


162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本实验将利用python程序抓取网络图片,完成可以批量下载一个网站的照片。所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
8学时。
1、网络爬虫
即Web Spider,网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
网络爬虫的基本操作是抓取网页。
2、浏览网页过程
抓取网页的过程其实和读者平时使用浏览器浏览网页的道理是一样的。打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
URL的格式由三部分组成:
第一部分和第二部分用“://”符号隔开,
第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它 进行进一步的处理。
因此,准确地理解URL对理解网络爬虫至关重要。
3、利用urllib2通过指定的URL抓取网页内容
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口。
4、HTTP的异常处理问题
当urlopen不能够处理一个response时,产生urlError。
不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。
HTTPError是urlError的子类,通常在特定HTTP URLs中产生。
5、Timeout 设置(超时设置)
在Python2.6前,urllib2 的 API 并没有暴露 Timeout 的设置,要设置 Timeout 值,只能更改 Socket 的全局 Timeout 值。在 Python 2.6 以后,超时可以通过 urllib2.urlopen() 的 timeout 参数直接设置。
项目包含两个文件,pet_spider.py和main_file.py。其中pet_spider.py文件定义了类PetSpider,包含3个方法分别是get_html_content下载网页源代码、get_urls获得网页图片urls、 download_images下载图片。main_file.py文件定义了主函数main,用于调用PetSpider类。
根据给定的网址来获取网页详细信息,得到的html就是网页的源代码。
get_html_content函数主要功能是递归下载网页源代码。注意将byte类型转换成string类型,其中re.findall的含义是返回string中所有与pattern(正则表达式)相匹配的全部字串,返回形式为数组。
