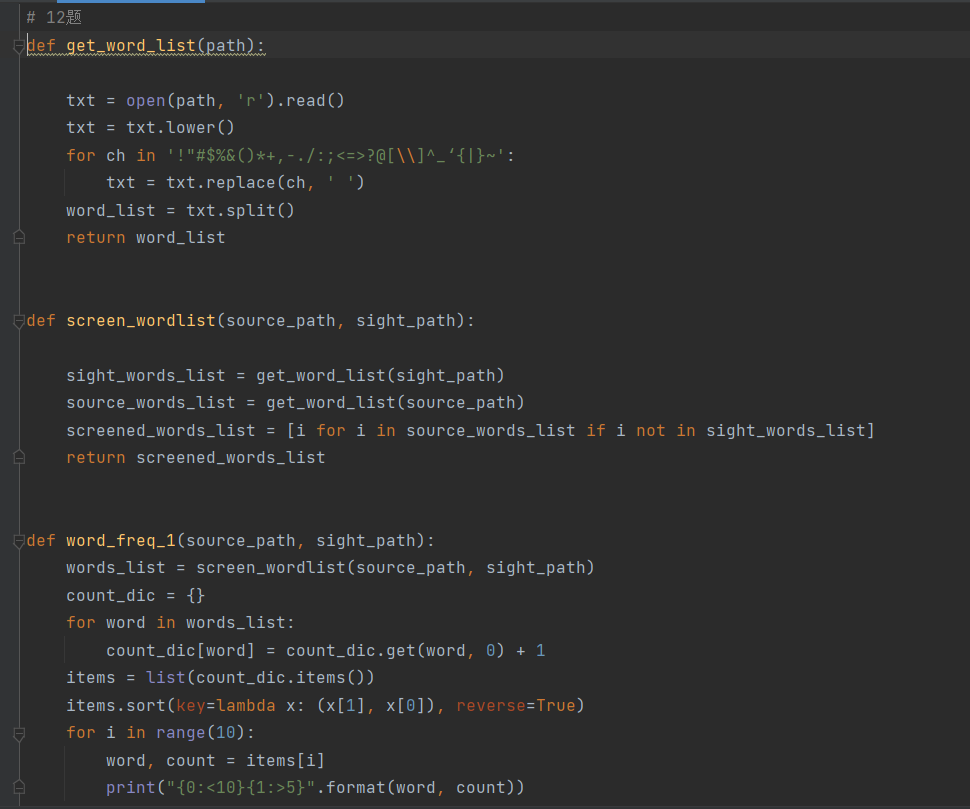
Py实训12-词频统计
2019300908-邱晓宇
2022夏-程序设计实训
2022-08-03 17:27:15
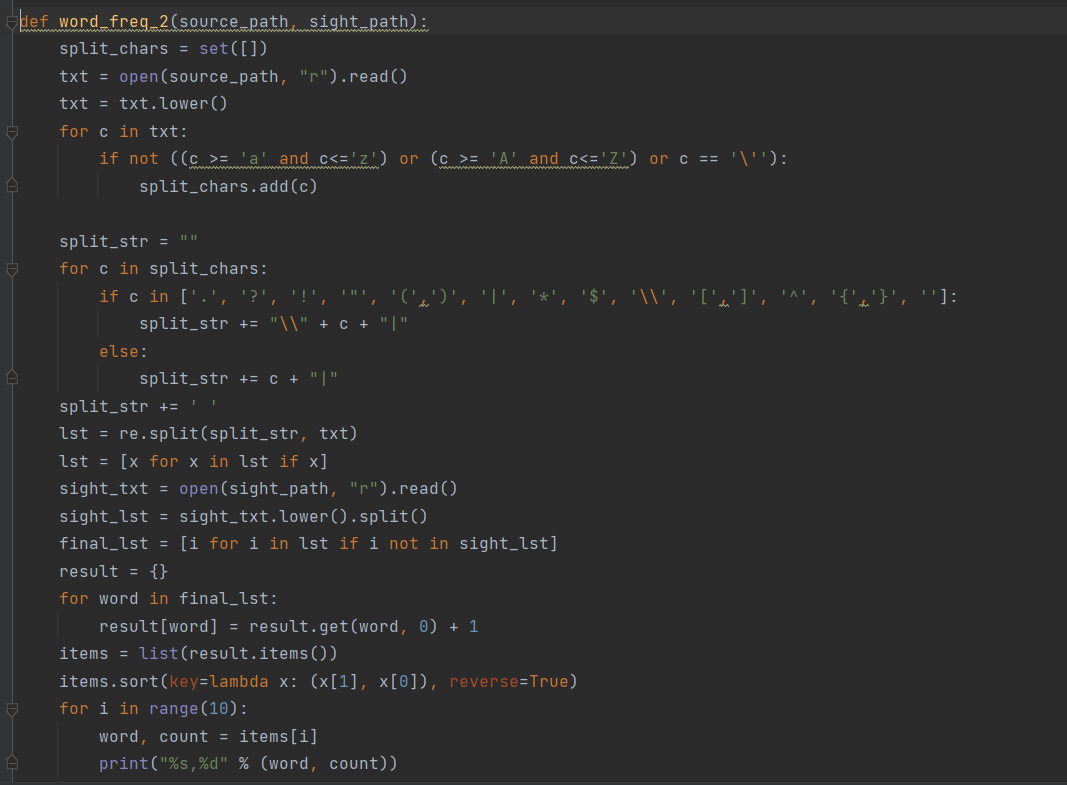
法二:
...全文
643
回复
打赏
收藏
Py实训12-词频统计
法二:
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
中文
词频统计
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2773 中文
词频统计
1. 下载一长篇中文小说。 2. 从文件读取待分析文本。 3. 安装并使用jieba进行中文分词。 pip install jieba import jieba ljieba.lcut(text) 4. 更新词库,加入所分析对象的...
py
thon
词频统计
代码_词云图
Py
thon利用jieba库做
词频统计
一.环境以及注意事项1.windows10家庭版
py
thon 3.7.
12
.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示请安装到C:\Windows\Fonts 里面5.调试过程可能会出现许多小问题,请检查单词是否拼写正确,如words->word等等6.特别提醒:背景图片和文本需 放在和
py
文件同一个地方二.
词频统计
以及输出(1) 代码如下(封装为tx...
Py
thon之利用jieba库做
词频统计
且制作词云图
一.环境以及注意事项 1.windows10家庭版
py
thon 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordcloud默认是英文不支持中文,所以需要一个特殊字体 simsum.tff.下载地址:https://s3-us-west-2.amazonaws.com/notion-static/b869cb0...
