




136,225
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享一、概念
索引(Index)是帮助MySQL高效获取数据的排好序的数据结构。MyISAM和Innodb都使用了B+树这种数据结构做为索引。每建一个索引就会将索引数据按照B+树的数据结构创建,将相关数据冗余的存储一份,加快搜索速度.
二、分类
索引分为聚簇索引(clustered index )和非聚簇索引(secondary index)两种,在一个表中只能有一个聚集索引,在InnoDB引擎中以主键作为聚集索引,而非聚集索引可以有多个,除了聚集索引其他都是非聚集索引。
另外,当主键索引失去作用,为防止顺序查找,这时我们在其他要检索的列上建立第二套索引(使这一棵B+树的结点中存储辅助键,从而可找到辅助键来进行检索),这个就是二级索引或者叫辅助键索引,除了主键索引之外其他的所有索引都是二级索引。 这个索引由独立的B+树来组织。为以解决多个B+树访问同一套表数据的问题,于是引起2种索引,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index);它们并不是一种单独的索引类型,而是一种数据存储方式。
不同的存储引擎对聚集索引和非聚集索引的实现方式不同:
聚集索引:聚集索引表记录的排列顺序和索引的排列顺序一致(以InnoDB聚集索引的主键索引来说,叶子节点中存储的就是行数据,行数据在物理储器中的真实地址就是按照主键索引树形成的顺序进行排列的),所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序(因为在真实物理存储器的存储顺序只能有一种,而插入新数据必然会导致主键索引树的变化,主键索引树的顺序发生了改变,叶子节点中存储的行数据也要随之进行改变,就会发生大量的数据移动操作,所以效率会慢)。因为在物理内存中的顺序只能有一种,所以聚集索引在一个表中只能有一个。
非聚集索引:非聚集索引制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致(在逻辑上数据是按顺序排存放的,但是物理上在真实的存储器中是散列存放的),两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。所以如果表的读操作远远多于写操作,那么就可以使用非聚集索引。
总结:聚集索引的主键索引和辅助键索引叶子结点树存储内容是有区别的。而非聚集索引的主键索引和辅助键索引的存储结构其实是没有区别,叶子节点中数据区存储的都是指向数据行数据的指针,唯一的区别就是索引树节点中的索引区存储的索引字段不同了。
三、原理
3.1、InnoDB存储引擎索引的实现
InnoDB存储引擎是将主键索引用聚集索引,二级索引用非聚集索引来管理。
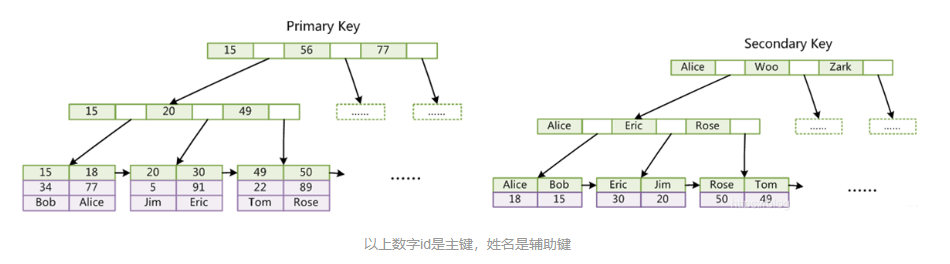
如上图所示,聚集索引中将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 18"这样的条件查找主键(使用主键索引),则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索(使用二级索引),则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作(回表),最终到达叶子节点即可获取整行数据。如果没有为表定义PRIMARY KEY,MySQL将找到第一个UNIQUE索引,其中所有键列都是NOT NULL,而InnoDB将它用作聚集索引。如果表没有PRIMARY KEY或合适的UNIQUE索引,InnoDB会在包含行ID值的合成列内部生成名为GEN_CLUST_INDEX的隐藏聚集索引 。因为MySQL的默认存储引擎是InnoDB,所以创建的主键索引就是聚集索引。其实主键索引和聚集索引并没有必然联系,非聚集索引也有主键索引。聚集索引只是一种数据存储的方式,不同的存储引擎有不同的实现。只是因为MySQL默认是InnoDB引擎,所以创建的主键也就默认是聚集索引。即主键是聚集索引还是非聚集索引取决于这个表的存储引擎是InnoDB还是MyISAM。
