


37,975
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
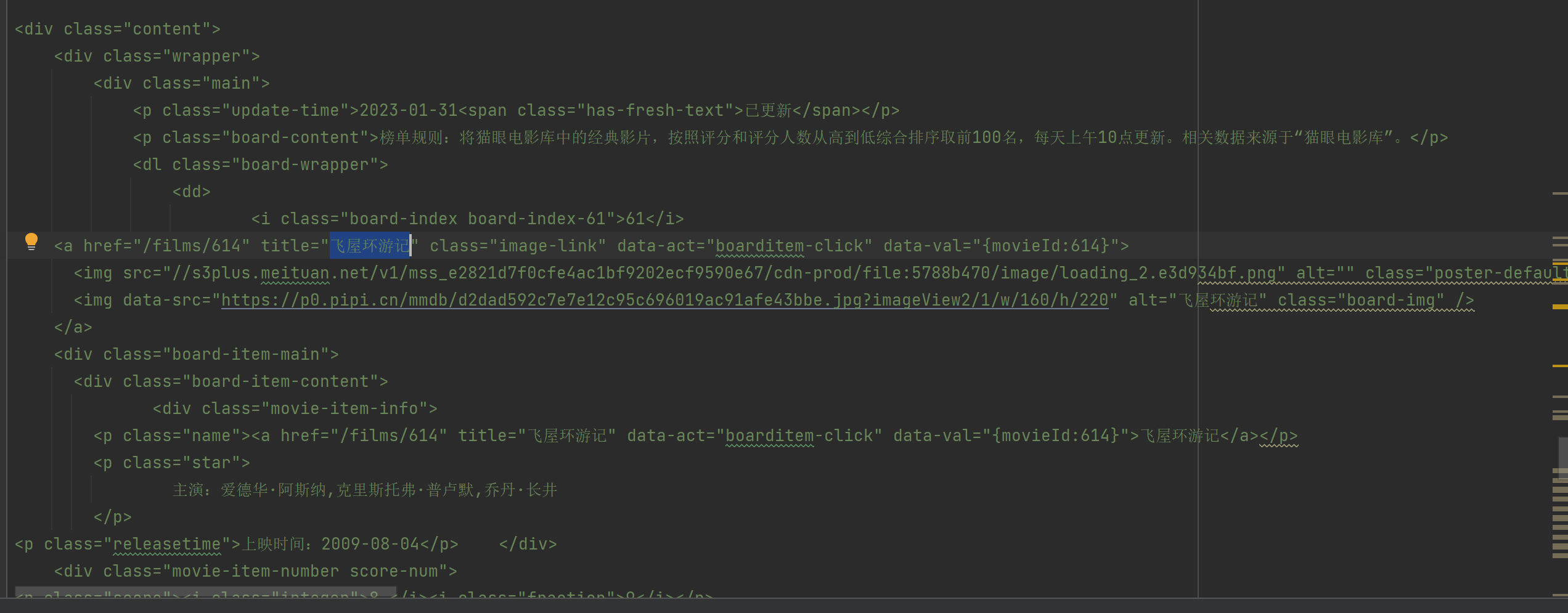
从这样的HTML文档中抓取电影名字
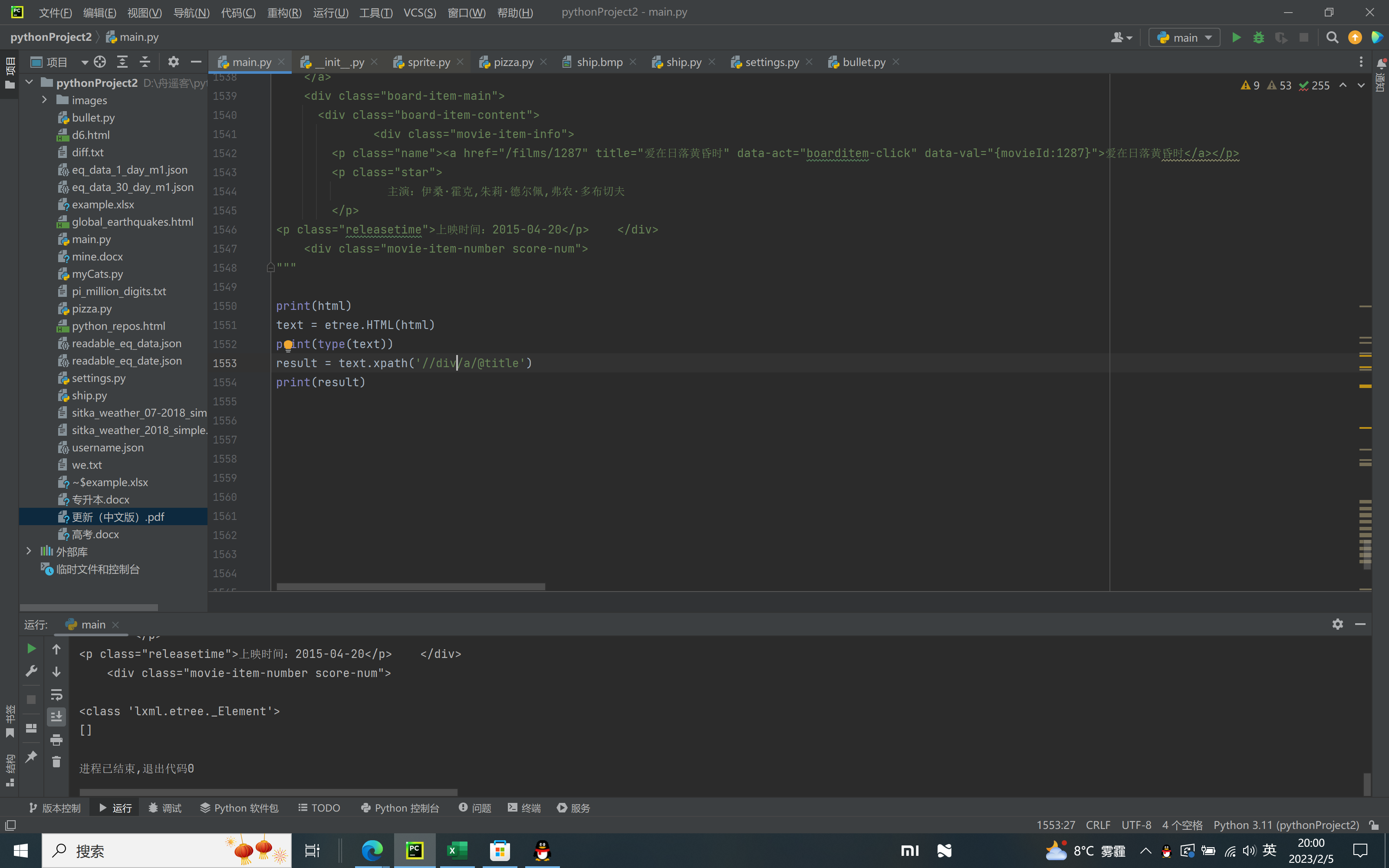
使用lmxl库时,匹配以下格式:
result = text.xpath('//div/a/@title')
