



332
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Curve 是云原生计算基金会 (CNCF) Sandbox 项目,是网易主导自研和开源的高性能、易运维、云原生的分布式存储系统,由块存储 CurveBS 和文件系统 CurveFS 两部分组成。
在版本开发过程中,避免不了出现各种各样的问题。同时,问题出现的地方往往可能会缺乏日志和监控等关键信息。对于这些问题,通常的做法是添加必要的日志、监控,然后重新进行复现。这样的流程,延缓了故障定位修复的进度。为了规避这一问题,Curve 引入了一些故障定位的可观测性工具和方法。下面对 bpftrace 进行简要的介绍,以及使用中的实践总结。
bpftrace 是基于 Linux 内核 eBPF 的高级跟踪语言,利用 BCC 与内核 BPF 系统进行交互,同时也可以利用内核现有的跟踪功能:kernel/user-level dynamic tracing、tracepoints 等。语法类似于 awk 和 C,提供了丰富的功能,可以协助分析程序行为、性能瓶颈以及故障定位等。
bpftrace 基础用法
下面以一个简单的例子,介绍 bpftrace 的基础用法:
#!/usr/bin/env bpftracekprobe:vfs_read {@start[tid] = nsecs;}kretprobe:vfs_read / @start[tid] / {@ns = hist(nsecs - @start[tid]);delete(@start[tid]);}interval:s:3 {print(@ns);clear(@ns);}END {clear(@ns);clear(@start);}
这个脚本用于统计 read 系统调用的延迟,并以直方图的形式显示结果。
脚本第 3 行的 kprobe:vfs_read 表示对内核中的 vfs_read 进行探测,在调用该函数时,会执行花括号中的 actions。这里是记录了一个时间戳,tid、 nsecs 是 bpftrace 内置的变量,分别对应 thread id 和当前的纳秒级别的时间戳。@start[tid] 定义了一个名为 start 的 map,key 是 thread id,value 为时间戳。
第 5 行的 kretprobe:vfs_read 表示在 vfs_read 调用返回处进行探测,在函数返回时,执行相应的 actions。花括号前的 / @start[tid] / 是一个过滤器,表示只有在 @start[tid] 有记录时,才执行后续的 actions。这里定义了一个名为 @ns 的变量,记录的是 hist(nsecs - @start[tid]) 的返回结果。hist 是内置函数,将延迟以对数直方图的形式保存。delete(@start[tid]) 用于删除对应的记录。
第 12 行 interval:s:3 是一个定时器,表示每 3 秒执行一次。这里是把 @ns 中记录的延迟打印到控制台,然后 clear(@ns) 清楚所有的记录。
END 表示在最终结束时,比如 Ctrl+C 退出时执行。
将上面的脚本保存为 vfs_read_latency.bt,然后以 root 权限执行 bpftrace vfs_read_latency.bt ,或给予可执行权限后 ./vfs_read_latency.bt 可以看到如下的输出结果:
Attaching 4 probes...@ns:[512, 1K) 297 |@@@@@ |[1K, 2K) 3007 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|[2K, 4K) 834 |@@@@@@@@@@@@@@ |[4K, 8K) 58 |@ |[8K, 16K) 13 | |[16K, 32K) 12 | |[32K, 64K) 2511 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |[64K, 128K) 364 |@@@@@@ |[128K, 256K) 976 |@@@@@@@@@@@@@@@@ |[256K, 512K) 1 | |@ns:[256, 512) 70 | |[512, 1K) 365 |@@@@@ |[1K, 2K) 3645 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|[2K, 4K) 371 |@@@@@ |[4K, 8K) 89 |@ |[8K, 16K) 106 |@ |[16K, 32K) 45 | |[32K, 64K) 2330 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |[64K, 128K) 439 |@@@@@@ |[128K, 256K) 996 |@@@@@@@@@@@@@@ |[256K, 512K) 5 | |
