


1,409
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享这篇文章最初发表在 NVIDIA 技术博客上。有关此类的更多内容,请参阅最新的 模拟/建模/设计 新闻和教程。
Megatron 530B 等机型正在扩大人工智能可以解决的问题范围。然而,随着模型的复杂性不断增加,它们对人工智能计算平台构成了双重挑战:
我们需要的是一个多功能的人工智能平台,它可以在各种各样的模型上提供所需的性能,用于训练和推理。
为了评估这种性能, MLPerf 是唯一一个行业标准人工智能基准,用于测试六个应用程序中的数据中心和边缘平台,测量吞吐量、延迟和能效。
在 MLPerf 推理 2.0 , NVIDIA 交付领先的结果在所有工作负载和场景,同时数据中心 GPU 和最新的参赛者,NVIDIA Jetson AGX ORIN SOC 平台,为边缘设备和机器人建造。
除了硬件,还需要大量的软件和优化工作才能充分利用这些平台。 MLPerf 推理 2.0 的结果展示了如何获得处理当今日益庞大和复杂的人工智能模型所需的性能。
下面我们来看一下 MLPerf 推理 2.0 的性能,以及其中的一些优化,以及它们是如何构建的。
图 1 显示了最新的参赛者 NVIDIA Jetson AGX Orin 。
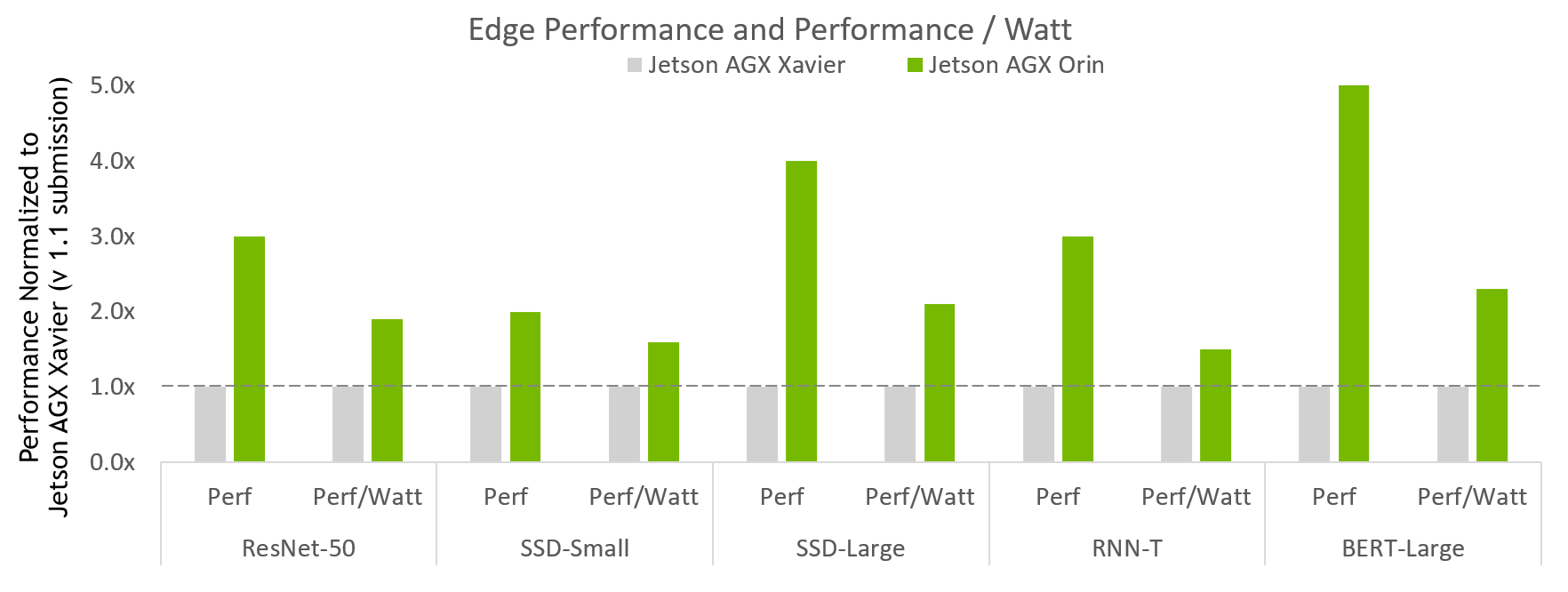 图 1 。 NVIDIA Jetson AGX Orin 性能改进
图 1 。 NVIDIA Jetson AGX Orin 性能改进
MLPerf v2.0 推断边闭合和边闭合幂;数据中心和边缘、离线吞吐量和功率的 MLPerf 结果的性能/瓦特。NVIDIA Xavier AGX Xavier:1.1-110 和 1.1-111 | Jetson AGX Orin:2.0-140 和 2.0-141 。 MLPerf 名称和徽标是商标。资料来源: http://www.mlcommons.org/en 。
