



1,387
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享作为人类,我们每天都在不停地移动,做一些动作,比如走路、跑步和坐着。这些行为是我们日常生活的自然延伸。构建能够捕获这些特定动作的应用程序在体育分析领域、医疗保健领域、零售领域以及其他领域都非常有价值。
然而,构建和部署能够理解人类行为的时间信息的人工智能应用程序既具有挑战性又耗时,需要大量培训和深入的人工智能专业知识。
在这篇文章中,我们将展示如何快速跟踪 AI 应用程序的开发,方法是采用预训练的动作识别模型,使用 NVIDIA TAO Toolkit 自定义数据和类对其进行微调,并通过 NVIDIA DeepStream 部署它进行推理,而无需任何 AI 专业知识。
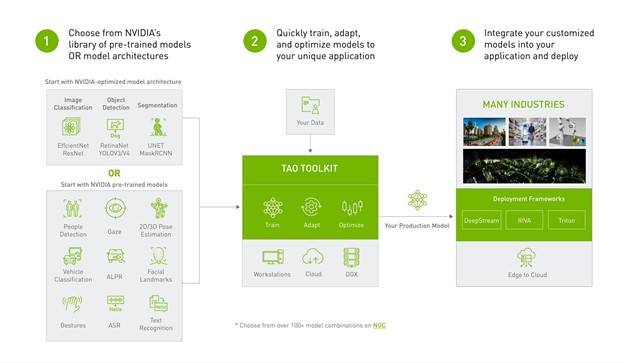 图 1 。端到端工作流从预训练模型开始,使用 TAO 工具包进行微调,并使用 DeepStream 进行部署
图 1 。端到端工作流从预训练模型开始,使用 TAO 工具包进行微调,并使用 DeepStream 进行部署
要识别一个动作,网络不仅要查看单个静态帧,还要查看多个连续帧。这提供了理解操作的时间上下文。这是与分类或目标检测模型相比的额外时间维度,其中网络仅查看单个静态帧。
这些模型是使用二维卷积神经网络创建的,其中的尺寸是宽度、高度和通道数。 2D 动作识别模型与其他 2D 计算机视觉模型类似,但通道维度现在也包含时间信息。
2D 和 3D 卷积网络的输出进入一个完全连接的层,然后是一个 Softmax 层来预测动作。
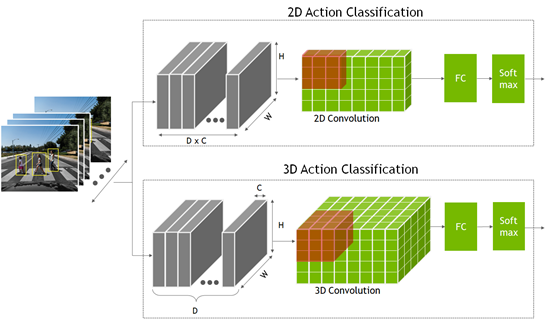 图 2 .动作识别 2D 和 3D 卷积网络
图 2 .动作识别 2D 和 3D 卷积网络
pretrained model 是在代表性数据集上经过训练并使用权重和偏差进行微调的数据集。 NGC catalog 提供的动作识别模型已在五个常见类别上进行了培训:
这是一个示例模型。更重要的是,该模型可以很容易地用自定义数据重新训练,只需花费很少的时间和从头开始训练所需的数据。
预训练模型是在 HMDB51 数据集中的几百个短视频剪辑上训练的。对于模型培训的五个类, 2D 模型的精度达到 83% , 3D 模型的精度达到 86% 。此外,如果选择按原样部署模型,下表显示了各种 GPU 上的预期性能。
| Inference Performance (FPS) | 2D ResNet18 | 3D ResNet18 |
| Nano | 30 | 0.6 |
| NVIDIA Xavier NX | 250 | 5 |
| NVIDIA AGX Xavier | 490 | 33 |
| NVIDIA A30 | 5,809 | 356 |
| NVIDIA A100 | 10,457 | 640 |
表 1 。模型的预期推理性能
在本实验中,您将使用三个新类对模型进行微调,这些新类包含简单动作,如俯卧撑、仰卧起坐和引体向上。您使用 HMDB51 数据集的子集,其中包含 51 个不同的操作。
开始之前,您必须拥有以下培训和部署资源:
有关更多信息,请参阅 TAO 工具包快速入门指南 。
在本节中,您将使用 TAO 工具包使用新类对模型进行微调。
TAO 工具包使用 transfer learning ,其中使用从现有神经网络模型学习的特征,并将其应用于新的神经网络模型。 TAO 工具包是 NVIDIA TAO 框架 基于 CLI 和 Jupyter 笔记本的解决方案,它抽象了 AI / DL 框架的复杂性,使您能够在没有任何 AI 专业知识的情况下为您的用例创建定制和生产就绪的模型。
您可以在 CLI 窗口中提供简单指令,也可以使用交钥匙 Jupyter 笔记本进行培训和微调。您可以使用 NGC 中的动作识别笔记本来训练自定义的三类模型。
下载 TAO Toolkit 计算机视觉示例工作流 的 1.3 版并解压缩包。在/action_recognition_net目录中,找到用于动作识别培训的 Jupyter 笔记本(actionrecognitionnet.ipynb),以及/specs目录,其中包含用于培训、评估和模型导出的所有规范文件。您可以为培训配置这些等级库文件。
启动 Jupyter 笔记本并打开action_recognition_net/actionrecognitionnet.ipynb文件:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
所有培训步骤都在 Jupyter 笔记本中运行。启动笔记本后,运行笔记本中提供的 设置环境变量和映射驱动器 和 安装 TAO 发射器 步骤。
安装 TAO 后,下一步是下载并准备数据集进行培训。 Jupyter 笔记本提供了下载和预处理 HMDB51 数据集的步骤。如果您有自己的自定义数据集,则可以在步骤 2.1 中使用它。
对于本文,您将使用 HMDB51 数据集中的三个类。修改几行以添加俯卧撑、引体向上和仰卧起坐课程。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar $ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos $ mkdir -p $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
每个类的视频文件存储在$HOST_DATA_DIR/raw_data下各自的目录中。这些是经过编码的视频文件,必须解压缩为帧才能训练模型。已经提供了一个脚本来帮助您为培训准备数据。
下载帮助程序脚本并安装依赖项:
$ git clone https://github.com/NVIDIA-AI-IOT/tao_toolkit_recipes.git $ pip3 install xmltodict opencv-python
将视频文件解压缩为帧:
$ cd tao_recipes/tao_action_recognition/data_generation/ $ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data \ $HOST_DATA_DIR/processed_data
下面的代码示例中显示了每个类的输出。f cnt: 82表示此视频剪辑已解压缩到 82 帧。对目录中的所有视频执行此操作。根据类的数量以及数据集和视频剪辑的大小,此过程可能需要一些时间。
Preprocess pullup f cnt: 82.0 f cnt: 82.0 f cnt: 82.0 f cnt: 71.0 ...
处理后的数据的格式类似于下面的代码示例。如果您正在对自己的数据进行培训,请确保数据集也遵循此目录格式。



