172
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | Fzusdn |
|---|---|
| 这个作业要求在哪里 | 2020秋软工实践 第二次结对编程作业 |
| 这个作业的目标 | 设计点名算法 |
| 学号 | 032004134,032004135 |
栋哥急需大家设计一个算法来解决这个问题,要求能够最小化向后端发送的请求次数,最大化抓出缺勤同学的数量。
定义5门课程,每个课程班级人数为90人,一学期共20次课。每门课程均有5-8位同学缺席了该学期80%的课,此外每次课程均还有0-3位同学由于各种原因缺席。
请求次数:定义在一次点名中,获取一位同学是否到达课堂的情况为一次请求。
有效点名:一位同学缺席该课程的一次课,算法在这次课上抽点到该同学,视为一次有效点名,一次课可包含多次有效点名。
尽可能使E最大化
问题的输入是五门课程的全部人员的到勤信息,而依据问题要求去生成五门课程的全部人员到勤信息,如何随机地去分配五门课程的全部人员到勤信息,是问题的难点。
评价的标准是尽可能使E最大化,全点的方式,后端服务器需要处理大量的请求,影响用户的使用体验。抽点的方式,能够有效减少并发量,但无法保证点名的质量。设计一个算法尽可能使得五门课程有效点名次数与总请求次数的比值最大化,算法实现的难点在于如何寻找请求次数和有效点名次数之间的动态平衡。
最开始我们想到的是用概率模型去解决问题,假设每节课程的缺勤率为p,仿照求解最高效的核酸检测混检人数的模型,求解如何抽点,得到最高值E。
再后面,我们想到的是用KNN算法去解决问题。KNN(K-NearesNeighbor) 即K邻近法,是一个理论上比较成熟的、也是最简单的机器学习算法之一。一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。也就是说,该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关。可以用KNN去训练程序生成的到勤情况数据集,再用测试集去测试结果精度。
最终我们确认使用KNN算法去求解该问题。
每节课程的缺勤率p是一个无法固定的数,无法使用固定值去确定它。求解最高效的核酸检测混检人数的模型,核酸检测能够多人混检。而点名不能实现把多人看做一个集体一起点名,所以只能摒弃了概率模型,选择KNN算法。
逃课的同学一般都是有一定的特征的,比如说绩点低,一门课80%的课都不去等等,所以我们用KNN模型来估计数据之间的相似性,利用与待测数据特征相似的邻居来判断待测数据是否会逃课,以此来选取点名对象
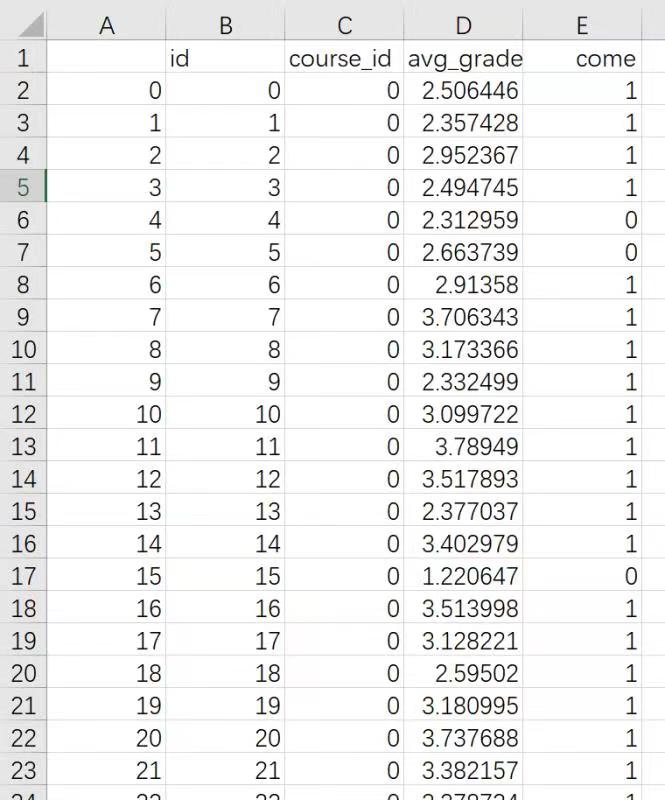
数据集包含了、学生id(用来唯一识别一名学生)、平均绩点、课程名、到勤情况(到为0,没到为1)
其中每门课程均有5-8位同学缺席了该学期80%的课,此外每次课程均还有0-3位同学由于各种原因缺席。
并且认为,绩点低于2.5的同学是会比较爱逃课的
生成的步骤为:
- 记录所有人的课程id为该课程的id
- 生成生成所有人的绩点,绩点符合正态分布,值域为[1,4],并记录绩点小于2.5的同学
- 先记录所有人为到
- 对于每门课,在绩点小于2.5的同学中生成5-8名其那部分80%的课不去的同学,标及其到勤情况为未到
- 然后再随机在其他同学中,在随机挑选出0-3个同学,标记其为未到
生成的数据集如下:
算法分为 三个模块
对输入的数据进行预处理,然后作为预测算法的出入
- 对数据集进行统计,统计每位学生的每门课的缺勤率,和所有课总的缺勤率
- 对数据集进行归一化
对数据进行预测
采用KNN算法,对每条数据,寻找与其最相近的k个邻居,根据邻居的标签来投票表决该条数据的预测结果为到(1)还是没到(0),把被预测为0的同学作为点名对象,最后输出点名结果