图 1 显示 Jetson AGX Orin 的性能是上一代的 5 倍。在测试的全部使用范围内,它平均提高了约 3.4 倍的性能。此外, Jetson AGX Orin 的能效提高了 2.3 倍。
Jetson Orin AGX 是一个 SoC ,为多个并发人工智能推理管道提供多达 275 个人工智能计算顶层,并为多个传感器提供高速接口支持。NVIDIA Jetson AGX ORIN 开发者工具包使您能够创建先进的机器人和边缘 AI 应用程序,用于制造、物流、零售、服务、农业、智能城市、医疗保健和生命科学。
在数据中心领域,NVIDIA 继续在所有应用领域提供全面的人工智能推理性能领先。
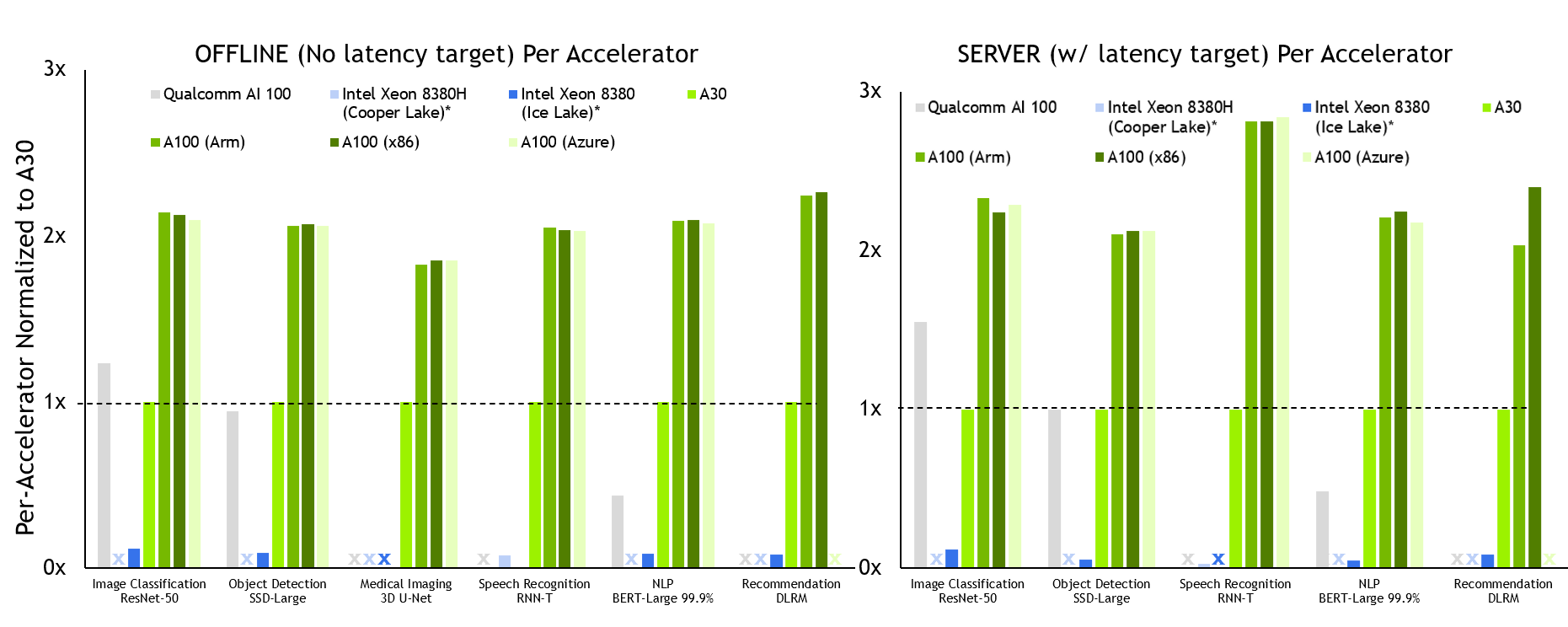 图 2 。NVIDIA A100 每台加速器性能
图 2 。NVIDIA A100 每台加速器性能
MLPerf v2 。 0 推理关闭;使用数据中心脱机和服务器中报告的加速器计数,根据各自提交的最佳 MLPerf 结果得出每加速器性能。高通 AI 100:2.0-130 ,来自 MLPerf v.1.1 的英特尔至强 8380 提交: 1.1-023 和 1.1-024 ,英特尔至强 8380H 1.1-026 ,NVIDIA A30:2.0-090 ,NVIDIA A100 ( Arm ): 2.0-077 ,NVIDIA A100 ( x86 ): 2.0-094 。 MLPerf 名称和徽标是商标。资料来源: http://www.mlcommons.org/en 。
NVIDIA A100 在离线和服务器场景下的所有测试中都提供了最佳的每加速器性能。
我们提交了以下配置的 A100 :
Microsoft Azure 也使用其 A100 实例提交,我们也在这一数据中显示了这一点。
所有配置都提供了大致相同的推理性能,这证明了我们 Arm 软件堆栈的就绪性,以及 A100 本地和云中的总体性能。
A100 还提供了高达 105 倍的性能,比仅 CPU 提交( RNN-T ,服务器方案)。 A30 在除一项工作外的所有工作上都表现出领导水平。与 A100 一样,它运行了所有数据中心类别测试。
提供出色的推理性能需要一种全堆栈方法,在这种方法中,优秀的硬件与优化且通用的软件相结合。 NVIDIA TensorRT 和 NVIDIA Triton 推理服务器都在不同工作负载下提供出色的推理性能方面发挥着关键作用。
NVIDIA Orin 新 NVIDIA 安培架构 I GPU 由 NVIDIA TensorRT 8.4 支持。对于 MLPerf 性能而言,它是 SoC 中最重要的组件。扩展了大量优化 GPU 内核的 TensorRT 库,以支持新的体系结构。 TensorRT 生成器会自动拾取这些内核。
此外, MLPerf 网络中使用的插件都已移植到 NVIDIA Orin 并添加到 TensorRT 8.4 中,包括 res2 插件( resnet50 )和 qkv 到上下文插件( BERT )。与带有离散 GPU 加速器的系统不同,输入不会从主机内存复制到设备内存,因为 SoC DRAM 由 CPU 和 iGPU 共享。
除了 iGPU , NVIDIA 还使用了两个深度学习加速器( DLA ),以在离线情况下在 CV 网络( resnet50 、 ssd mobilenet 、 ssd-resnet34 )上实现最高的系统性能。
NVIDIA Orin 采用了新一代 DLA 硬件。为了利用这些硬件改进, DLA 编译器添加了以下 NVIDIA Orin 功能,这些功能在升级到 TensorRT 的未来版本时自动可用,无需修改任何应用程序源代码。
对两个 DLA 加速器的批量大小进行了微调,以获得 GPU + DLA 聚合性能的适当平衡。该调整平衡了将 DLA 引擎 GPU 后备内核的调度冲突降至最低的需求,同时减少了 SoC 共享 DRAM 带宽的整体潜在不足。
虽然大多数工作负载与 MLPerf 推断 v1 相比基本保持不变。 1 、使用 KITS19 数据集增强了 3D UNet 医学成像工作量。这个新的肾肿瘤图像数据集有更大的不同大小的图像,每个样本需要更多的处理。
KiTS19 数据集为实现高效节能推理带来了新的挑战。更具体地说:
为了解决这个问题,我们开发了一种滑动窗口方法来处理这些图像:
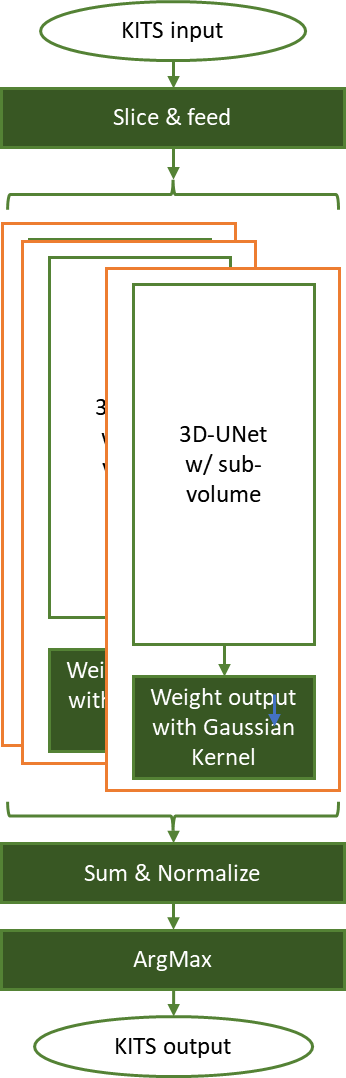 图 3 。 3D UNet 使用滑动窗口方法执行 KiTS19 肾脏肿瘤分割推断任务
图 3 。 3D UNet 使用滑动窗口方法执行 KiTS19 肾脏肿瘤分割推断任务
在图 3 中,每个输入张量被切片成具有重叠因子( 50% )的 ROI 形状( 128x128x128 ),并输入预训练网络。然后对每个滑动窗口输出进行最佳加权,以获取归一化 sigma = 0.125 的高斯核特征。
推理结果根据原始输入张量形状进行聚合,并对这些权重因子进行归一化。然后, ArgMax 操作会切割分割信息,标记背景、正常肾细胞和肿瘤。
该实现将分割与基本事实进行比较,并计算骰子分数以确定基准测试的准确性。您还可以直观地检查结果(图 4 )。
图 4 。(左) 3D CT 图像,是推理任务的输入。(中)地面真实分割结果显示正常肾细胞(灰色)和肿瘤(高亮显示白色)。(右) 3D UNet 套件的推断结果 19 。
我们的数据中心 GPU 已经支持 INT8 精度超过 5 年,与 FP16 和 FP32 精度级别相比,这种精度在许多型号上带来了显著的加速,精度损失接近于零。
对于 3D UNet ,我们通过使用 TensorRT IInt8MinMaxCalibrator 校准校准集中的图像来使用 INT8 。该实现在 FP32 参考模型中实现了 100% 的精度,从而实现了基准的高精度和低精度模式。
