社区
西工大网安实践教学社区
帖子详情
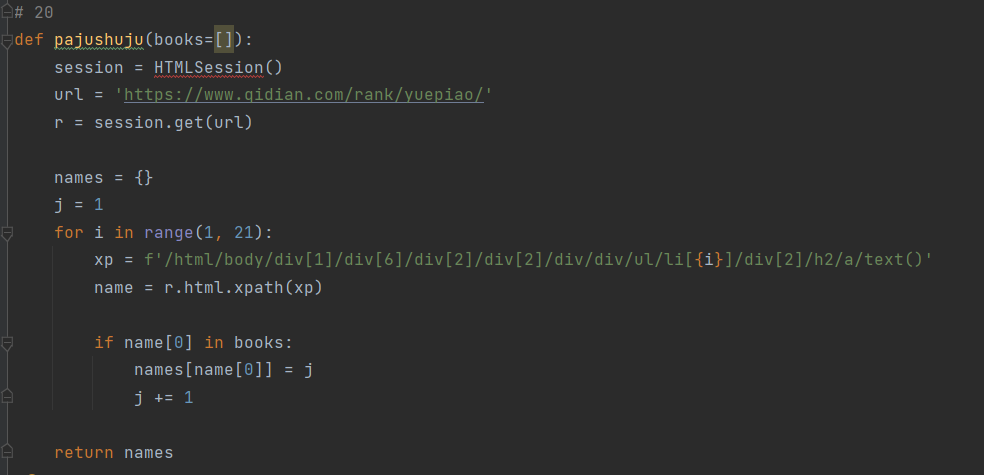
Py实训20-数据爬取
2019300908-邱晓宇
2022夏-程序设计实训
2022-08-03 17:58:17
...全文
826
回复
打赏
收藏
Py实训20-数据爬取
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
利用Scra
py
架构
爬取
网页
数据
步骤
Scra
py
架构
爬取
网页步骤 一、新建项目 (scra
py
startproject xxx):新建一个新的爬虫项目 1、在
py
charm开发工具终端输入命令: scra
py
startproject mySpider 2、执行命令之后在保存路径下会出现项目: 3、在
py
charm中新建项目: 二、明确目标 (编写items.
py
):明确你想要抓取的目标 1、构建 ...
最实用的GitHub
数据
爬取
指南:轻松掌握github_bot.
py
分页获取技巧
你是否在
爬取
GitHub
数据
时遇到过API请求限制?是否因无法获取完整
数据
而烦恼?本文将带你深入解析HelloGitHub项目中的[script/github_bot/github_bot.
py
](https://link.gitcode.com/i/9c9dd55d4f263613a8a5a02f22acfe1f)文件,掌握高效分页
爬取
GitHub
数据
的核心技巧,让你轻松获取完整的项目信息。 ...
Scra
py
实例:
爬取
中国天气网天气
数据
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\Scra
py
Project> scra
py
startproject weather # weather是项目名称 回车即创建成功 这个命令其实创建了一个文件夹而已,里面包含了框架规定的文件和子文件夹. 我们要做的就是编辑其中的一部分文件即可. 其实scra
py
构建爬...
py
thon
爬取
数据
并将其存入mongodb
py
thon
爬取
数据
并将其存入mongodb
利用
Py
thon
爬取
的
数据
存入Excel表格
分析要
爬取
的内容的网页结构: demo.
py
: import requests #requests是HTTP库 import re from open
py
xl import workbook # 写入Excel表所用 from open
py
xl import load_workbook # 读取Excel表所用 from bs4 import BeautifulSoup as bs ...
西工大网安实践教学社区
34
社区成员
195
社区内容
发帖
与我相关
我的任务
西工大网安实践教学社区
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
复制链接
扫一扫
分享
社区描述
依托实践实训环节,为同学们更好掌握所需的基本技能,提供一个交流学习的社区。
python
安全
linux
高校
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

