



203
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 软件工程班级社区 |
|---|---|
| 这个作业要求在哪里 | 结对编程:小学四则运算 |
| 这个作业的目标 | 使用python实现一个自动生成小学四则运算题目的命令行程序 |
| 姓名 | 学号 | github地址 |
|---|---|---|
| 林秀霞 | 3220005139 | Arithmitic |
| 覃琬淇 | 3220004730 |
win10/ Pycharm Professional 2022.1/ Python
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 700 | 880 |
| Analysis | 需求分析(包括学习新技术) | 120 | 100 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 10 |
| Design | 具体设计 | 100 | 180 |
| Coding | 具体编码 | 180 | 260 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试、修改代码、提交修改) | 30 | 30 |
| Reporting | 报告 | 180 | 120 |
| Test Repor | 测试报告 | 90 | 30 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 20 |
| 合计 | 1600 | 1765 |
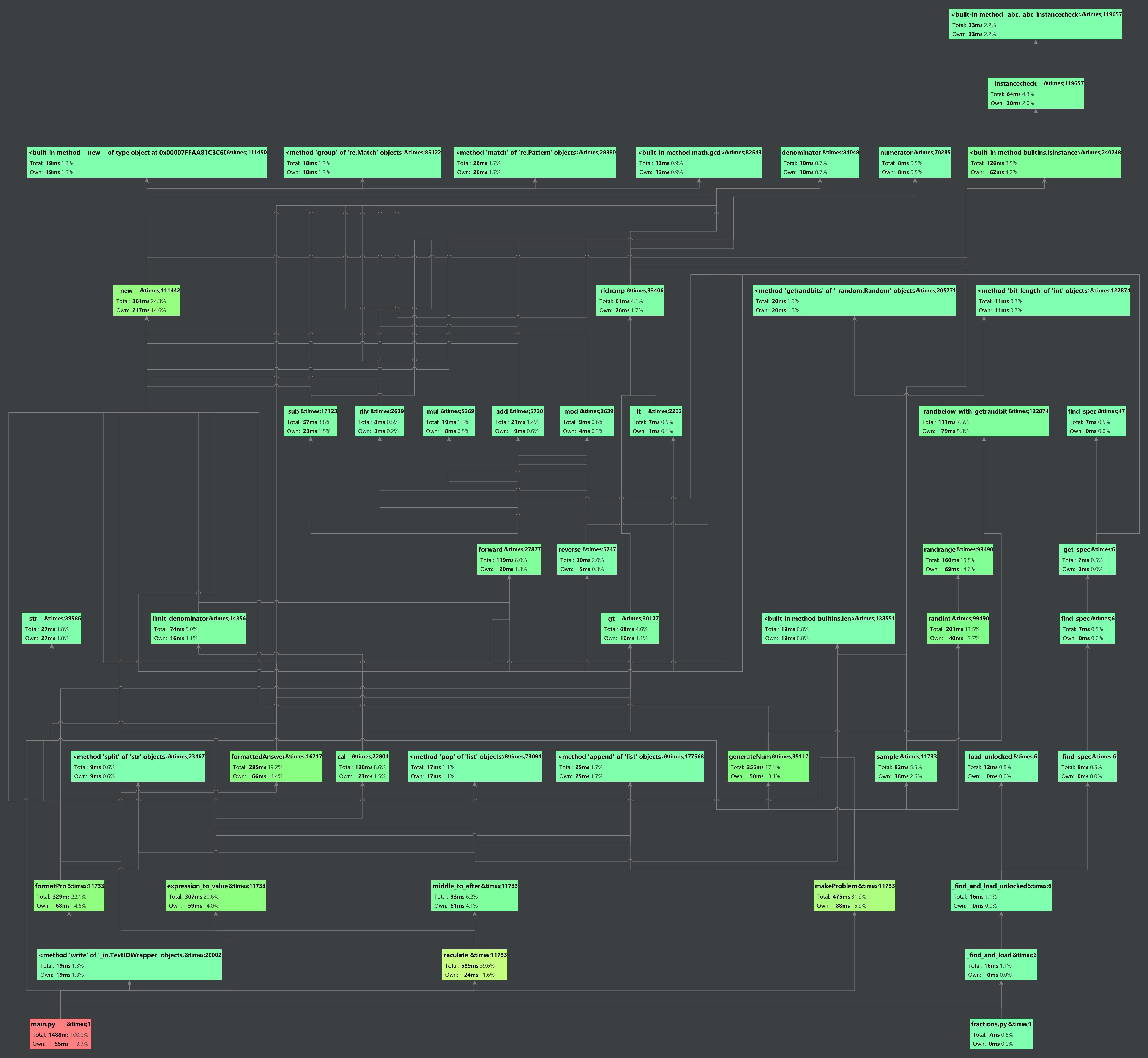
改进程序性能化的时间不是很多,因为并没有把这个当作一个另外的步骤,而是在一边写的时候会有意识地思考如何减少时间的开销。
比如说在计算的时候,由于后继表达式是分步入栈出栈进行计算的,我们这里一旦遇到除数为0,或者子计算过程中遇到负数,立马return,不再进行后面的计算,这样也减少了一点时间。
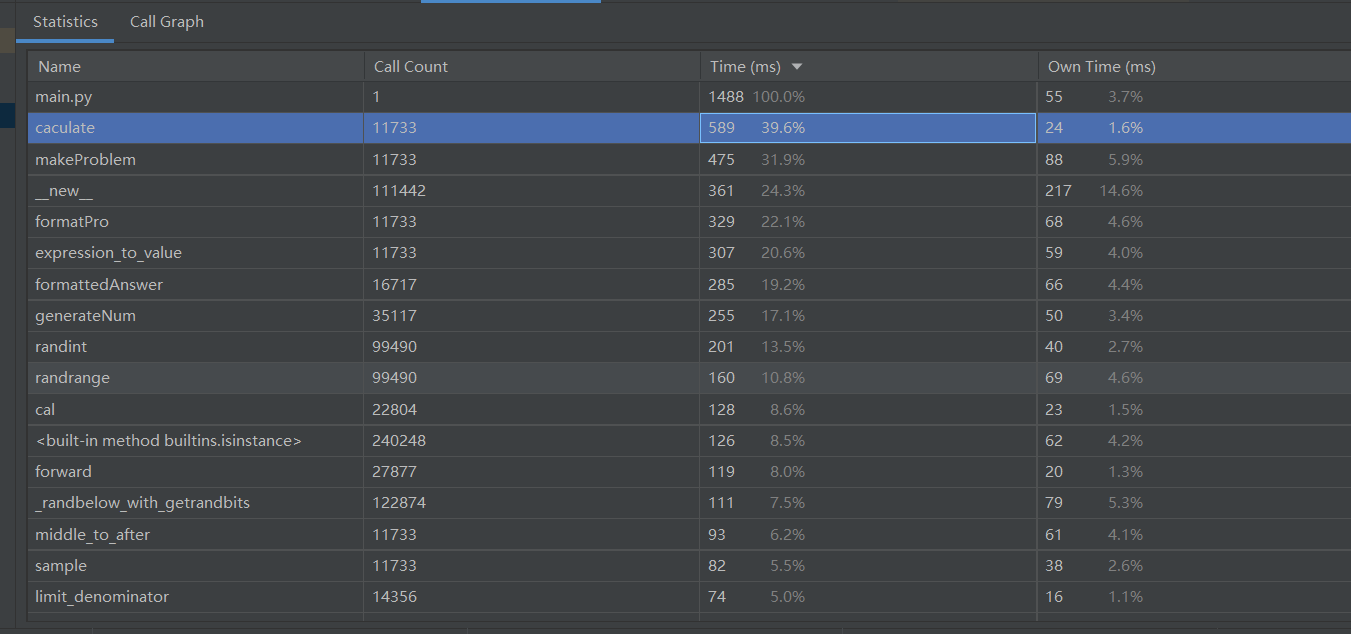
消耗最大的函数是caculate(),这个函数的作用是计算生成问题的答案。因为设计到另外两个子函数的调用,而且使用了大量的判断和计算,所以消耗的时间是最大的。
还有一个重要的原因,在本次项目的需求中,不能出现负数,在这里我们的方法是,在计算函数运行的过程中,一旦出现负数或者除数为0的情况就把对象myPro的isValid属性设为False,后面增加一个检测,如果该属性为false则重新计算题目和答案,从这个图上可以看出,虽然要求生成1w道题目,但实际上是循环了11733次才得到的,说明其它1733次生成的算式都是无效的,这个方法如果能够进行改进的话相信这个程序的性能会更好,开销会更小。
