

34,875
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
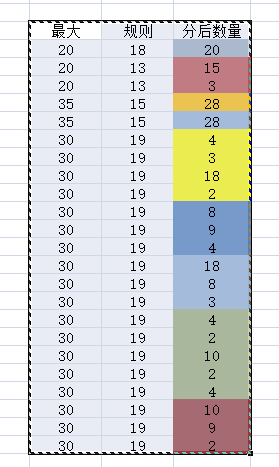
;with t as(
select 20 [最大] ,18 [规则],20 [分后数量] union all
select 20 [最大] ,13 [规则],15 [分后数量] union all
select 20 [最大] ,13 [规则],3 [分后数量] union all
select 35 [最大] ,15 [规则],28 [分后数量] union all
select 35 [最大] ,15 [规则],28 [分后数量] union all
select 30 [最大] ,19 [规则],4 [分后数量] union all
select 30 [最大] ,19 [规则],3 [分后数量] union all
select 30 [最大] ,19 [规则],18 [分后数量] union all
select 30 [最大] ,19 [规则],2 [分后数量] union all
select 30 [最大] ,19 [规则],4 [分后数量] union all
select 30 [最大] ,19 [规则],3 [分后数量]
)
--select 规则, 最大 ,分后数量
--from t
--order by 规则
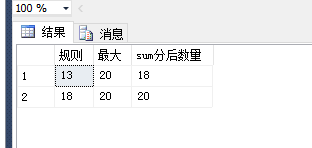
select 规则, 最大
,[sum分后数量] = sum(分后数量)
from t
group by 规则,最大
HAVING sum(分后数量)<=最大
order by 规则
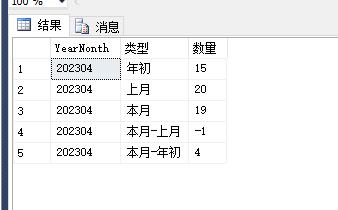

简单的sql无法直接处理,得用循环


为什么规则19的分后数量不是30 30 30 1 1 1这样,分满后积分分配在下一行?



