



1,588
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享AI 视觉是为了让计算机利用摄像机来替代人眼对目标进行识别,跟踪并进一步完成一些更加复杂的图像处理。这一领域的学术研究已经存在了很长时间,但直到 20 世纪 70 年代后期,当计算机的性能提高到足以处理图片这样大规模的数据时,计算机视觉才得到了正式的关注和发展。
现在 AI 视觉已经在我们的生活中无处不在,从日常使用的二维码到人脸识别直至更专业的病理分析。AI 视觉的应用所渗透到的领域远比我们想象的更加广泛。虽然 AI 视觉的应用已经随处可见,但如果想要自己去开发一套属于自己的 AI 视觉应用,对于一个非专业领域的开发者还是非常复杂的,单从最基础的算法训练就要消耗掉大量的精力与时间。
EdgerOS 系统则内置了多种不同方向的 AI 引擎,使开发者可以实现快速实现 AI 视觉领域的开发,极大的降低了开发周期。开发者可以根据自己的需求对不同 AI 引擎进行组合达到自己想要的业务实现。本文将带领大家一起了解 EdgerOS 中常用的两款 AI 引擎。
FaceNN 是 EdgerOS 所提供的一个针对人脸识别的 AI 处理引擎,它可以从视频流或者图片中捕捉到人脸的具体位置,还可以根据人脸的特征来分析出对应人物的特征信息如:年龄、性别、情感等一些具体信息。
FaceNN 引擎封装在 “facenn” 模块中,我们可以通过以下方式来导入
const facenn= require('facenn');
FaceNN 引擎提供了极简的接口,这使得开发者可以更加快速的实现关于人脸的 AI 处理,同时也降低了巨大的学习成本,接下来我们就一起来看看。
首先我们需要明确一下被识别的图像格式。目前 FaceNN 引擎支持如下格式:
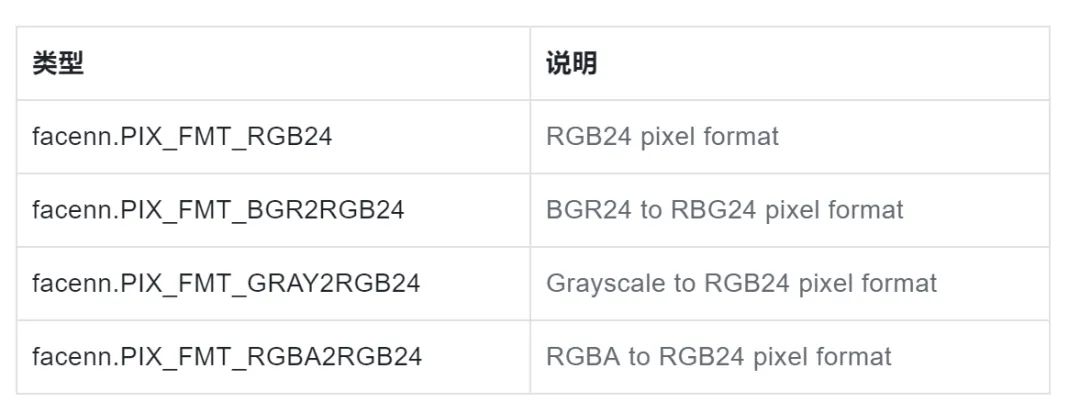
attribute {Object} 图像格式
width {Integer} 图像宽度
height {Integer} 图像高度
pixelFormat {Integer} 图像格式
quick {Boolean} 是否启用快速模式
返回信息:
score {Number} 人脸的覆盖率
x0 {Integer} 左上角 x 的位置
y0 {Integer} 左上角 y 的位置
x1 {Integer} 右下角 x 的位置
y1 {Integer} 右下角 y 的位置
area {Number} Area,非快速模式
regreCoord {Array} RegreCoord,非快速模式
landmark {Array} Landmark,非快速模式
facenn.detect 可以识别出一帧图像数据中的人脸个数以及人脸所在图像中的位置。
videoBuf {Buffer} 图像格式
attribute {Object} 图像属性
width {Integer} 图像宽度
height {Integer} 图像高度
pixelFormat {Integer} 图像格式
extra {Object} 需要扩展的人脸信息 default: undefined
返回信息:
keys {Array} Face keys
male {Boolean} 性别, 需要在扩展中选择
age {Integer} Age, 需要在扩展中选择
emotion {String} Emotion, 需要在扩展中选择
emotion 可分辨情绪包括: angry,disgust,fear,happy,sad,surprise,neutral
live {Number} 存活率,需要在扩展中选择
facenn.feature 可以识别出一张人像的具体信息,例如性别,情绪年龄等等。
faceKey1 {Object} Face keys 1
faceKey2 {Object} Face keys 2
返回信息:
相似值 0.0 ~ 1.0
facenn.compare 可以比对出两张人脸信息的相似值。
接下来我们用一下两张图片来尝试使用 FaceNN 引擎。读取其中的特征信息

