


203
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业-论文查重 |
| 作业需求 | 论文查重 |
https://github.com/Zwh-max/PaperCheck
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 770 | 930 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 90 | 90 |
| · Coding | · 具体编码 | 200 | 240 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 180 |
| Reporting | 报告 | 240 | 250 |
| · Test Repor | · 测试报告 | 60 | 70 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 120 |
| · 合计 | 1070 | 1240 |
MainPaperCheck:main 方法所在的类
HammingUtils:计算海明距离的类
SimHashUtils:计算 SimHash 值的类
TxtIOUtils:读写 txt 文件的工具类
ShortStringException:处理文本内容过短的异常类
类:SimHashUtils
包含了两个静态方法:
1、getHash:传入String,计算出它的hash值,并以字符串形式输出,(使用了MD5获得hash值)
2、getSimHash:传入String,计算出它的simHash值,并以字符串形式输出,(需要调用 getHash 方法)
getSimHash 是核心算法,主要流程如下:
1、分词(使用了外部依赖 hankcs 包提供的接口)
List<String> keywordList = HanLP.extractKeyword(str, str.length());//取出所有关键词
2、获取 hash 值
String keywordHash = getHash(keyword);
if (keywordHash.length() < 128) {
// hash值可能少于128位,在低位以0补齐
int dif = 128 - keywordHash.length();
for (int j = 0; j < dif; j++) {
keywordHash += "0";
}
}
3、加权、合并
for (int j = 0; j < v.length; j++) {
// 对keywordHash的每一位与'1'进行比较
if (keywordHash.charAt(j) == '1') {
//权重分10级,由词频从高到低,取权重10~0
v[j] += (10 - (i / (size / 10)));
} else {
v[j] -= (10 - (i / (size / 10)));