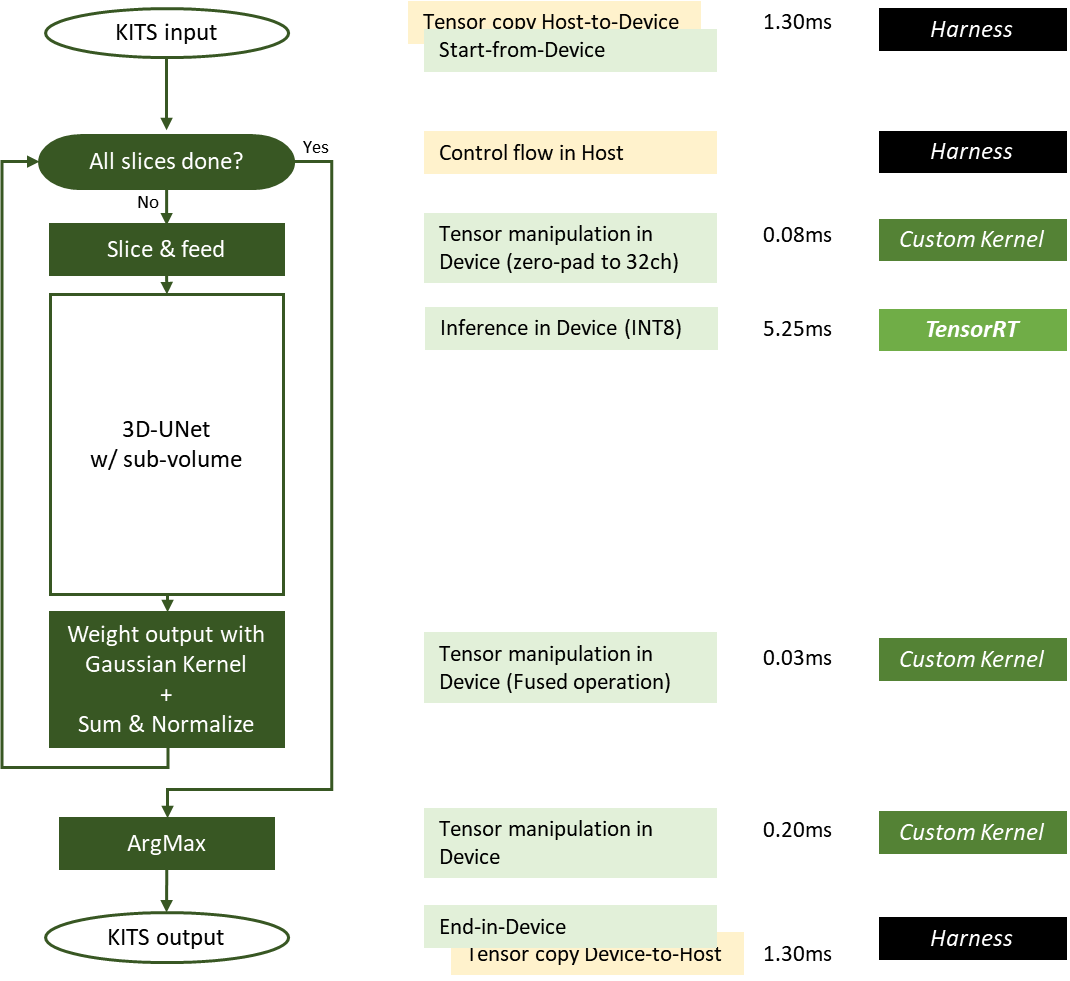 图 5 。 MLPerf 推理 v2 中使用的 NVIDIA 3D UNet KiTS19 实现。 0 提交
图 5 。 MLPerf 推理 v2 中使用的 NVIDIA 3D UNet KiTS19 实现。 0 提交
在图 5 中,绿色框在设备( GPU )上执行,黄色框在主机( CPU )上执行。滑动窗口推理所需的一些操作被优化为融合操作。
利用 GPUDirect RDMA 和存储,可以最小化或消除主机到设备或设备到主机的数据移动。从 DGX-A100 系统中测量一个输入样本(其大小接近平均输入大小)的每项工作的延迟。切片内核和 ArgMax 内核的延迟随输入图像大小成比例变化。
以下是一些具体的优化措施:
TensorRT 需要 NC / 32DHW32 格式的 INT8 输入。我们使用一个定制的 CUDA 内核,该内核在 GPU 全局内存中的一个连续内存区域中执行对零填充的切片,并将 INT8 线性输入张量切片重新格式化为 INT8 NC / 32DHW32 格式。
GPU 中的零填充和重新格式化张量要比其他昂贵的 H2D 传输速度快得多, H2D 传输的数据要多 32 倍。这种优化显著提高了整体性能,并释放了宝贵的系统资源。
TensorRT 引擎用于在每个滑动窗口切片上运行推理。因为 3D UNet 是密集的,我们发现增加批量大小会成比例地增加引擎的运行时间。
NVIDIA 提交继续显示 Triton 推理服务器的多功能性。这一轮, Triton 推理服务器还支持在 AWS 推理机上运行 NVIDIA Triton 。NVIDIA Triton 使用 Python 后端运行推理优化 PyTorch 和 TensorFlow 模型。