| 类名/函数名 | 类中的函数名 | 类/函数的功能 |
|---|---|---|
| Problem | makeProblem(),caculate(),expression_to_value(),cal() | 主要存储题目和答案 |
| generateNum() | 按相同的概率随机生成正整数/带分数/假分数 | |
| middle_to_after() | 把中继表达式转换成逆波兰表达式 | |
| formattedAnswer() | 把答案进行格式化输出 | |
| formatPro() | 把问题进行格式化输出 | |
| expression_to_value() | 通过逆波兰表达式计算结果 |
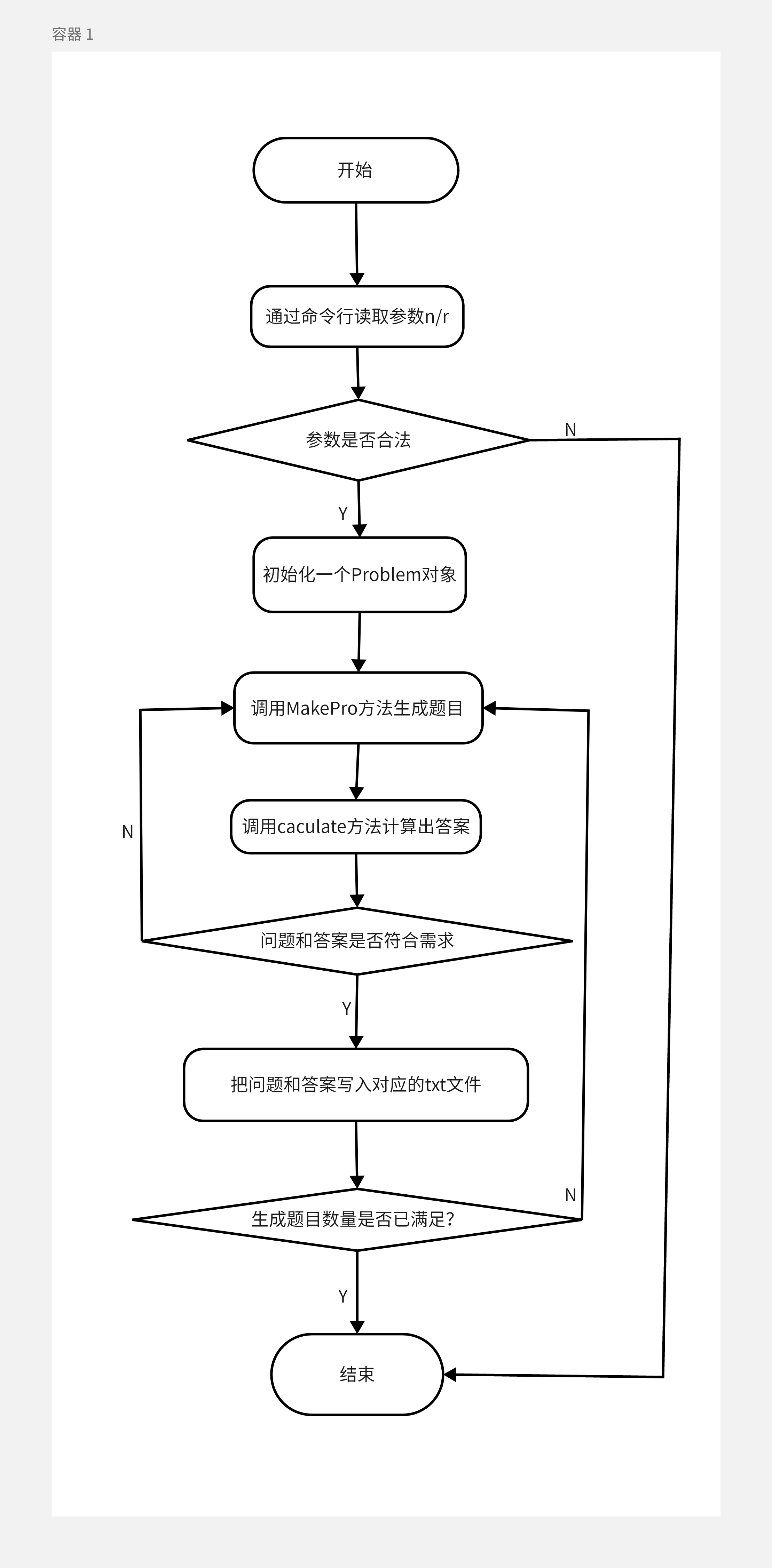
def makeProblem(self):
# 随机数字的个数
numbers = random.randint(2, 4)
# print('这个题目里有%d个数字' % numbers)
numList = []
for i in range(0, numbers):
numList.append(generateNum(self.maxNumber))
# print('这些数字是:', numList)
# 运算符号的个数等于随机数字个数减一
sign = numbers - 1
# print('这个题目里有%d个运算符号' % sign)
signList = ['+', '-', '*', '÷','+','*']
selectedSign = random.sample(signList, sign)
# print("这个运算符号是:", selectedSign)
problem = ' '
for a in range(0, len(selectedSign)):
problem = problem + str(numList[a]) + ' ' + selectedSign[a] + ' '
problem = problem + str(numList[len(numList) - 1])
# print('我生成的问题是:',problem)
self.description = problem
# 生成之后类似:self.description = '1+2÷4。'
函数说明:这个函数的作用是为了生成一个问题(以string返回),一个问题由n个数字和n-1个符号组成。由需求可知n在2-4之间,由随机数生成。generateNum是该函数调用的子函数,子函数的作用是以同等概率返回一个正整数、真分数和带分数。利用n的值来控制循环,以得到一个长度为n的list1,存储数据;一个长度为n-1的list2,存储符号;最后再把这两个元组用for循环读出来再连接在一起得到最后的结果并赋值给对象Pro的属性description。这个函数以及它的子函数调用了很多次random库里的函数,作用是为了随机得到数字/符号。