结果是抓取不到数据
更改抓取格式,如下:
result = text.xpath('//div//a/@title')
就可以成功抓取
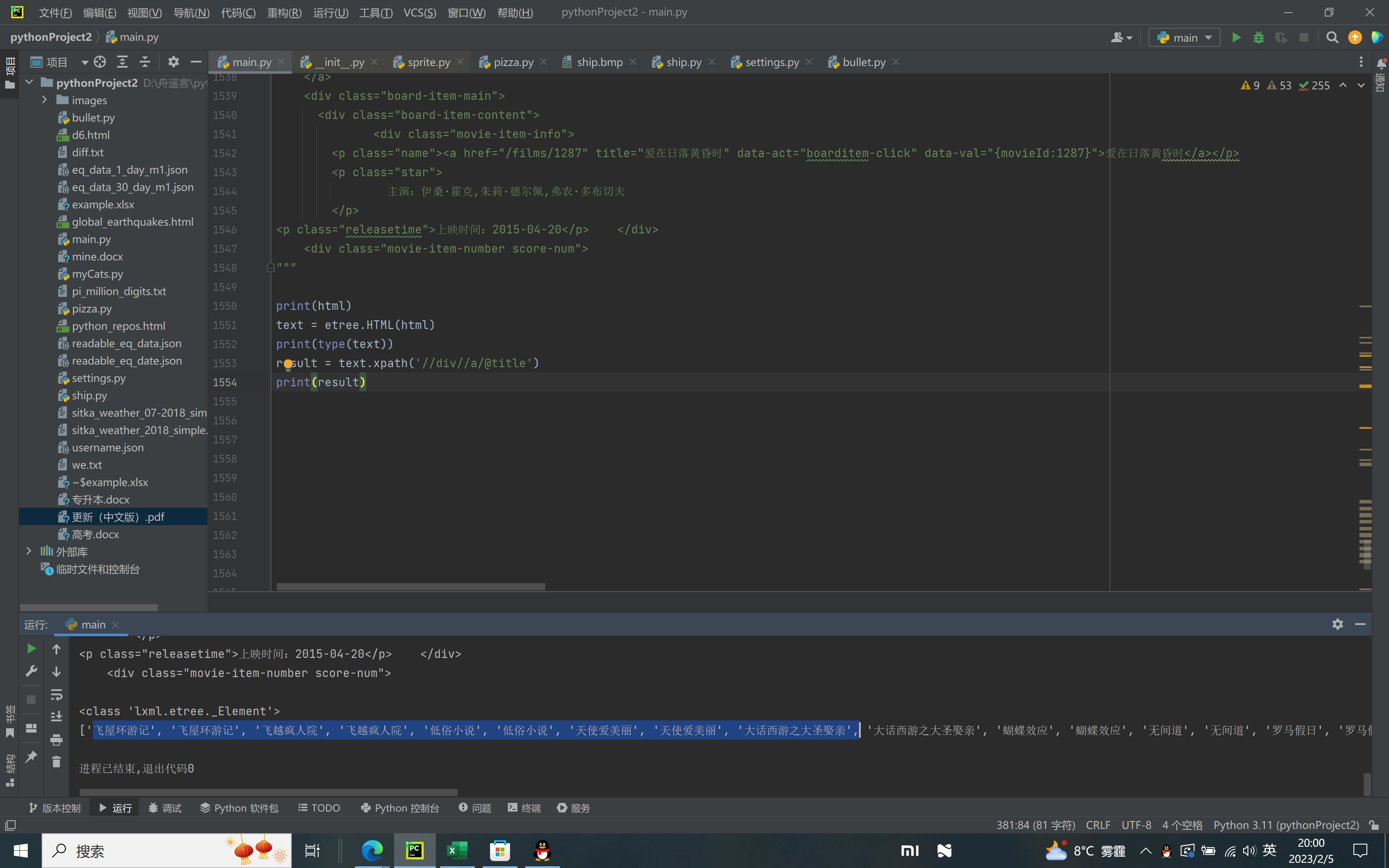
这是怎么一回事!!!!
a不是div的子节点吗?
为什么要用子孙节点才能抓取???
为什么要用子孙节点才能抓取???

首先你要定位到需要的a标签的父级标签,比如那个p标签(//p[@class="name"]/a/@title)