@ns 后面就是每 3 秒的输出结果,第一列是延迟的范围,[512, 1K) 表示延迟在 512ns 到 1ms 之间。后面分别是在这个延迟范围内的请求的个数,以及对应的直方图显示。
更详细使用说明,请参考官方文档:bpftrace.adoc [1]、reference_guide [2]
动态追踪 kprobes/uprobes 的工作方式
使用 kprobe 对内核进行动态探测的过程如下:
1. kprobe 注册时,会保存并替换被探测的指令(在 x86_64 上替换为 int3)。
2. 当 CPU 执行到断点时,断点处理函数会将控制权转交给 Kprobes,并执行与当前探测点相关的 pre_hander
3. Kprobes 会单步执行被探测的指令,然后执行与当前探测点相关的 post_handler
4. 继续执行被探测点之后的指令
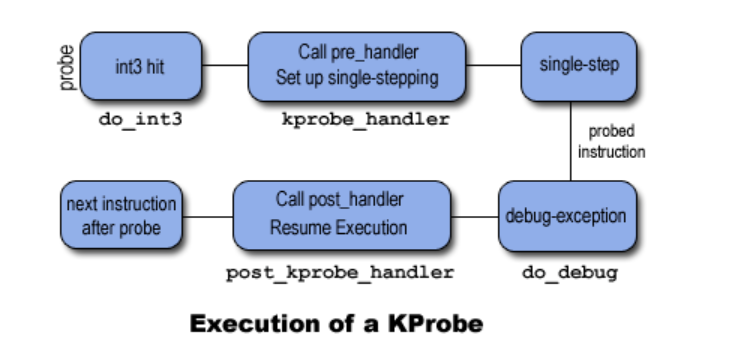
kretprobe 的过程比较类似,在注册 kretprobe 时,会在函数入口处建立一个 kprobe。当函数被调用命中 kprobe 时,会保存原有的函数返回地址,并替换为” 蹦床 “(trampoline)函数的地址。在函数调用返回时,控制权交给 trampoline,kretprobe 处理完成后,再次返回到之前被替换的地址。
下面讲解 uprobe 探测前后的指令变化:
#include <stdio.h>__attribute__((noinline)) void hello() {printf("hello, world\n");}int main() {getchar();hello();return 0;}
#!/usr/bin/env bpftraceuprobe:./a.out:hello {printf("Hello\n");}
在探测前,hello 函数的汇编指令如下:
(gdb) disass helloDump of assembler code for function hello:0x00005630e9dbd145 <+0>: push %rbp0x00005630e9dbd146 <+1>: mov %rsp,%rbp0x00005630e9dbd149 <+4>: lea 0xeb4(%rip),%rdi # 0x5630e9dbe0040x00005630e9dbd150 <+11>: callq 0x5630e9dbd030 <puts@plt>0x00005630e9dbd155 <+16>: nop0x00005630e9dbd156 <+17>: pop %rbp0x00005630e9dbd157 <+18>: retqEnd of assembler dump.
探测后的指令如下:
(gdb) disass helloDump of assembler code for function hello:0x00005630e9dbd145 <+0>: int30x00005630e9dbd146 <+1>: mov %rsp,%rbp0x00005630e9dbd149 <+4>: lea 0xeb4(%rip),%rdi # 0x5630e9dbe0040x00005630e9dbd150 <+11>: callq 0x5630e9dbd030 <puts@plt>0x00005630e9dbd155 <+16>: nop0x00005630e9dbd156 <+17>: pop %rbp0x00005630e9dbd157 <+18>: retqEnd of assembler dump.
在探测 C 程序时,需要探测的函数名称,就是代码中对应的函数名。对于一些简单的 C++ 函数,这种方式也是可行的,即便存在函数重载(bpftrace v0.10.0 以上版本支持)。例如:
#include <iostream>void hello() {std::cout << __PRETTY_FUNCTION__ << std::endl;}void hello(int i) {std::cout << __PRETTY_FUNCTION__ << std::endl;}void hello(std::string name) {std::cout << __PRETTY_FUNCTION__ << std::endl;}int main() {hello();hello(1);hello("curve");return 0;}
$ bpftrace -e 'uprobe:./a.out:hello { printf("hello\n"); }'Attaching 3 probes...