使用NVIDIA Triton 和火炬神经元, NVIDIA 提交获得 85% 至 100% 的推断推理的自然推断性能。
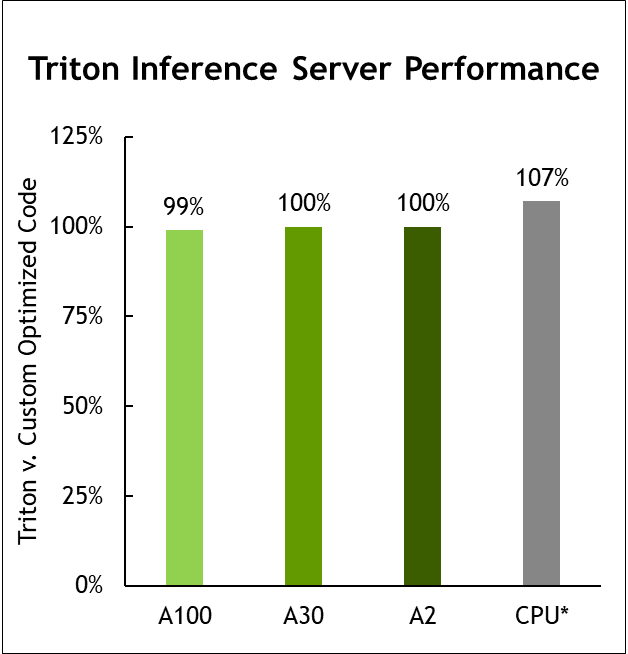 图 6 。 Triton 推理服务器性能
图 6 。 Triton 推理服务器性能
MLPerf v1 。 1 .关闭推理;每个加速器的性能源自使用数据中心脱机中报告的加速器计数的各个提交的最佳 MLPerf 结果。显示所有提交工作负载的几何平均值。 CPU 基于 MLPerf 推理 1.1 中的英特尔提交数据进行比较,以比较相同 CPU 的配置,提交 1.0-16 、 1.0-17 、 1.0-19 。 NVIDIA Triton 在 CPU 上: 2.0-100 和 2.0-101 。 A2:2.0-060 和 2.0-061 。 A30:2.0-091 和 2.0-092 。 A100:2.0-094 和 2.0-096 。 MLPerf 名称和徽标是商标。资料来源: http://www.mlcommons.org/en 。
NVIDIA Triton 现在支持 AWS 推理处理器,并提供与仅在 AWS Neuron SDK 上运行几乎相同的性能。
NVIDIA 推理领导力来自于打造最优秀的人工智能加速器,用于培训和推理。但优秀的硬件只是开始。
NVIDIA TensorRT 和 Triton 推理服务器软件在跨这一组不同的工作负载提供出色的推理性能方面发挥着关键作用。他们可以在 NGC ,NVIDIA 中心,以及其他 GPU 优化的软件,用于深度学习,机器学习,和 HPC 。
NGC 容器化软件使加速平台的建立和运行变得更加容易,因此您可以专注于构建真正的应用程序,并加快实现价值的时间。 NGC 可以通过您首选的云提供商的市场免费获得。
有关更多信息,请参阅 推理技术概述 。本文涵盖了人工智能推理的发展趋势、部署人工智能应用程序面临的挑战,以及推理开发工具和应用程序框架的细节。