}
}
4、降维
String simHash = "";// 储存返回的simHash值
for (int j = 0; j < v.length; j++) {
// 从高位遍历到低位
if (v[j] <= 0) {
simHash += "0";
} else {
simHash += "1";
}
}
·main 方法的主要流程:
·从命令行输入的路径名读取对应的文件,将文件的内容转化为对应的字符串
·由字符串得出对应的 simHash值
·由 simHash值求出相似度
·把相似度写入最后的结果文件中
·退出程序
·Overview
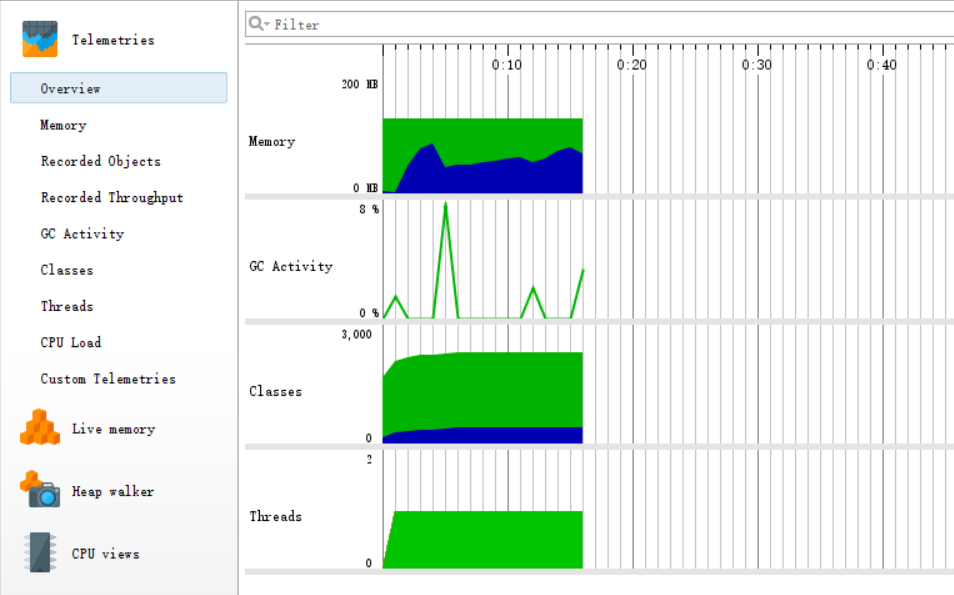
·方法调用
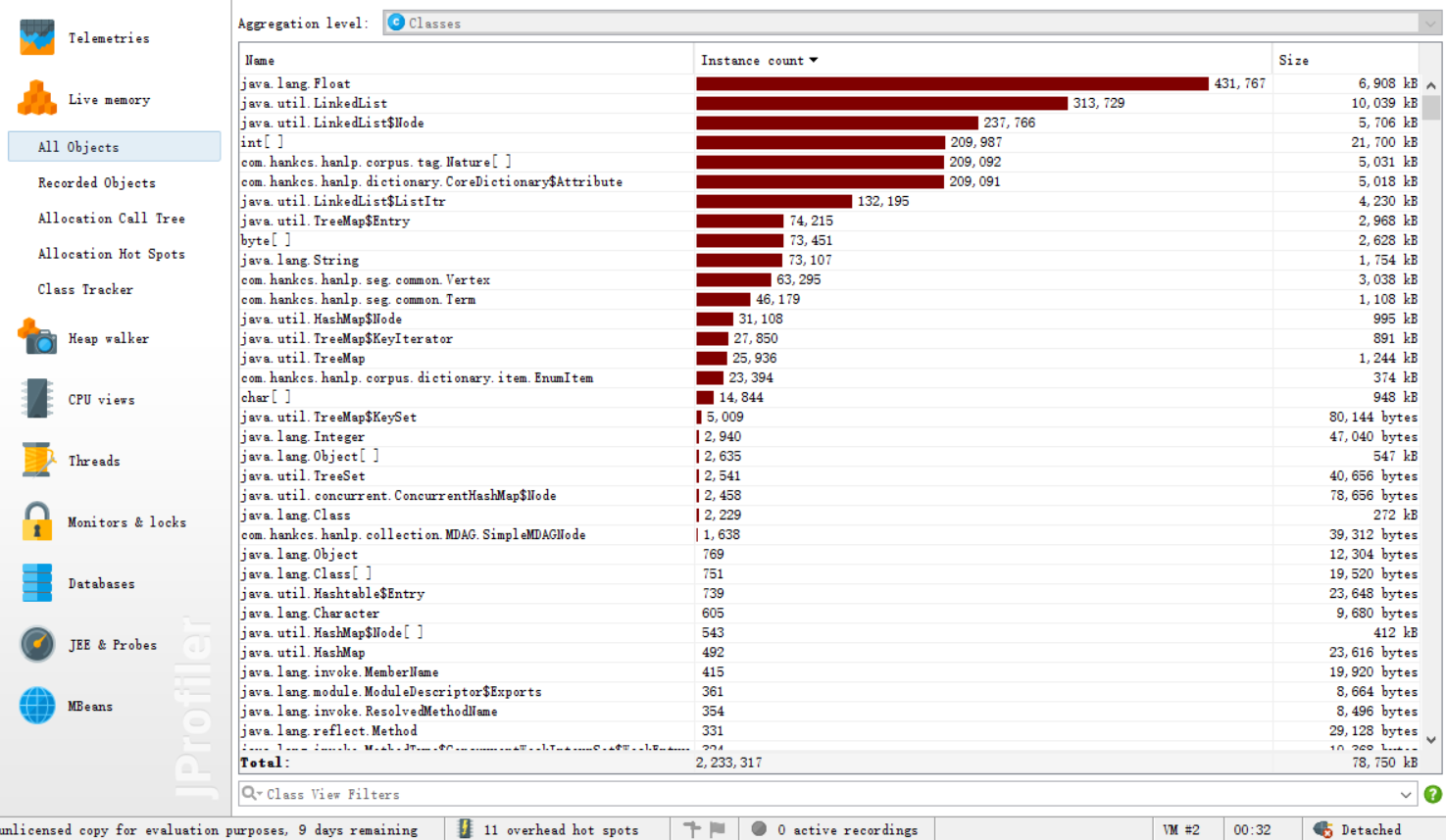
调用次数最多的是com.hankcs.hanlp包提供的接口, 即分词、取关键词与计算词频花费了最多的时间。
所以在性能上基本没有什么需要改进的。
部分代码:
public class MainTest {
@Test
public void origAndAllTest(){
String[] str = new String[6];
str[0] = TxtIOUtils.readTxt("D:/test/orig.txt");
str[1] = TxtIOUtils.readTxt("D:/test/orig_0.8_add.txt");
str[2] = TxtIOUtils.readTxt("D:/test/orig_0.8_del.txt");
str[3] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_1.txt");
str[4] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_10.txt");
str[5] = TxtIOUtils.readTxt("D:/test/orig_0.8_dis_15.txt");
String ansFileName = "D:/test/ansAll.txt";
for(int i = 0; i <= 5; i++){
double ans = HammingUtils.getSimilarity(SimHashUtils.getSimHash(str[0]), SimHashUtils.getSimHash(str[i]));
TxtIOUtils.writeTxt(ans, ansFileName);
}
}
}
测试结果:

结果文件:

当文本长度太短时,HanLp无法取得关键字,需要抛出异常。
try{
if(str.length() < 200) throw new ShortStringException("文本过短!");
}catch (ShortStringException e){
e.printStackTrace();
return null;
}
测试结果:


