


203
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享simHash算法共有5个步骤:分词、hash、加权、合并、降维
simHash算法:首先文本的内容经过splitWords函数进行分词操作,之后getSimh函数计算分词过后文本的hash值,并进行
加权、合并和降维操作,最后通过调用getSimilarity函数,其中以getSimh处理过后的hash值作为传参,得到海明距离,从而
计算出相似度。
simHash算法的独特之处在于,相较于其他传统的hash算法,simHash算法计算出两个文本之间的hash值差距比较小,这样能够
更加精确的计算出文本之间的相似度。
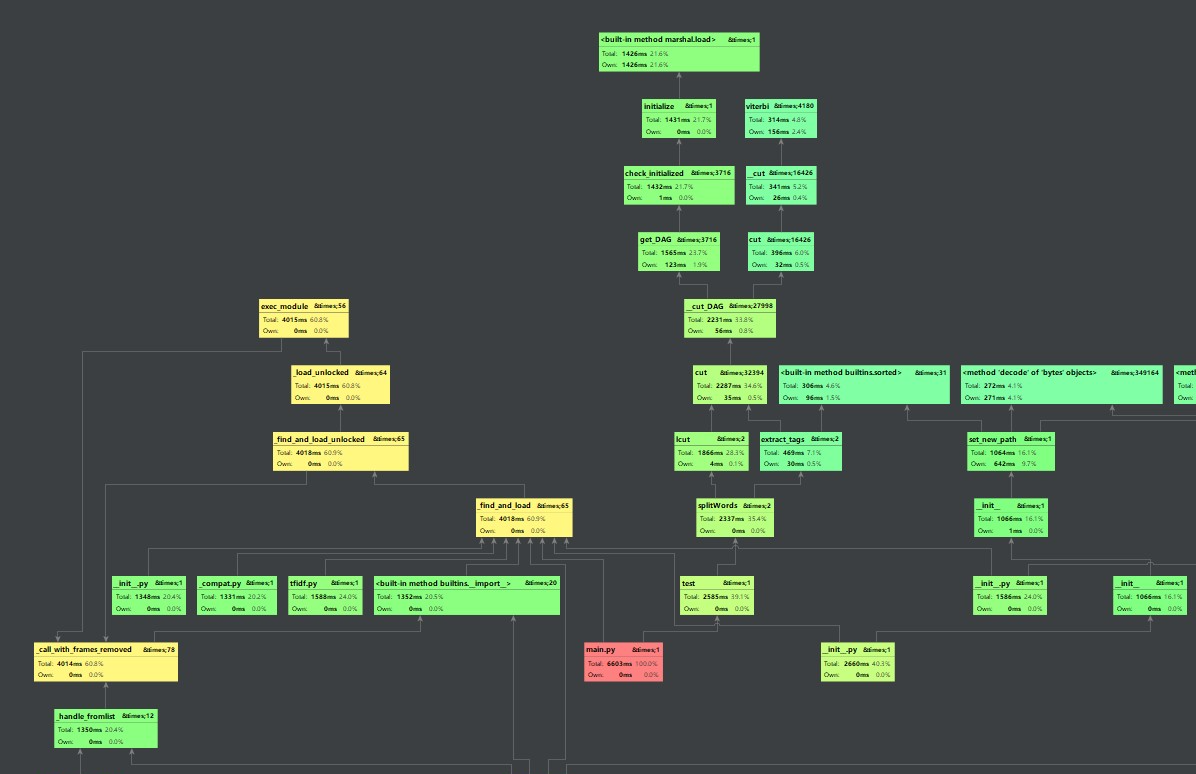
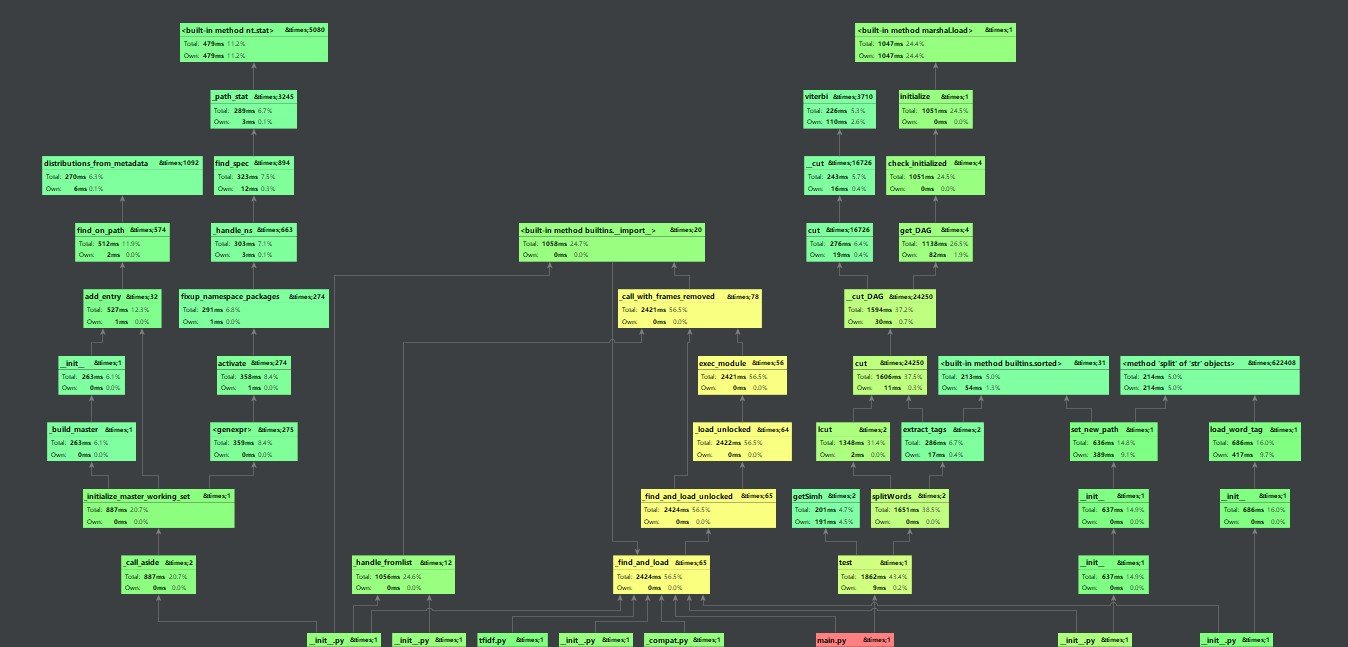
其中getWords函数耗时最多,则用正则表达式匹配过滤对其改进
原始代码:
def getWords(text):
with open(text, 'r', encoding='UTF-8') as f1:
f2 = f1.read() f1.close()
length = len(list(jieba.lcut(f2)))
s = jieba.analyse.extract_tags(f2, topK=length)
改进代码:
def getWords(text):
with open(text, 'r', encoding='UTF-8') as f1:
f2 = f1.read()
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
s = pattern.sub("", f2)
f1.close()
length = len(list(jieba.lcut(s)))
string = jieba.analyse.extract_tags(s, topK=length)
先用正则表达式匹配过滤,再用jieba.lcut来处理,提高效率。从结果可知,改进后的算法较之前的算法提升了几百ms。
构建一个test()函数用来专门测试,然后构建一个test.py文件,定义一个testSimHash测试类,测试的方法提供至少10个,具体的代码如下所示:
def test():
path1 = input("请输入论文原文的路径:")
path2 = input("请输入抄袭论文的路径:")
path3 = 'save.txt'
simhash1 = getSimh(splitWords(path1))
simhash2 = getSimh(splitWords(path2))
s1 = getSimilarity(simhash1, simhash2)
s2 = round(s1, 2)
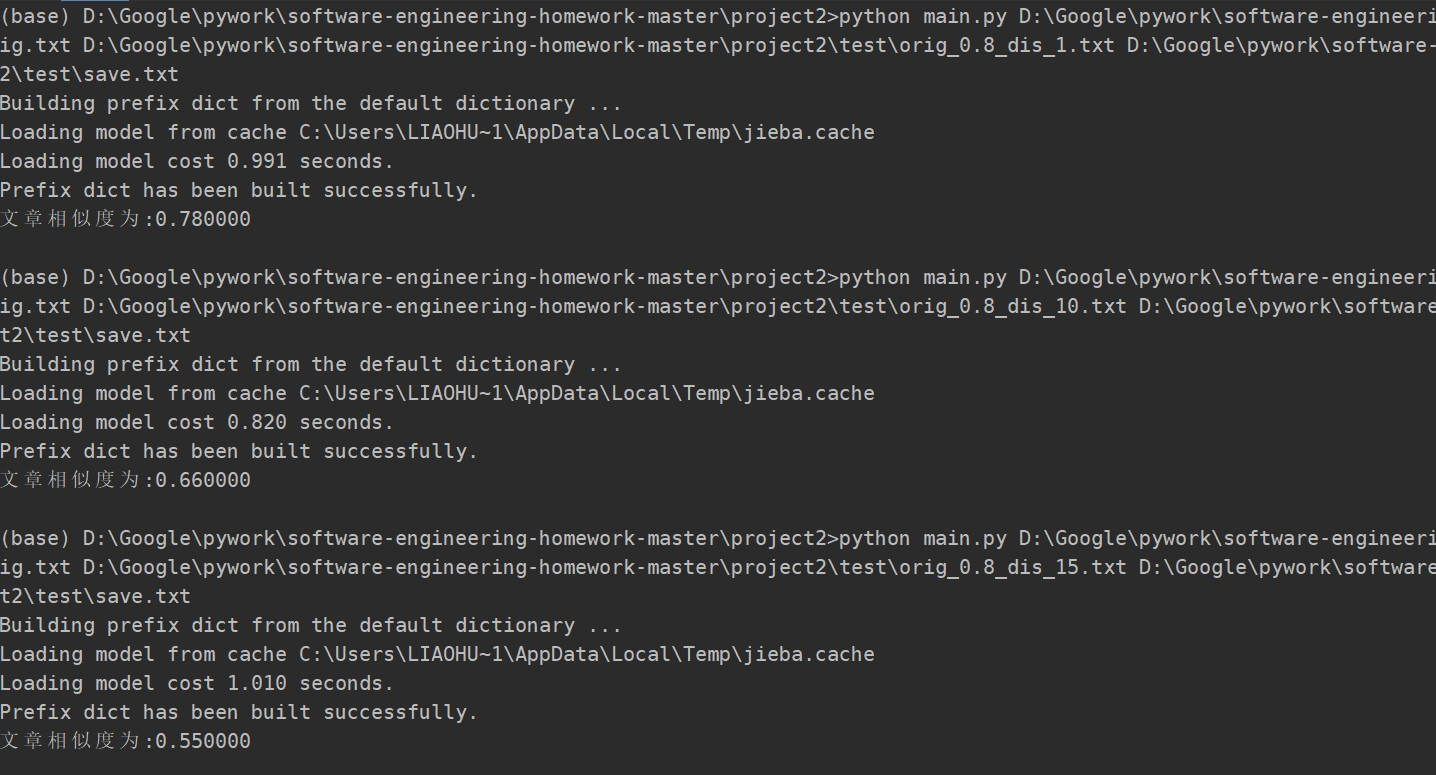
print('文章相似度为:%f' % s2)
with open(path3, 'a', encoding='utf-8')as f:
f.write(path2 + '与原文的相似度为:')
f.write(json.dumps(s2, ensure_ascii=False) + '\n')
return s2
class testSimHash(unittest.TestCase):
def test_1(self):
self.assertEqual(test(), 0.70)
def test_2(self):
self.assertEqual(test(), 0.71)
def test_3(self):
self.assertEqual(test(), 0.79)
def test_4(self):
self.assertEqual(test(), 0.65)
def test_5(self):
self.assertEqual(test(), 0.55)
def test_6(self):
self.assertEqual(test(), 0.30)
def test_7(self):
self.assertEqual(test(), 0.35)
def test_8(self):
self.assertEqual(test(), 0.85)
def test_9(self):
self.assertEqual(test(), 0.77)
def test_10(self):
self.assertEqual(test(), 0.89)
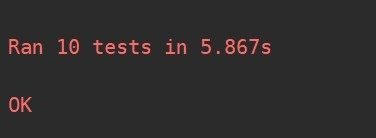
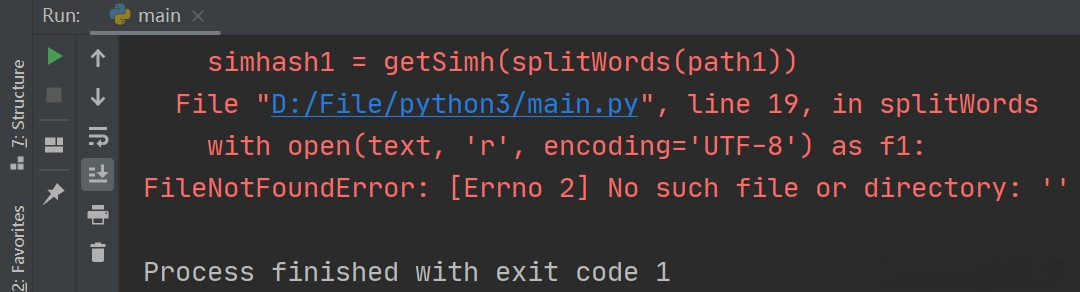
原因:在读取指定文件时,文件路径不存在,程序出现异常。
解决方法:用input()语句接收输入,一段时间后未输入则跳出,并引入os.path.exists()方法用于检验文件是否存在,若不存在则做出响应并且结束程序。
代码修改如下:
def test():
path1 = ','.join(sys.argv[1:2])
path2 = ','.join(sys.argv[2:3])
path3 = ','.join(sys.argv[3:])
+ if not os.path.exists(path1):
+ print("论文原文不存在!")
+ exit()
+ if not os.path.exists(path2):
+ print("抄袭论文不存在!")
+ exit()
simhash1 = getSimh(splitWords(path1))
simhash2 = getSimh(splitWords(path2))
s1 = getSimilarity(simhash1, simhash2)
s2 = round(s1, 2)
print('文章相似度为:%f' % s2)
with open(path3, 'a', encoding='utf-8')as f:
f.write(path2 + '与原文的相似度为:')
f.write(json.dumps(s2, ensure_ascii=False) + '\n')
return s2
修改后程序正常运行:

| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 10 |
| Estimate | 估计这个任务需要多少时间 | 2220 | 2060 |
| Development | 开发 | 1200 | 1000 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 360 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 30 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 60 | 30 |
| Coding | 具体编码 | 200 | 240 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 80 |
| Reporting | 报告 | 90 | 90 |
| Test Repor | 测试报告 | 60 | 80 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 2220 | 2060 |
