





19,317
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
本文将带领大家亲手实现一个垃圾信息过滤的算法。
在正式讲解算法之前,最重要的是对整个任务有一个全面的认识,包括算法的输入和输出、可能会用到的技术,以及技术大致的流程。
本任务的目标是去识别一条短信是否为垃圾信息,即输入为一条文本信息,输出为二分类的分类结果。2002年,Paul Graham提出使用“贝叶斯推断”过滤垃圾邮件。1000封垃圾邮件可以过滤掉995封,且没有一个误判。另外,这种过滤器还具有自我学习的功能,会根据新收到的邮件,不断调整。收到的垃圾邮件越多,它的准确率就越高。
朴素贝叶斯算法是一种有监督的机器学习算法,即算法的实现包含了构建训练集、数据预处理、训练、在测试集上验证等步骤。在下文中首先介绍算法的理论基础,再逐一介绍代码实现算法的整个流程。
算法的第一步是收集两组带有标签的信息训练集,正常信息和垃圾信息。接下来根据训练集计算概率。训练集越大,最终计算的概率精度越高,分类效果也会越好。具体来说,训练过程包含以下两步
1●解析训练集中所有信息,并提取每一个词。
2●统计每一个词出现在正常信息和垃圾信息的词频
根据这个初步统计结果可以实现一个垃圾信息的鉴别器。对于一个新的样本输入,可以提取每一个词并根据前面给出的贝叶斯公式进行计算,最终得到分类结果。下面对一个简单的样例进行手工模拟,来熟悉算法的内部原理。
假设通过初步的统计,得到了以下两个单词在垃圾信息和正常信息中出现的频率,如表1所示。
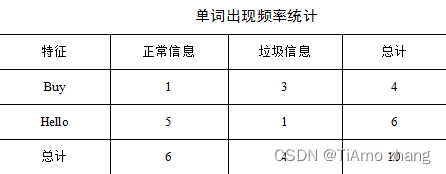
根据频率表可以进一步计算出正常信息的概率P(Y=ham)、垃圾信息的概率P(Y=spam)、出现单词Buy的概率P(Buy)、出现单词Hello的概率P(Hello)以及垃圾信息出现单词Buy的概率P(Buy|Y=spam)。图1展示了几个关键概率所在的位置。

图1 概率分布位置示意图
目前有一个新的信息为“Hello, Buy!”,首先分词得到Hello和Buy两个单词。根据贝叶斯公式,可以计算该信息属于垃圾信息的概率
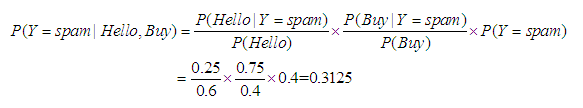
同理可计算该信息属于正常信息的概率
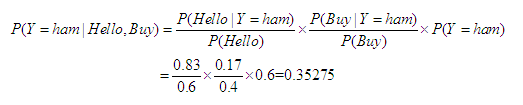
根据计算结果可知该信息属于正常信息。
代码清单1定义了一个从文件中读取数据的函数,将信息内容与标签进行初步的处理,使其根据标签的不同,存储在不同的列表当中。
代码清单1 数据集预处理函数
def getDateSet(dataPath=""r"./SMSSpamCollection"):
with open(dataPath, encoding='utf-8') as f:
txt_data = f.readlines()
data = [] # 所有信息
classTag = [] # 标签
for line in txt_data:
line_split = line.strip("\n").split('\t')
if line_split[0] == "ham":
data.append(line_split[1])
classTag.append(1)
elif line_split[0] == "spam":
data.append(line_split[1])
classTag.append(0)
return data, classTag
为了更方便的使用接口,可以定义一个NaiveBayes的类,实现数据预处理、模型训练、预测等功能。
首先介绍一个朴素贝叶斯模型中需要记录的变量:不同类型短信数量、相应单词列表、训练集中不重复单词集合等。它们在类的构造函数中进行初始化,并在模型训练过程中不断更新。最终,构造函数如代码清单2所示。
代码清单2 朴素贝叶斯构造函数
class NaiveBayes:
def __init__(self):
self.__ham_count = 0 # 正常短信数量
self.__spam_count = 0 # 垃圾短信数量
self.__ham_words_count = 0 # 正常短信单词总数
self.__spam_words_count = 0 # 垃圾短信单词总数
self.__ham_words = list() # 正常短信单词列表
self.__spam_words = list() # 垃圾短信单词列表
# 训练集中不重复单词集合
self.__word_dictionary_set = set()
self.__word_dictionary_size = 0