def middle_to_after(s):
"""
中缀表达式转化后缀表达式.
:param s: 中缀表达式的字符串表示,本程序中采用操作符跟数值之间用空格分开,例如:
"9 + ( 3 - 1 ) * 3 + 10 / 2"
:return: 后缀表达式,数组的形式,每个数值或者操作符占一个数组下标.
"""
expression = []
ops = []
ss = s.split(' ')
for item in ss:
if item in ['+', '-', '*', '÷']: # 操作符
while len(ops) >= 0:
if len(ops) == 0:
# 此时操作符栈里没有其他的运算符号,这是第一个运算符号,入栈
ops.append(item)
break
op = ops.pop()
if op == '(' or ops_rule[item] > ops_rule[op]:
# 比较要入栈的运算符号和当前栈顶元素的优先级
ops.append(op)
ops.append(item)
break
else:
expression.append(op)
elif item == '(': # 左括号,直接入操作符栈
ops.append(item)
elif item == ')': # 右括号,循环出栈道
while len(ops) > 0:
op = ops.pop()
if op == '(':
break
else:
expression.append(op)
else:
expression.append(item) # 数值,直接入表达式栈
while len(ops) > 0:
expression.append(ops.pop())
# print('现在的后继表达式', expression)
return expression
转换的目的是为了便于计算出最后的结果,转换的原理如下:
首先需要分配2个栈,一个作为临时存储运算符的栈S1(含一个结束符号),一个作为存放结果(逆波兰式)的栈S2(空栈),S1栈可先放入优先级最低的运算符#,注意,中缀式应以此最低优先级的运算符结束。可指定其他字符,不一定非#不可。从中缀式的左端开始取字符,逐序进行如下步骤:
(1)若取出的字符是操作数,则分析出完整的运算数,该操作数直接送入S2栈。
