


123
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享1.概述:
我有3000万个节点,8000万个边的关系。
节点标签分类有5类,并不均匀,有一类就多达2000多万。
8000多万边,主要分两类,一个快8000多万,一个1万多边。
neo4j版本是社区版4.4.6,操作系统是ubuntu 20.04,内存128G。
database size 33G,dbms.memory.pagecache.size=81g,dbms.memory.heap.max_size=32g,dbms.memory.heap.initial_size=32g。
现在想实现在全图遍历,使用apoc.path.expandConfig或者gds.dfs.stream去实现深度优先遍历或者广度优先遍历的时候,总是查询长时间未返回结果直到失去neo4j链接。
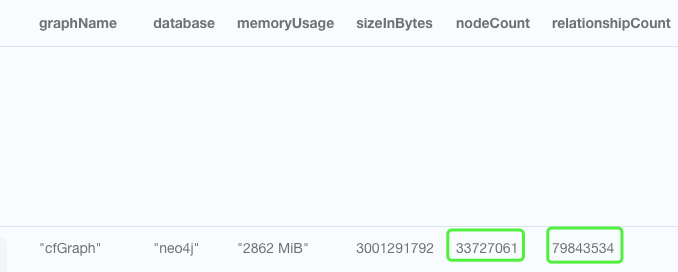
2.索引:
加在Compound的 propery上,字符串格式。
3.Cypher语句
MATCH(p:Compound{property:"value1"})
MATCH (joe:Compound{property:"value2"})
CALL gds.shortestPath.yens.stream("cfGraph",
{sourceNode: source,targetNode: target,k: 3,relationshipWeightProperty: "score"})
YIELD index,totalCost,path
RETURN index,totalCost,length(path),relationships(path) as
relationships,nodes(path) as nodes ORDER BY index
MATCH(p:Compound{property:"value1"})
MATCH (joe:Compound{property:"value2"})
CALL apoc.path.expandConfig(start,
{labelFilter: "*",
minLevel: 1,
Uniqueness:"NODE_GLOBAL",
limit:10,
maxLevel: 4,
bfs: true,
endNodes: [end]})
YIELD path
RETURN path,length(path),relationships(path) as relationships
MATCH(p:Compound{property:"value1"})
MATCH (joe:Compound{property:"value2"})
CALL gds.dfs.stream('cfGraph', {
sourceNode: p,
targetNodes: joe,
maxDepth:4
})
YIELD path
RETURN path
传闻gds.dfs.stream适用4步以上?apoc.path.expandConfig适用4步以下?
现在的问题是在执行某些例子的时候,即使步骤只有4步,或者三步也有可能一直查询不出来,直到neo4j失去连接。
有些涉及到数量集很少的例子或者步骤2步是没有问题的。
4.报错有:
2022-11-16 13:46:15.163+0000 ERROR [o.n.b.t.p.ProtocolHandshaker] Fatal error occurred during protocol handshaking: [id: 0x0867cdc7, L:/172.17.0.2:7687 - R:/172.17.0.1:41420]
java.lang.NullPointerException: null
2022-11-16 13:41:34.179+0000 ERROR [o.n.b.t.p.HouseKeeper] Fatal error occurred when handling a client connection: [id: 0x7968cefc, L:/172.17.0.2:7687 ! R:/172.17.0.1:40356]
org.neo4j.bolt.runtime.BoltConnectionFatality: Terminated connection '[id: 0x7968cefc, L:/172.17.0.2:7687 ! R:/172.17.0.1:40356]' as the server failed to handle an authentication request within 30000 ms.
2022-11-16 13:47:50.842+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=95348, gcTime=95524, gcCount=2}
部分配置:
#********************************************************************
#
# Memory settings are specified kilobytes with the 'k' suffix, megabytes with
# 'm' and gigabytes with 'g'.
# If Neo4j is running on a dedicated server, then it is generally recommended
# to leave about 2-4 gigabytes for the operating system, give the JVM enough
# heap to hold all your transaction state and query context, and then leave the
# rest for the page cache.# Java Heap Size: by default the Java heap size is dynamically calculated based
# on available system resources. Uncomment these lines to set specific initial
# and maximum heap size.
dbms.memory.heap.initial_size=32g
dbms.memory.heap.max_size=32g# The amount of memory to use for mapping the store files.
# The default page cache memory assumes the machine is dedicated to running
# Neo4j, and is heuristically set to 50% of RAM minus the Java heap size.
dbms.memory.pagecache.size=81g# Limit the amount of memory that all of the running transaction can consume.
# By default there is no limit.
#dbms.memory.transaction.global_max_size=1g# Limit the amount of memory that a single transaction can consume.
# By default there is no limit.
dbms.memory.transaction.max_size= 3g# Transaction state location. It is recommended to use ON_HEAP.
dbms.tx_state.memory_allocation=ON_HEAP#********************************************************************
# JVM Parameters
#********************************************************************# G1GC generally strikes a good balance between throughput and tail
# latency, without too much tuning.
dbms.jvm.additional=-XX:+UseG1GC# Have common exceptions keep producing stack traces, so they can be
# debugged regardless of how often logs are rotated.
dbms.jvm.additional=-XX:-OmitStackTraceInFastThrow# Make sure that `initmemory` is not only allocated, but committed to
# the process, before starting the database. This reduces memory
# fragmentation, increasing the effectiveness of transparent huge
# pages. It also reduces the possibility of seeing performance drop
# due to heap-growing GC events, where a decrease in available page
# cache leads to an increase in mean IO response time.
# Try reducing the heap memory, if this flag degrades performance.
dbms.jvm.additional=-XX:+AlwaysPreTouch# Trust that non-static final fields are really final.