新建pet_spider.py。
首先实现获取网页源代码的函数:
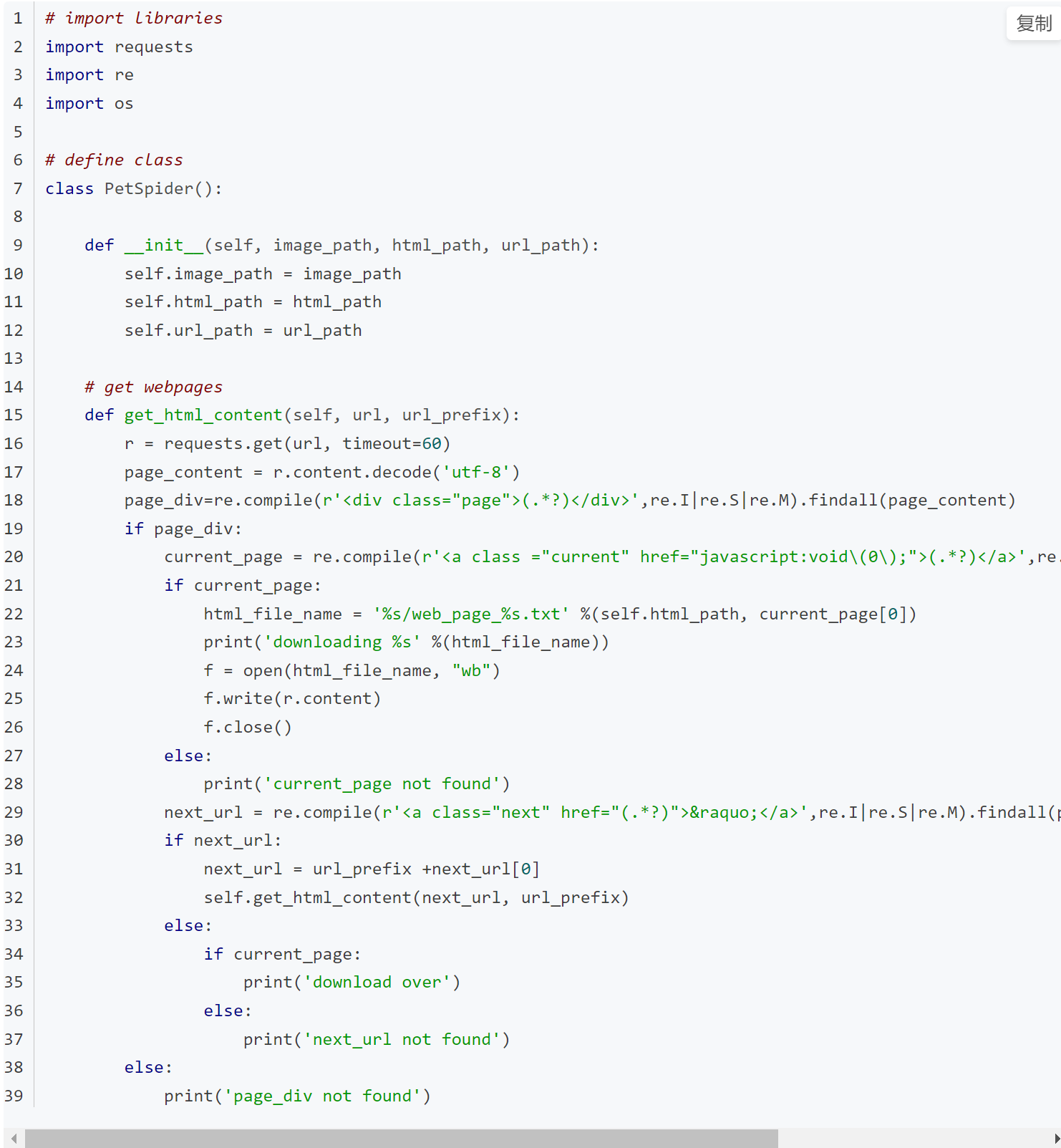
获取网页源代码后,从网页源代码中匹配过滤图片的urls,制作进度条,从文件中读出网页图片内容,最后将所有urls写入文件。
继续向pet_spider.py文件中添加如下代码:

现将所有图片url过滤出来。
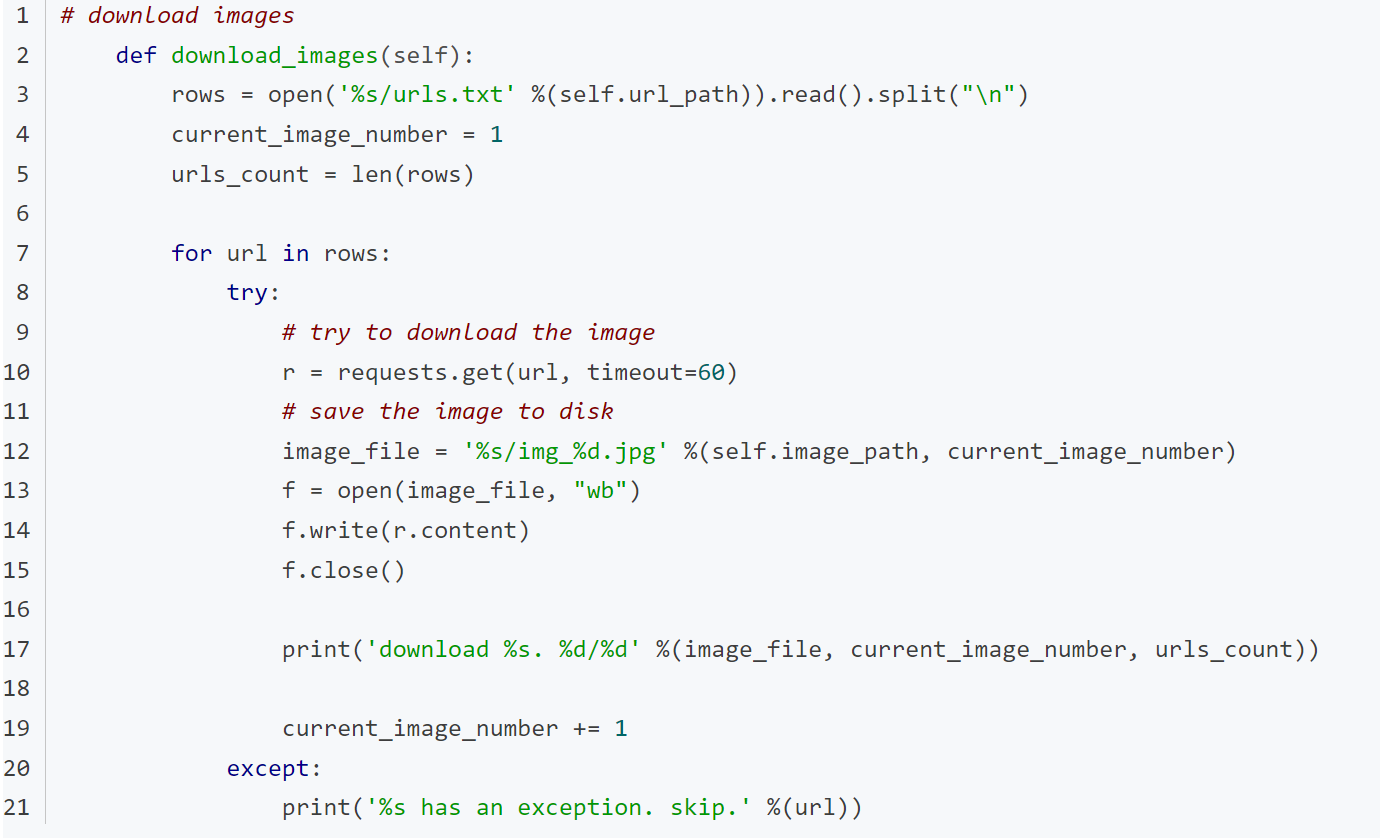
将图片下载到本地,首先将urls字符串保存到列表中,遍历列表中的urls,将下载的图片保存在文件中。
继续向pet_spider.py文件中添加如下代码:
新建main_file.py文件。代码如下:
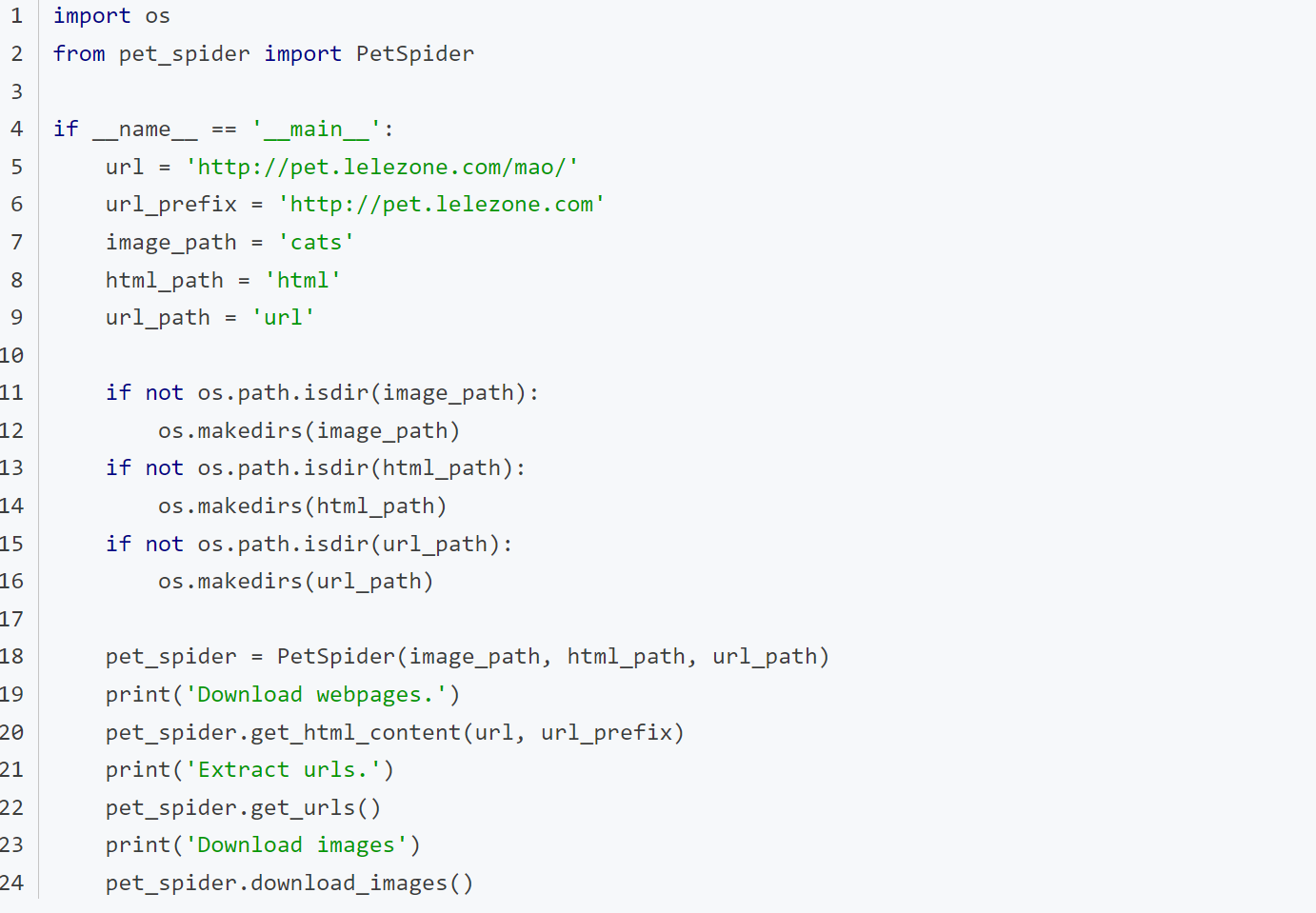
最后运行主函数实现图片爬虫。

很不错的内容,干货满满,已支持师傅,期望师傅能输出更多干货,并强烈给师傅文章点赞
另外,如果可以的话,期待师傅能给正在参加年度博客之星评选的我一个五星好评,您的五星好评都是对我的支持与鼓励:https://bbs.csdn.net/topics/611387568
点赞五星好评回馈小福利:抽奖赠书 | 总价值200元,书由君自行挑选(从此页面参与抽奖的同学,只需五星好评后,参与抽奖)