(2)若取出的字符是运算符,则将该运算符与S1栈栈顶元素比较,如果该运算符(不包括括号运算符)优先级高于S1栈栈顶运算符(包括左括号)优先级,则将该运算符进S1栈,否则,将S1栈的栈顶运算符弹出,送入S2栈中,直至S1栈栈顶运算符(包括左括号)低于(不包括等于)该运算符优先级时停止弹出运算符,最后将该运算符送入S1栈。
(3)若取出的字符是“(”,则直接送入S1栈顶。
(4)若取出的字符是“)”,则将距离S1栈栈顶最近的“(”之间的运算符,逐个出栈,依次送入S2栈,此时抛弃“(”。
(5)重复上面的1~4步,直至处理完所有的输入字符。
(6)若取出的字符是“#”,则将S1栈内所有运算符(不包括“#”),逐个出栈,依次送入S2栈。
# 把问题进行格式化输出
def formatPro(question):
# 把问题分开 得到一个list
ques = question.split(' ')
# 这个循环把list里的假分数换成带分数
for i in range(0,len(ques)):
if ('/' in ques[i]):
# 把字符串转换成分数
ques[i] = Fraction(ques[i])
# 判断这个分数是不是假分数
if (ques[i] > 1):
ques[i] = formattedAnswer(ques[i])
#只要是分数 全部转化成 字符串 这里是为了拼接
ques[i] = str(ques[i]) + ' '
formatted = ''.join(ques)
finalFormatted = formatted + '='
return finalFormatted
# 把假分数换成带分数 对答案进行格式化
def formattedAnswer(answer):
finalAnswer = answer
#答案是浮点数
if (isinstance(finalAnswer, float)):
if (finalAnswer.is_integer()):
# 答案是诸如20.0 30.0的数 把.0去掉
finalAnswer = int(answer)
else:
#答案是诸如3.2 5.6的数 转化成分数
finalAnswer = Fraction(answer).limit_denominator(100)
#答案是假分数
if (finalAnswer > 1):
if(isinstance(finalAnswer,Fraction) and (finalAnswer.denominator != 1)):
int1 = int(answer)
# decimal = round(answer - int1,3)
decimal = Fraction(answer-int1).limit_denominator(100)
finalAnswer = str(int1) + "'" + str(decimal)
