社区
西工大网安实践教学社区
帖子详情
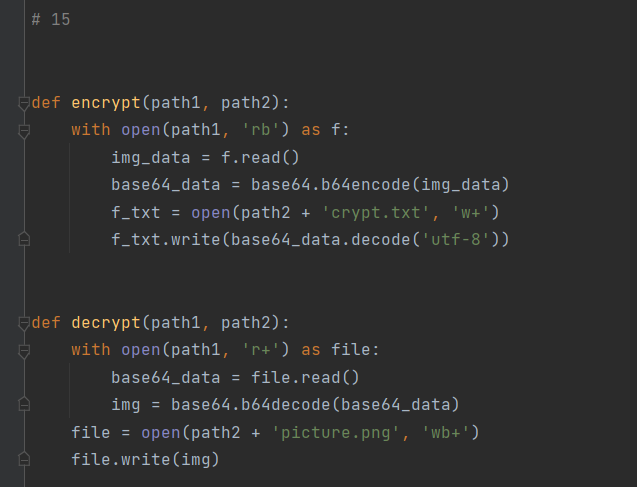
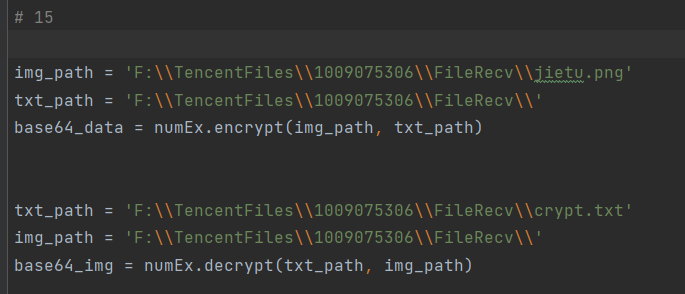
Py实训15-编码解码
2019300908-邱晓宇
2022夏-程序设计实训
2022-08-03 17:38:54
效果如下:
...全文
693
回复
打赏
收藏
Py实训15-编码解码
效果如下:
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
一图看懂
py
2/
py
3
编码
无论是
py
2还是
py
3,都使用unicode作为内存
编码
,简称内码。保存在
py
thon解释器内存中的文本,输出到屏幕、编辑器,或者保存成文件的时候,都要将内码转换成utf8或者gbk等
编码
格式;同样,
py
thon解释器从输入设备接收文本,或者从文件读取文本的时候,都要将utf8或者gbk等
编码
转换成unicode
编码
格式。因此,无论是
py
2还是
py
3,想要在unicode、utf8、gbk等
编码
格式之间转换的话,下图是通用的:
02-Media-1-acodec.
py
使用G.711
编码
和
解码
音频的示例程序
acodec.
py
是使用G.711
编码
和
解码
音频的示例程序。程序分为三个主要部分:
编码
音频、
解码
音频和循环编
解码
(实时采集、
编码
、
解码
并播放)。程序使用了media.
py
audio进行音频的采集和播放,使用media.g711进行G.711编
解码
。
Base64
编码
解码
与文件保存的实现与解析
Base64
编码
是一种基于 64 个可打印字符来表示二进制数据的
编码
方式。它将每 3 个字节(24 位)的数据转换为 4 个 Base64 字符(每个字符 6 位),从而实现二进制数据到文本数据的转换。Base64
编码
广泛应用于电子邮件附件、URL
编码
、数据库存储等领域。(Base64
编码
字符串)、(输出文件路径)和log_file(日志文件)。通过上述代码,我们可以将Base64
编码
解码
并保存为文件,同时记录操作日志。完整代码请前往链接t=N7T8。
py
thon url
编码
解码
_
Py
thon urllib模块的URL
编码
解码
功能
前面介绍了 urllib 模块,以及它常用的 urlopen() 和 urlretrieve()函数的使用介绍。当然 urllib 还有一些其它很有用的辅助方法,比如对 url 进行
编码
、
解码
等等。接下来我们再大概介绍一下。我们知道,url 中是不能出现一些特殊的符号的,有些符号有特殊的用途。比如以 get 方式提交数据的时候,会在 url 中添加 key=value 这样的字符串,所以在 val...
BSA
编码
及
解码
BSA
编码
及
解码
代码
西工大网安实践教学社区
34
社区成员
195
社区内容
发帖
与我相关
我的任务
西工大网安实践教学社区
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
复制链接
扫一扫
分享
社区描述
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
python
安全
linux
高校
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