image1.png

image2.png
const imagecodec = require('imagecodec'); // 图片解析模块
const facenn = require('facenn');
function facennHandel(imagePath, imagePath2) {
const image1 = imagecodec.decode(imagePath, imagecodec.COMPONENTS_RGB)
const imageInfo1 = imagecodec.info(imagePath)
const videoAttrFacenn = { width: imageInfo1.width, height: imageInfo1.height, pixelFormat: facenn.PIX_FMT_RGB24 }
const faceInfos = facenn.detect(image1.buffer, videoAttrFacenn);
const facennFeature = facenn.feature(image1.buffer, videoAttrFacenn, faceInfos[0], {
male: true,
age: true,
emotion: true,
live: true
})
console.log(`image1.png male:${facennFeature.male} age:${facennFeature.age} emotion:${facennFeature.emotion} live:${facennFeature.live}`)
const image2 = imagecodec.decode(imagePath2, imagecodec.COMPONENTS_RGB)
const imageInfo2 = imagecodec.info(imagePath2)
const videoAttrFacenn2 = { width: imageInfo2.width, height: imageInfo2.height, pixelFormat: facenn.PIX_FMT_RGB24 }
const faceInfos2 = facenn.detect(image2.buffer, videoAttrFacenn2);
const facennFeature2 = facenn.feature(image2.buffer, videoAttrFacenn2, faceInfos2[0], {
male: true,
age: true,
emotion: true,
live: true
})
console.log(`image2.png male:${facennFeature2.male} age:${facennFeature2.age} emotion:${facennFeature2.emotion} live:${facennFeature2.live}`)
const compareNum = facenn.compare(facennFeature.keys, facennFeature2.keys)
console.log(compareNum)
}
facennHandel('/image/image1.png', '/image/image2.png')
// 输出如下:
// [JSRE-CON]image1.png male:false age:21 emotion:neutral live:0.9843575954437256
// [JSRE-CON]image2.png male:true age:58 emotion:sad live:0.33667701482772827
// [JSRE-CON]-0.1453045904636383
ThingNN 是 EdgerOS 可以从视频流或者图片中捕捉到具体事物,分别标记事务所在图片中的具体位置。
ThingNN 引擎封装在 “thingnn” 模块中,我们可以通过以下方式来导入
const facenn= require('thingnn');
同样我们也需要明确一下被识别的图像格式。目前 ThingNN 引擎支持如下格式:

接下来我们看看 ThingNN 接口提供了那些接口:
videoBuf {Buffer} 图像格式
attribute {Object} 图像属性
width {Integer} 图像宽度
height {Integer} 图像高度
pixelFormat {Integer} 图像格式
返回信息:
className{Array} Face keys
prob{Boolean} 性别, 需要在扩展中选择
x0 {Integer} 左上角 x 的位置
y0 {Integer} 左上角 y 的位置
x1 {Integer} 右下角 x 的位置
y1 {Integer} 右下角 y 的位置
目前 ThingNN 模块所支持可识别的类型都有:
background, aeroplane, bicycle, bird, boat,bottle, bus, car, cat, chair,cow, diningtable, dog, horse,motorbike,person, pottedplant,sheep, sofa, train, tvmonitor
thingnn.detect 可以获取到图片中事物的类别以及所在图像中的位置。
videoBuf {Buffer} 图像格式
attribute {Object} 图像属性
width {Integer} 图像宽度
height {Integer} 图像高度
pixelFormat {Integer} 图像格式
thingInfo {Object} 事务对象
返回信息:
具体事物的名称
thingnn.identify 可以获取到具体 thinginfo 的类型名称。
接下来我们具体看看代码实现,我们以下图为例子作为演示:

dog.png
const imagecodec = require('imagecodec'); // 图片解析模块
const facenn = require('facenn');
function licplatennHandel(imagePath) {
const imageInfo = imagecodec.info(imagePath)
const imageBuf= imagecodec.decode(imagePath, imagecodec.COMPONENTS_RGB).buffer
let videoAttrThingnn = { width: imageInfo.width, height: imageInfo.height, pixelFormat: thingnn.PIX_FMT_BGR24 }
const thingInfos = thingnn.detect(imageBuf, videoAttrThingnn);
thingInfos.forEach((thingInfo, index) => {
const thingName = thingnn.identify(imageBuf, videoAttrThingnn, thingInfo);
console.log(index,thingInfo.className, thingName)
})
}
licplatennHandel('/image/dog.png')
// 输出如下:
// [JSRE-CON]0 dog Labrador retriever
篇幅有限,只能暂且先介绍 EdgerOS 中这两种 AI 图像引擎。除此之外 EdgerOS 中还涵盖了手势识别引擎,车牌识别引擎,以及一个强大的神经网络推理框架。这些就靠大家自己去 EdgerOS 中探索啦,希望本篇文章对各位有所帮助。
EdgerOS AI Engine 官方文档 【FaceNN】
EdgerOS AI Engine 官方文档 【HandNN】
EdgerOS AI Engine 官方文档 【ThingNN】
EdgerOS AI Engine 官方文档 【LicPlateNN】