这里的表示对 3 个函数添加了探测。但如果代码中存在自定义类型、命名空间,或者需要探测成员函数时,上面的方式使用起来就会比较麻烦。此时,直接对函数重整后的名字进行探测会比较方便。
在 C++ 代码编译的过程中,会对函数名连同其参数、命名空间等进行一次名字重整(name mangling),使得不同的重载函数有不同的符号。
以上面的 demo 为例,使用 GCC 以 C 语言编译时,函数名称不会发生变化,
$ readelf -s a.out | grep hello57: 0000000000001145 19 FUNC GLOBAL DEFAULT 14 hello
当以 C++ 语言进行编译时,hello 就被修改为 _Z5hellov
$ readelf -s a.out | grep hello67: 0000000000001145 19 FUNC GLOBAL DEFAULT 14 _Z5hellov
在进行重载后,也会有不同的符号:
void hello(); -> _Z5hellovvoid hello(int a); -> _Z5helloivoid hello(double a); -> _Z5hellodvoid hello(std::string name); -> _Z5helloNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE
所以,我们需要找到重整后对应的符号,这里会用到两个工具 nm 和 c++filt,nm 是列出可执行文件或动态链接库中的符号,c++filt 可以恢复命名重整前的函数签名。以下为例:
#include <iostream>namespace curve {struct Demo {void hello(std::string name) {std::cout << "hello, " << name << std::endl;}};}int main() {curve::Demo demo;demo.hello("curve");return 0;}
首先,使用 nm 列出可执行文件中的所有符号,然后用 grep 过滤出对应的函数。其次,可以使用 c++filt 将符号转换为函数对应的签名。
$ nm a.out | grep Demo | grep hello # 查找重整后的符号00000000000012b4 W _ZN5curve4Demo5helloENSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE$ c++filt 00000000000012b4 W _ZN5curve4Demo5helloENSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE # 确认重整前的函数签名 curve::Demo::hello(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)$ bpftrace -e 'uprobe:./a.out:_ZN5curve4Demo5helloENSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE { printf("hello\n"); }'Attaching 1 probe...
Curve 文件存储目前使用 CurveAdm 进行容器化部署,所有的服务都运行在容器中,方便进行部署和运维操作。但是,也给使用 bpftrace 探测容器中运行的服务带来了一些问题。
前面讲到,在探测用户态进行时,需要指定可执行文件或者动态链接库的物理路径。由于容器中的环境与宿主机环境是相互隔离的,直接使用可执行文件在容器内的路径是不可行的。
一种方式是利用 docker inspect 命令查看对应容器的 MergedDir 在宿主机上的路径,然后把可执行文件在容器内的路径拼接到一起。例如,需要探测容器内 curve-fuse 进程中的 FuseOpWrite 函数,步骤如下:
$ docker inspect af19f9940 | grep "MergedDir""MergedDir": "/var/lib/docker/overlay2/32581ea24889ab2de49569e2c00c6d6f95cd9cc7016afcfbcfb7701e478681dd/merged",$ bpftrace -e 'uprobe:/var/lib/docker/overlay2/32581ea24889ab2de49569e2c00c6d6f95cd9cc7016afcfbcfb7701e478681dd/merged/curvefs/client/sbin/curve-fuse:FuseOpWrite { printf("probe FuseOpWrite\n"); }'Attaching 1 probe...probe FuseOpWrite
另一种方式是,利用 docker inspect 查看容器的 pid,/proc/${pid}/root 对应的就是上面的 MergedDir,
$ docker inspect af19f9940 | grep -m1 "Pid""Pid": 753858,$ cd /proc/753858/root$ df .Filesystem 1K-blocks Used Available Use% Mounted onoverlay 1135634272 1040824488 37052960 97% /var/lib/docker/overlay2/32581ea24889ab2de49569e2c00c6d6f95cd9cc7016afcfbcfb7701e478681dd/merged$ bpftrace -e 'uprobe:/proc/753858/root/curvefs/client/sbin/curve-fuse:FuseOpWrite { printf("probe FuseOpWrite\n"); }'Attaching 1 probe...probe FuseOpWrite
如果要在容器内直接运行 bpftrace,就不需要上述的步骤,但是需要在容器运行时,授予一些权限。
具体可以参考:How to: run BpfTrace from a small alpine image, with least privileges. [3]
本文简单介绍了 bpftrace 的基本用法,以及探测 C++ 程序和容器中运行进程的方法。通过 bpftrace 动态追踪的能力,能够协助我们分析运行中进程的行为,加快了问题定位的进度。在实际的问题定位过程中,往往需要结合使用多种工具,例如,先通过日志、监控等缩小问题的范围,然后利用 bpftrace 对关键函数进行动态追踪,从而确定问题的根源。
参考:
[1] https://github.com/iovisor/bpftrace/blob/master/man/adoc/bpftrace.adoc
[2] https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
[3] https://itnext.io/how-to-run-bpftrace-from-a-small-alpine-image-and-with-least-privileges-379146fcfcf1?gi=e7f8d5499eb4
原创作者:吴汉卿,Curve Contributor
