社区
西工大网安实践教学社区
帖子详情
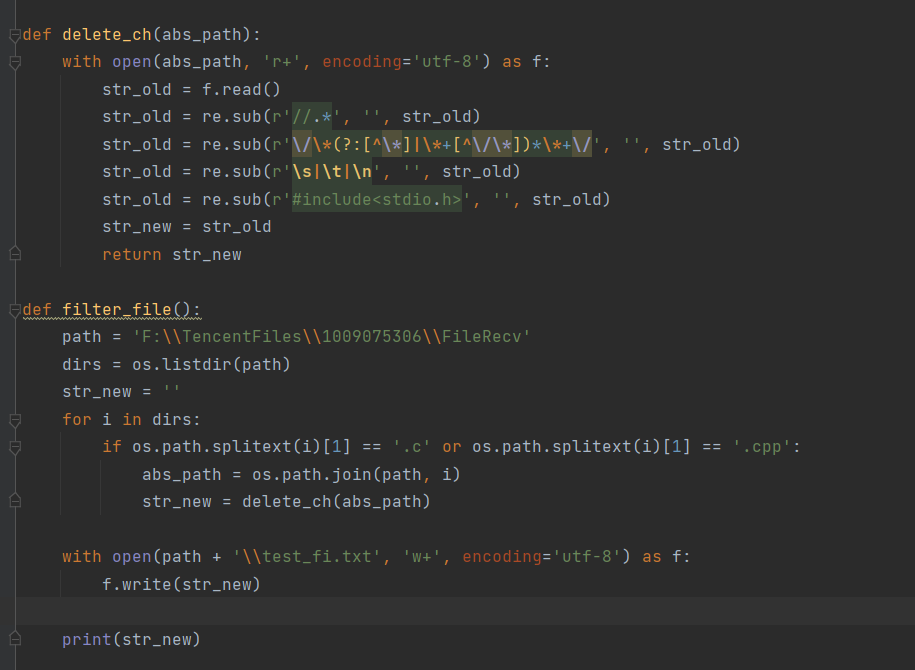
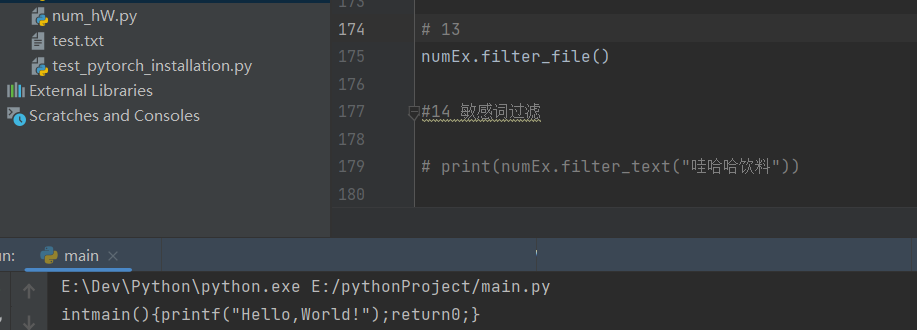
Py实训13-C文件处理
2019300908-邱晓宇
2022夏-程序设计实训
2022-08-03 17:31:18
...全文
617
回复
打赏
收藏
Py实训13-C文件处理
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
c2
py
试用(一)
来呀欢迎关注我的公众号「测试游记」installpip install https://github.com/nanoric/c2
py
/archive/master.zi...
libsvm中tools(easy.
py
,subset.
py
,grid.
py
,checkdata.
py
)的使用
这几天在用libsvm(2.8.6)中的一些工具,总结一下.libsvm的一些工具还是非常有用的,1.可以调用subset.
py
将你的样本集合按你所想要的比例进行抽样出两个子样本集合.2.还可以调用grid.
py
做关于(C,gamma)的交叉验证参数选择,可以轻松的搜索到最好的参数对(C,gamma).3.还可以调用easy.ph一步到位完成svm的整个挖掘过程,最后得出交叉验证精度,最有
py
thon compile_
py
thon之模块
py
_compile用法(将
py
文件
转换为
py
c
文件
)
# -*- coding: cp936 -*-#
py
thon 27#xiaodeng#
py
thon之模块
py
_compile用法(将
py
文件
转换为
py
c
文件
);二进制
文件
,是由
py
文件
经过编译后,生成的
文件
.#办法一:import
py
_compile#加r前缀进行转义
py
_compile.compile(r'D:\test.
py
')#
py
文件
完整的路径.办法二:#cmd命令符下操作步骤1、打开c...
YOLOv
13
最新创新改进系列:融合Faster Neural Networks,构建C2f-faster和C3-faster,更高更快更强,助力创新模型有效涨点!
YOLOv
13
最新创新改进系列:融合Faster Neural Networks,构建C2f-faster和C3-faster,更高更快更强,助力创新模型有效涨点!
ryu控制器源码分析-simple_switch_
13
.
py
源码: (附注释) # Co
py
right (C) 2011 Nippon Telegraph and Telephone Corporation. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with t...
西工大网安实践教学社区
34
社区成员
195
社区内容
发帖
与我相关
我的任务
西工大网安实践教学社区
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
复制链接
扫一扫
分享
社区描述
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
python
安全
linux
高校
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