评估性能
根据评估标准E来对算法进行评估,最后输出score
KNN算法使用sklearn库中的类KNeighborsClassifier实现,可以做到O(1)输入,O(1)输出。
数据使用的数据结构是panda库的DataFrame类,其可方便的进行统计,合并,输入,输出等操作。
最后对以上的类进行简单的封装,即可使用。
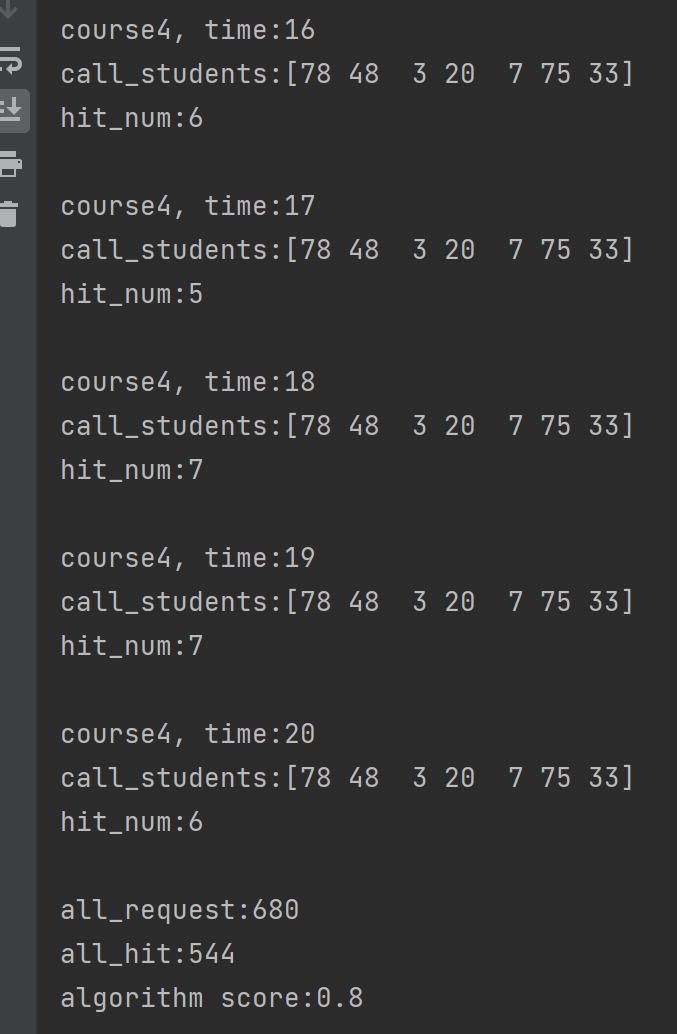
** score的结果如下 **
- 生成算法模块化:生成算法中涉及的类和方法都放在了attendance_table.py中,在该模块中实现了数据生成器的初始化,点名表的生成与获取,点名表的持久化存储, 点名表的统计。
- 点名算法模块化:点名算法中涉及的类和方法都放在了calling_algorithm.py中,在该模块中,实现了算法的初始化,算法的获取,点名方案的生成,数据的预处理。
编码时产考了python的开发规范
git commit时产考了commit的规范
如图
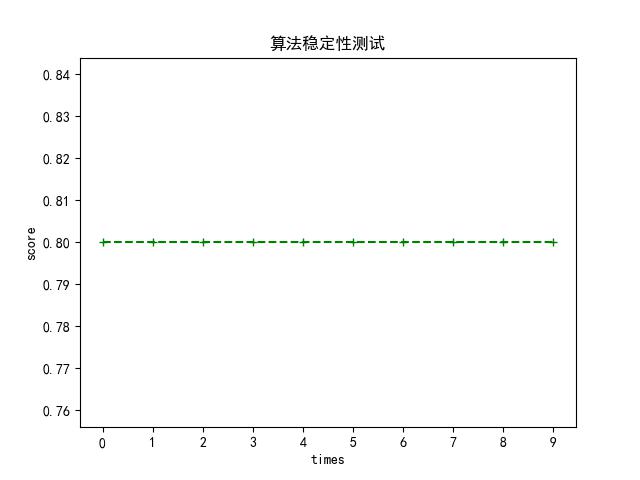
- E的值稳定在0.8左右,具有较强的稳定性,并且E的值相对较大。
| Personal Software Process tags | 预估耗时/分钟 | 实际耗时/分钟 |
|---|---|---|
| Planning(计划) | 120 | 120 |
| Estimate(估计时间) | 40 | 45 |
| Development(开发) | 1280 | 1430 |
| Analysis(需求分析) | 60 | 60 |
| Design Review(设计复审) | 80 | 80 |
| Coding Standard(代码规范 ) | 60 | 60 |
| Design(具体设计) | 120 | 120 |
| Coding(具体编码) | 800 | 900 |