# This allows more optimizations and improves overall performance.
# NOTE: Disable this if you use embedded mode, or have extensions or dependencies that may use reflection or
# serialization to change the value of final fields!
dbms.jvm.additional=-XX:+UnlockExperimentalVMOptions
dbms.jvm.additional=-XX:+TrustFinalNonStaticFields# Disable explicit garbage collection, which is occasionally invoked by the JDK itself.
# dbms.jvm.additional=-XX:+DisableExplicitGC#Increase maximum number of nested calls that can be inlined from 9 (default) to 15
dbms.jvm.additional=-XX:MaxInlineLevel=15# Disable biased locking
dbms.jvm.additional=-XX:-UseBiasedLocking# Restrict size of cached JDK buffers to 256 KB
dbms.jvm.additional=-Djdk.nio.maxCachedBufferSize=262144# More efficient buffer allocation in Netty by allowing direct no cleaner buffers.
dbms.jvm.additional=-Dio.netty.tryReflectionSetAccessible=true# Exits JVM on the first occurrence of an out-of-memory error. Its preferable to restart VM in case of out of memory errors.
dbms.jvm.additional=-XX:+ExitOnOutOfMemoryError# Expand Diffie Hellman (DH) key size from default 1024 to 2048 for DH-RSA cipher suites used in server TLS handshakes.
# This is to protect the server from any potential passive eavesdropping.
dbms.jvm.additional=-Djdk.tls.ephemeralDHKeySize=2048
# This mitigates a DDoS vector.
dbms.jvm.additional=-Djdk.tls.rejectClientInitiatedRenegotiation=true# Enable remote debugging
#dbms.jvm.additional=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005# This filter prevents deserialization of arbitrary objects via java object serialization, addressing potential vulnerabilities.
# By default this filter whitelists all neo4j classes, as well as classes from the hazelcast library and the java standard library.
# These defaults should only be modified by expert users!
# For more details (including filter syntax) see: https://openjdk.java.net/jeps/290
#dbms.jvm.additional=-Djdk.serialFilter=java.**;org.neo4j.**;com.neo4j.**;com.hazelcast.**;net.sf.ehcache.Element;com.sun.proxy.*;org.openjdk.jmh.**;!*# Increase the default flight recorder stack sampling depth from 64 to 256, to avoid truncating frames when profiling.
dbms.jvm.additional=-XX:FlightRecorderOptions=stackdepth=256# Allow profilers to sample between safepoints. Without this, sampling profilers may produce less accurate results.
dbms.jvm.additional=-XX:+UnlockDiagnosticVMOptions
dbms.jvm.additional=-XX:+DebugNonSafepoints# Disable logging JMX endpoint.
dbms.jvm.additional=-Dlog4j2.disable.jmx=true# Limit JVM metaspace and code cache to allow garbage collection. Used by cypher for code generation and may grow indefinitely unless constrained.
# Useful for memory constrained environments
# dbms.jvm.additional=-XX:MaxMetaspaceSize=64g
dbms.jvm.additional=-XX:ReservedCodeCacheSize=512m#********************************************************************
5.推荐配置
./neo4j-admin memrec
# Assuming the system is dedicated to running Neo4j and has 125.4GiB of memory,
# we recommend a heap size of around 31500m, and a page cache of around 80800m,
# and that about 16200m is left for the operating system, and the native memory
# needed by Lucene and Netty.
#
# Tip: If the indexing storage use is high, e.g. there are many indexes or most
# data indexed, then it might advantageous to leave more memory for the
# operating system.
#
# Tip: Depending on the workload type you may want to increase the amount
# of off-heap memory available for storing transaction state.
# For instance, in case of large write-intensive transactions
# increasing it can lower GC overhead and thus improve performance.
# On the other hand, if vast majority of transactions are small or read-only
# then you can decrease it and increase page cache instead.
#
# Tip: The more concurrent transactions your workload has and the more updates
# they do, the more heap memory you will need. However, don't allocate more
# than 31g of heap, since this will disable pointer compression, also known as
# "compressed oops", in the JVM and make less effective use of the heap.
#
# Tip: Setting the initial and the max heap size to the same value means the
# JVM will never need to change the heap size. Changing the heap size otherwise
# involves a full GC, which is desirable to avoid.
#
# Based on the above, the following memory settings are recommended:
dbms.memory.heap.initial_size=31500m
dbms.memory.heap.max_size=31500m
dbms.memory.pagecache.size=80800m
#
# It is also recommended turning out-of-memory errors into full crashes,
# instead of allowing a partially crashed database to continue running:
dbms.jvm.additional=-XX:+ExitOnOutOfMemoryError
#
# The numbers below have been derived based on your current databases located at: '/var/lib/neo4j/data/databases'.
# They can be used as an input into more detailed memory analysis.
# Total size of data and native indexes in all databases: 29800m
6.主要问题和诉求
1.Neo4j能否支持大图的深度遍历和广度遍历,如果neo4j社区版不能支持大型图的深度和广度遍历搜索,它的上限是多少节点和边。
2.还是我的语法还可以加以改进或者配置可以改善。
3.或者我的图有一些节点的连接度特别大,陷入了不停地查询。
4.或者Neo4j的apoc.path.expandConfig能否在某一层循环遍历的时候,总共有400个节点要循环,只随机挑选10个。
5.如果本身不能搜索这么大的图,短时间内,能否有一些我目前不太清楚的配置取消该事务的搜索,不导致neo4j崩溃。
6.或者增加内存可否改善此情况!!!
7.gds.dfs.stream和apoc.path.expandConfig的主要区别

请问解决了吗