return finalAnswer
如注释,因为在前面的MakePro函数和计算结果函数中,利用了python自带的一个fraction库,这个库中的Fraction模块专门用于处理分数。我们刚开始有两种思路,一是先把真分数和假分数统一为小数进行计算,最后再转化成分数,二是一开始就用分数进行计算。经过网上学习后发现了这个现成自带的库,于是决定采用这个库来进行对分数的处理。但是这里就涉及到很多痛苦的类型转换的问题。这里要吐槽一下python的数据在使用时不规定数据类型,存在很多的隐式转换问题。在最后调试过程中,感觉在计算结果以及格式化输出的时候,总是会遇到Fraction类和string类跳来跳去,导致bug一个接一个,还是c比较严谨。
parser = argparse.ArgumentParser(description='Read the following instructions.')
#输入默认是str类型的
# 可选参数 生成题目数量 默认生成100道
parser.add_argument('-n',help="输入生成题目数量(可选1~10000)",type=int,default=10000)
# 必选参数 题目的数值范围
parser.add_argument("-r",help="输入数值最大值(>0,必选)",type=float,required=True,default=20)
args = parser.parse_args()
if(args.r < 0):
print('数值最大值(-r)为正值。请重新输入')
sys.exit()
if(args.n <0 or args.n>10000):
print('题目数量(-n)为正值且不大于10000,请重新输入。')
sys.exit()
这个库在上一次的论文查重作业已经使用过了,所以比较轻车熟路。简而言之就是要控制用户的输入,并且对参数的范围进行约束并进行提示。其中-r是必选参数。
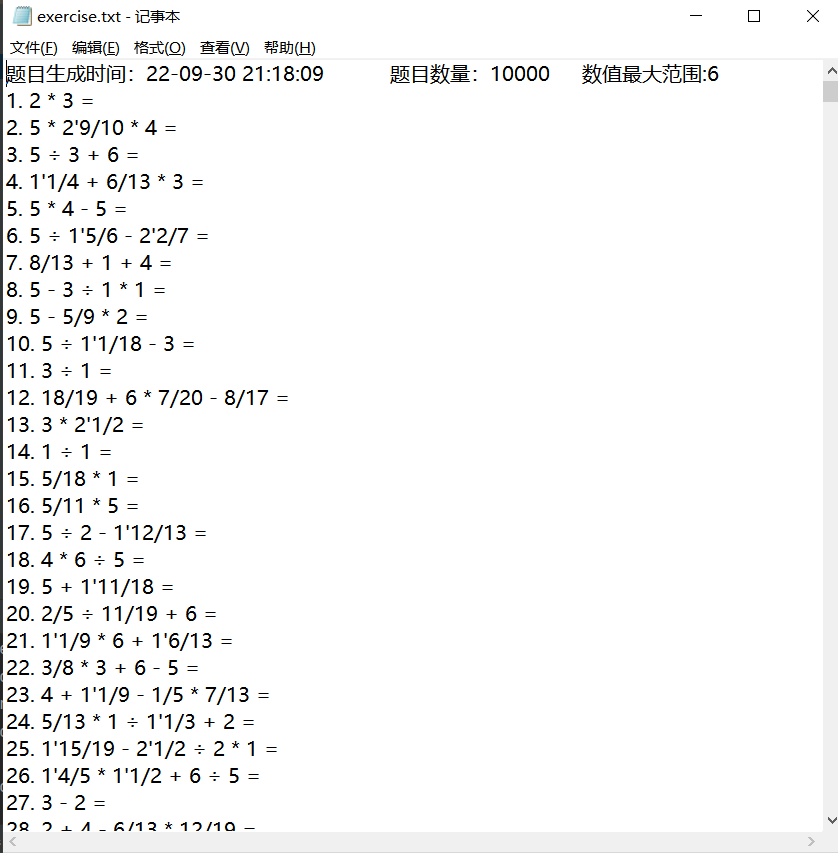
with open(file = 'exercise.txt',mode = 'w',encoding='utf-8') as f1:
with open(file = 'answer.txt',mode='w',encoding='utf-8') as f2:
NowOnTxt = datetime.strftime(datetime.now(), '%y-%m-%d %H:%M:%S')
time = str(NowOnTxt)
f1.write("题目生成时间:%s\t题目数量:%d\t数值最大范围:%d\n"%(time,numuberOfPro,rangeOfNum))