【高速互连技术】PCIe协议感知重定时器物理层扩展规范:Retimer设备在3.0/3.1链路中的透
内容概要:本文档为PCI-SIG发布的工程变更通知(ECN),主要针对PCI Express Base Specification 3.0/3.1版本,引入了物理层协议感知的重定时器(Retimer)的技术
【地理信息系统】基于房地一体的内外业协同作业平台:南方数码农村不动产调查数据处理与成果输出技术方案
内容概要:本文档详细介绍了“南方数码房地一体内外业软件”的操作流程,涵盖从数据准备、外业调查、内外业数据对接,到内业数据处理与成果输出的完整工作链。主要包括调查底图制作(支持DWG、MDB、SHP及倾斜三维模型等多种数据源)、导出外业IDB工程文件、平板端外业调查(宗地与房屋核实、电子签章表确认、照片导出)、内外业数据对接(DB与照片数据导入),以及内业的宗地信息完善、界址属性设置、自然幢生成、房屋面积计算、户属性录入,并最终输出宗地图、房产分户图、各类报表及MDB数据库等成果。; 适合人群:从事农村房地一体权籍调查的测绘、不动产登记及相关地理信息行业的内业处理人员、外业调查员和技术管理人员,需具备基础GIS或CAD操作能力; 使用场景及目标:①指导用户系统完成从原始数据到不动产登记成果的全流程作业;②实现外业调查数据高效采集与内业自动化处理衔接,提升房地一体确权登记工作的标准化与效率; 阅读建议:建议结合实际项目按章节顺序操作,重点关注数据格式转换、IDB工程交互逻辑及成果图输出设置,配合软件界面逐步实践,确保各环节数据完整性与准确性。
西工大网安实践教学社区
34
社区成员
195
社区内容
发帖
与我相关
我的任务
西工大网安实践教学社区
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
复制链接
扫一扫
分享
社区描述
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
python
安全
linux
高校
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