self.__ham_map = dict() # 正常短信的词频统计
self.__spam_map = dict() # 垃圾短信的词频统计
self.__ham_probability = 0.0
self.__spam_probability = 0.0
在加载数据集时,并没有将输入分割为一个一个的单词。代码清单3实现了一个对一整行输入进行预处理的函数data_preprocess,其按正则分割开(\W:匹配特殊字符,即非字母、非数字)一行输入,并将单词长度小于等于3的过滤掉,最后将其变成小写字母,返回列表。
代码清单3 朴素贝叶斯预处理函数
# 输入为一封信息的内容
def data_preprocess(self, sentence):
# 将输入转换为小写并将特殊字符替换为空格
temp_info = re.sub('\W', ' ', sentence.lower())
# 根据空格将其分割为一个一个单词
words = re.split(r'\s+', temp_info)
# 返回长度大于等于3的所有单词
return list(filter(lambda x: len(x) >= 3, words))

图 2 输入样例
模型训练分成了三个子函数进行,一个是fit函数作为最外层的函数,其接受如图2所示一整行的数据以及每行数据的标签作为输入,首先使用data_preprocess函数将一整行输入分割为单词,将分割得到的单词组以及对应的标签送入build_word_set函数中,在build_word_set函数中,使用for循环不断更新成员变量,获得的单词列表如图3所示。

图3 命令行输出单词列表
最后调用word_count函数来对正常短信和垃圾短信的词频进行统计,并计算垃圾短信和正常短信的概率。word_count函数最终获得的字典输出如图4所示,字典的键为单词本身,值为其出现的次数。使用字典的形式进行存储,方便在后面预测时可以较快的进行索引。
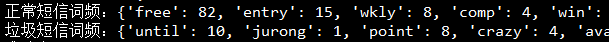
图4 词频统计
整个训练过程的代码如代码清单4所示。
代码清单4 训练函数
def fit(self, X_train, y_train):
words_line = []
for sentence in X_train:
words_line.append(self.data_preprocess(sentence))
self.build_word_set(words_line, y_train)
self.word_count()
def build_word_set(self, X_train, y_train):
for words, y in zip(X_train, y_train):
if y == 0:
# 正常短信
self.__ham_count += 1
self.__ham_words_count += len(words)
for word in words:
self.__ham_words.append(word)
self.__word_dictionary_set.add(word)
if y == 1:
# 垃圾短信
self.__spam_count += 1
self.__spam_words_count += len(words)
for word in words:
self.__spam_words.append(word)
self.__word_dictionary_set.add(word)
self.__word_dictionary_size = len(self.__word_dictionary_set)
def word_count(self):
# 不同类别下的词频统计
for word in self.__ham_words:
self.__ham_map[word] = self.__ham_map.setdefault(word, 0) + 1
for word in self.__spam_words:
self.__spam_map[word] = self.__spam_map.setdefault(word, 0) + 1
# 非垃圾短信的概率
self.__ham_probability = self.__ham_count / (self.__ham_count + self.__spam_count)
# 垃圾短信的概率
self.__spam_probability = self.__spam_count / (self._ham_count+ self._spam_count)