f2.write("答案生成时间:%s\t题目数量:%d\t数值最大范围:%d\n" %(time,numuberOfPro,rangeOfNum))
for i in range(0,numuberOfPro):
mypro.makeProblem()
mypro.caculate()
mypro.description = formatPro(mypro.description)
while (mypro.isValid == False):
'''初始化实例的时候.isValid默认是True 调用makeP和caculate后再判断isValid是否为True 如果是说明这个算式符合要求,
如果不是要重新调用这两个方法'''
mypro.isValid = True
mypro.makeProblem()
mypro.caculate()
mypro.description = formatPro(mypro.description)
pro = str(i+1) + '. ' + mypro.description + '\n'
f1.write(pro)
ans = str(i+1) + '. ' + str(mypro.answer) + '\n'
f2.write(ans)
这个也就是简单的文件输入输出内容,没什么特别之处。可圈可点的地方是我借鉴了上次的经验,在生成的txt文件开头都增加了时间和数量,有利于进行后续处理和两份文件的比对。



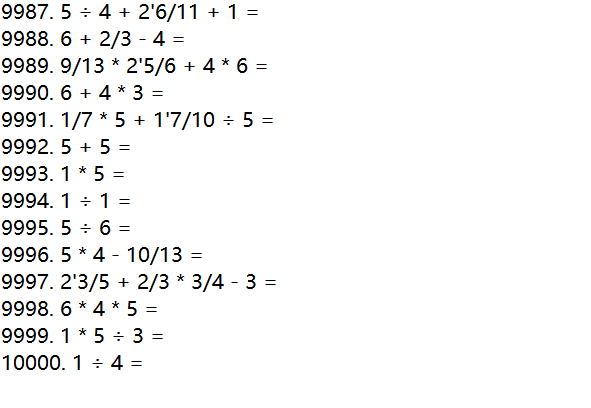


这次结对编程作业让我学到了很多,首先是很多python库的运用,比如说专门对分数进行处理的库Fraction,还有生成随机的random库。其次是对python语言的进一步语法的了解,例如说就参数输入而言,除非在add_argument方法里指定读入的参数,否则统一存储为str常量,又比如在函数传递里,与c传递的是地址不同,python传递的是值,如果要传入一个对象,并在函数里改变对象的属性,只能是说进行deepcopy,当然由于赶着完成任务这部分的学习我还不是很深入。另,模块化的设计,还有高内聚低耦合的设计原则,也很重要。在这次编码过程中,也引起了我的一些思考。比如说:定义类里的函数,和单独定义一个函数,在时间和空间上,哪个性能更优?总而言之,虽然这份报告我们呈现出来还有很多不足的地方,也让我更深刻的理解到”纸上得来终觉浅,绝知此事要躬行”。相信以后我们会做得更好。(林秀霞)
在这次的结对合作中,任务主要是需求分析,代码设计,编码,测试以及博客撰写。在秀霞同学的帮助下顺利完成此次项目,同时也发现了自己的不足之处,往后一定要加强代码方面的能力,建立自己的知识体系,不断尝试和实践,多做项目。当然,在此次的项目合作中也加强了我的沟通能力巩固了编码知识,对于我来说是一次宝贵的经历。(覃琬淇)