InnoDB存储引擎的表文件:
3.2、MyISAM索引实现(非聚集索引)
MyISAM使用的是非聚簇索引,不支持聚集索引。非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据(指向的就是对应的这一行全部的字段数据),对于表数据来说,主键索引树和辅助键索引树没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
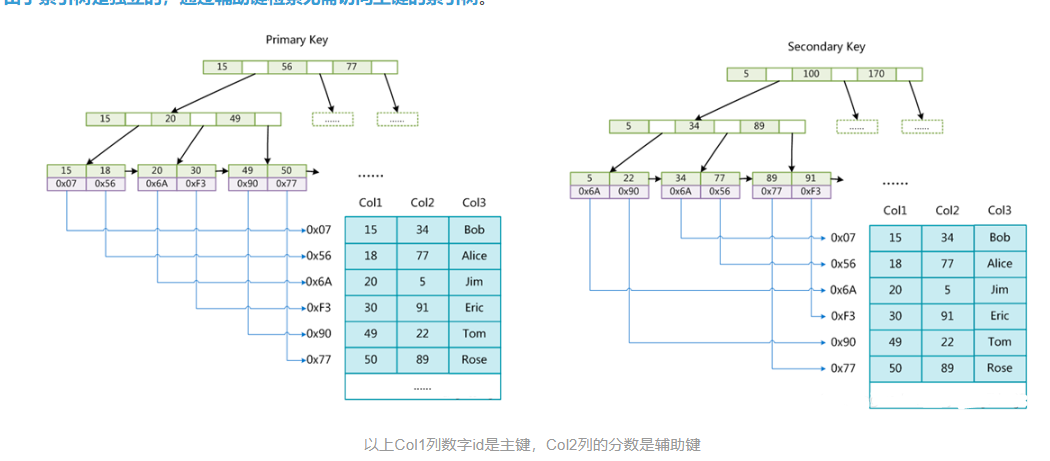
MyISAM存储引擎下的表文件:
3、InnoDB的索引与MyISAM的索引的区别

4、聚集索引的优劣势
1)优势:
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,而不用再通过存储的地址再去硬盘中查询一次数据行,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,详细可以看计算机操作系统分页管理相关章节)会随着数据库里数据的修改而发生变化(B+树节点分裂以及Page的分裂),使用InnoDB就可以保证不管这个主键B+树(聚集索引)的节点如何变化,辅助索引树(非聚集索引)都不受影响。
3 聚集索引的数据都是按顺序存放的,所以如果查询条件是主键,使用主键索引,那么聚集索引会非常快,因为相同范围段的数据都是连续存放在一起的。即聚集索引表记录的物理排列顺序与索引的逻辑排列顺序一致,优点是查询速度快,一旦符合条件的第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。聚集索引的主键索引的叶子节点中直接存储行数据,又因为B+树的叶子节点之间都会用过指针相连,所以直接就能很快将这个范围内的数据全部获取。但是非聚集索引的主键索引虽然在逻辑上相同范围的叶子节点是顺序存储在一起的,但是真实的行数据是在硬盘中散列存储的,要想获取数据还需要将存储在叶子节点中的地址取出,根据地址再去硬盘中获取数据,效率就慢了很多。这个是聚集索引的主键索引的优势,也是第一条优势的具体体现。根据局部性原理,这也会提高检索效率。
2)劣势
聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入)。而非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式(这个指针可能是真实的物理地址,也可能是对应的主键值,这根据不同的存储引擎对它实现是不同的)。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
总结:聚集索引查询数据速度快,插入数据速度慢;非聚集索引反之。他们各自优缺点就是相反的。
四、聚集索引和非聚集索引的区别
聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序
非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序.
索引是通过B+树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