| Code Review(代码复审) | 120 | 150 |
| Test(测试(自我测试,修改代码,提交修改)) | 40 | 60 |
| Size Measurement(计算工作量) | 20 | 40 |
| Postmortem & Process Improvement Plan(事后总结, 并提出过程改进计划) | 30 | 30 |
| Total(合计) | 1490 | 1640 |
| 周数 | 完成的任务 |
|---|---|
| 一 | 对问题进行分析,敲定具体的实现算法 |
| 二 | 学习实现算法需要用到的库,pandas,numpy,random等 |
| 三 | 编写代码及其复审 |
再次两人共同完成一项作业,如果将这项作业分发给个人来完成的话,工期将会相应的延长很长一段时间,两个人的相互配合,极大地缩短了工期。
一开始两个人所提出的模型各不相同,一个提出依据概率模型去解答,一个提出可以根据KNN算法去解决问题,两个人的观点不一,相互学习彼此的观点,站在对方的角度去考虑问题,最终也是顺利地解决了问题。
在两个人合作共同完成一项任务的过程中,每个人都会有自己的看法,有时候意见不合,双方都愿意做出让步的话,能够极大地加快项目的进程。
双方对于这个问题都有不同的见解,并可以建立出不同的模型,双方彼此互相学习,下次看待类似的问题时,能从不同的角度去看待问题,用不同的方法去解决问题。
对于模型的再次复盘,让我们重新更新了绩点这一评判标准以及对绩点如何分配,如何使用的一个重新定义。
以及对于数据集的使用,模型建立后,起初我们并不知道如何更好地去运用数据集,再次复盘后,发现可以将数据集拆分为训练集和测试集来使用。
一起工作时的照片

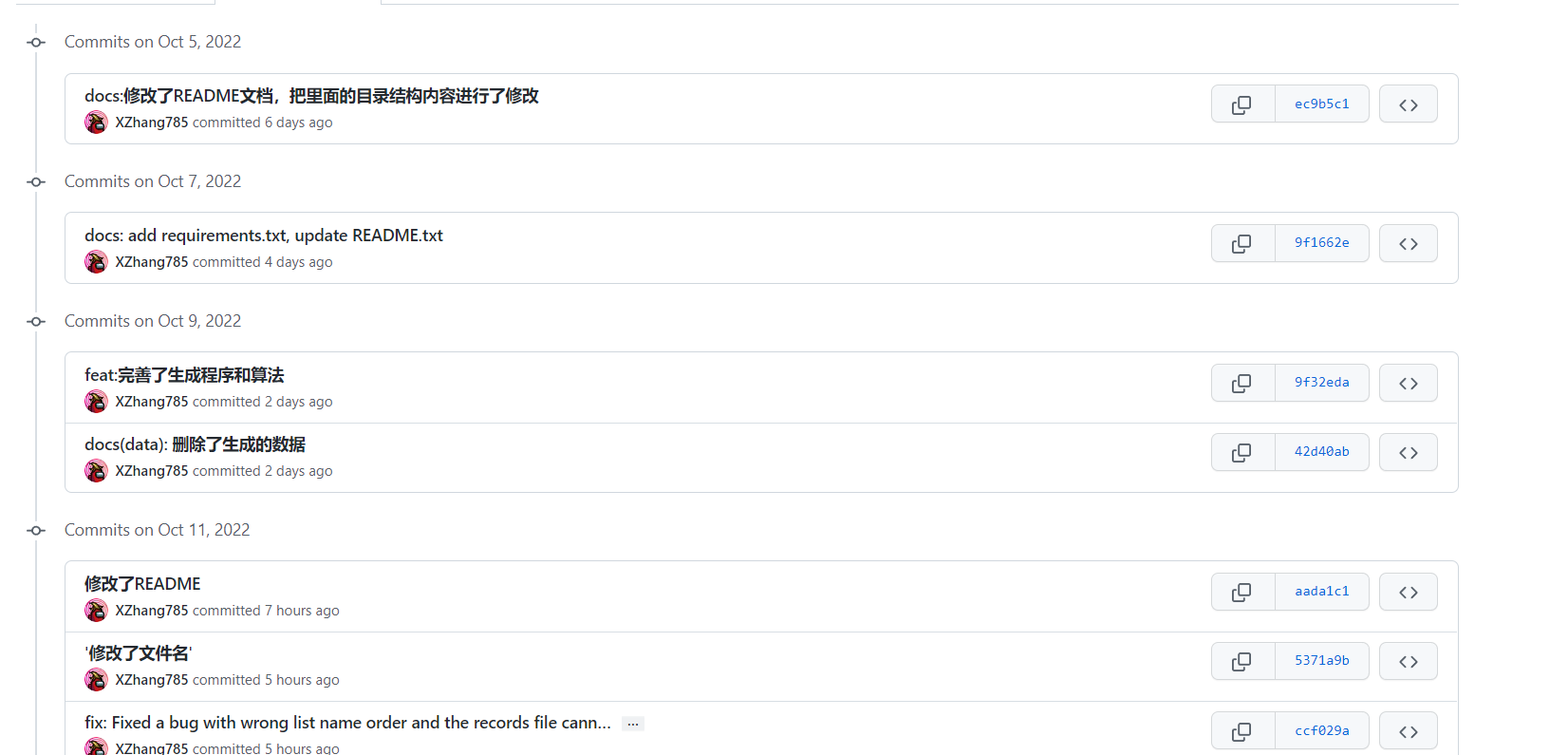
Github仓库和commit记录
Github仓库