最后编写测试集上的预测函数如代码清单5所示。该模块分为两个函数实现,总的接口predict函数,接受很多条用list存储的短信作为输入,predict_one函数实现了对一条短信进行预测的功能。在该函数中,首先对一整行输入分割,再计算为垃圾短信或正常短信的概率,最后将两者进行比较,返回预测结果。需要注意的是,在计算概率时要使用self.__ham_map.get(word, 0) + 1这样的平滑操作进行处理。
代码清单5 朴素贝叶斯预测函数
def predict(self, X_test):
return [self.predict_one(sentence) for sentence in X_test]
def predict_one(self, sentence):
ham_pro = 0
spam_pro = 0
words = self.data_preprocess(sentence)
for word in words:
ham_pro += math.log(
(self.__ham_map.get(word, 0) + 1) / (self.__ham_count + self.__word_dictionary_size))
spam_pro += math.log(
(self.__spam_map.get(word, 0) + 1) / (self.__spam_count + self.__word_dictionary_size))
ham_pro += math.log(self.__ham_probability)
spam_pro += math.log(self.__spam_probability)
return int(spam_pro >= ham_pro)
本模块需要将前面实现的所有功能联合起来,对模型进行验证,首先加载数据集,并将数据集区分为训练集和测试集,在训练集上训练模型,并在测试集上验证模型的效果,代码实现如代码清单6所示。
代码清单6 朴素贝叶斯主函数
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
if __name__ == "__main__":
# 加载数据集
data, classTag = getDateSet()
# 设置训练集大小
train_size = 3000
# 训练集
train_X = data[:train_size]
train_y = classTag[:train_size]
# 测试集
test_X = data[train_size:]
test_y = classTag[train_size:]
# 在训练集上训练模型
nb_model = NaiveBayes()
nb_model.fit(train_X, train_y)
# 在测试集上得到预测结果
pre_y = nb_model.predict(test_X)
# 模型评价
accuracy_score_value = accuracy_score(test_y, pre_y)
recall_score_value = recall_score(test_y, pre_y)
precision_score_value = precision_score(test_y, pre_y)
classification_report_value = classification_report(test_y, pre_y)
print("准确率:", accuracy_score_value)
print("召回率:", recall_score_value)
print("精确率:", precision_score_value)
print(classification_report_value)
最后运行整个程序,设置训练集为1000条数据,可以得到最终的预测结果如图5所示,其准确率在测试集上达到了95.52%的效果。
那么,如果将训练集进一步扩大为2000条、3000条数据,模型是否会获得更优异的性能?
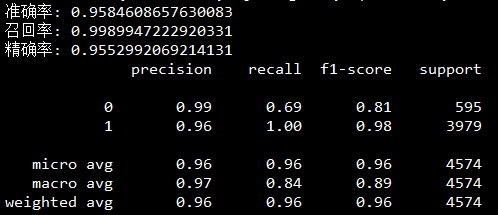
图5 训练集1000条数据预测效果
如图6、图7所示为当训练集为2000条数据以及3000条数据的预测结果,可以发现,随着训练集的增大,模型也会越来越灵敏,获得更高的准确率和精确率。
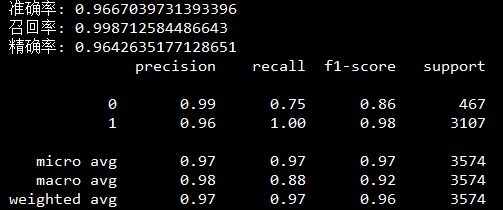
图6 训练集2000条数据预测效果
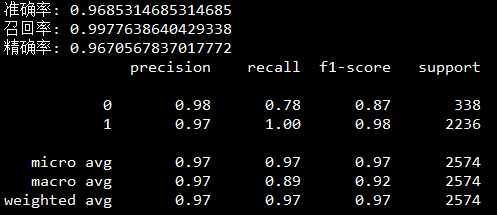
图7 训练集3000条数据预测效果


