


688
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2023年福大-软件工程实践-W班 |
|---|---|
| 这个作业要求在哪里 | 软件工程实践第二次作业————个人实战 |
| 这个作业的目标 | 完成对澳大利亚网球公开赛相关数据的收集,并实现一个能够对赛事数据进行统计的控制台程序 |
| 其他参考文献 | CSDN、博客园 |
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 600 | 800 |
| • Analysis | • 需求分析 (包括学习新技术) | 15 | 50 |
| • Design Spec | • 生成设计文档 | 25 | 30 |
| • Design Review | • 设计复审 | 10 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 100 | 100 |
| • Coding | • 具体编码 | 350 | 450 |
| • Code Review | • 代码复审 | 30 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 50 | 50 |
| Reporting | 报告 | 50 | 90 |
| • Test Repor | • 测试报告 | 20 | 30 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 670 | 915 |
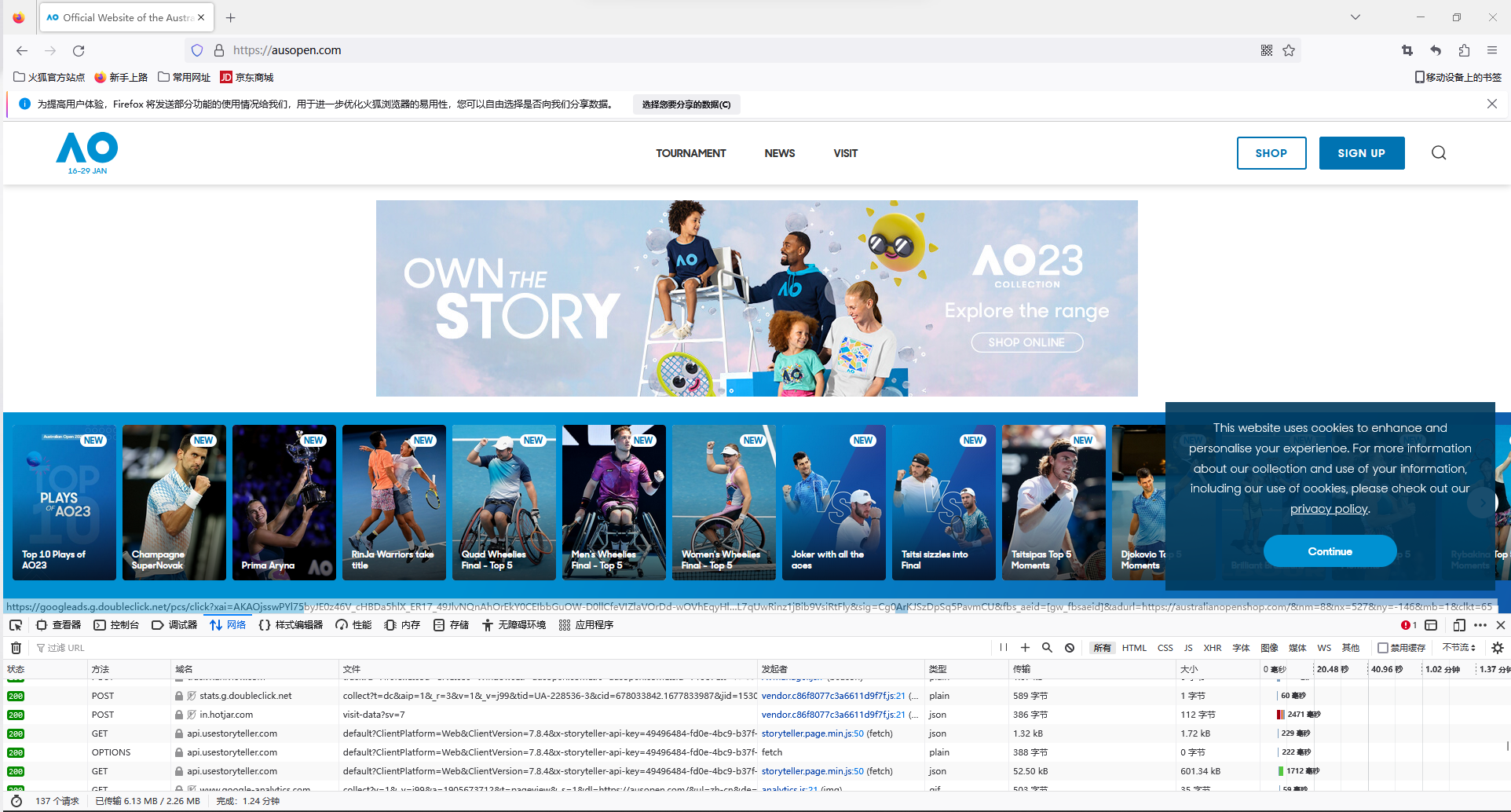
用火狐浏览器进入澳网官网后,按下F12进入开发者模式,在网络里可以找到json文件
json文件不能直接读取,因此采用引入fastjson进行json字符串解析,使用JSONArrary和JSONObject还有String方法将json数据拆分成类、数组和字符串,方便对其进行解析。
当input.txt中输入players时,对players.json进行遍历,找出需要的属性。当input.txt中输入result ···时,先遍历对应文件中的每场比赛,找出status为Winner的选手,通过team_id得到队员的uuid,再查找player数组得到选手的姓名缩写。score可以直接从match中获取。
代码由两个类实现,AOSearch调用Lib类,负责程序运行,Lib类实现主要功能。
public boolean isRightDate(String date)
{
if (date == null) return false;
int a=Integer.parseInt(START_DAY);
int b=Integer.parseInt(END_DAY);
int c=Integer.parseInt(date);
return a <= c && c <= b;
}
public String get_json_Players()
{
String json_players = readFile("src/data/players.json");
JSONObject jo = JSON.parseObject(json_players);
JSONArray ja = jo.getJSONArray("players");
StringBuilder result = new StringBuilder();
for (int i=0 ; i<ja.size() ; i++)
{
result.append("full_name:").append(ja.getJSONObject(i).getString("full_name")).append("\ngender:")
.append((ja.getJSONObject(i).getString("gender")).equals("F") ? "female" : "male").append("\nnationality:")
.append(ja.getJSONObject(i).getJSONObject("nationality").getString("name")).append("\n-----\n");
}
return result.toString();
}
可以使用hashMap对已经访问过的数据进行缓存,可以提高程序的运行效率。
测试使用的是JUnit5,对于AOSearch类的测试,只需要测试参数的检测即可
@org.junit.jupiter.api.Test
void main() {
AOSearch.main(new String[]{"INPUT.txt","output.txt"});
AOSearch.main(new String[]{"IN.txt"});
}
使用try和catch,抛出异常。
try
{
FileInputStream is = new FileInputStream(path);
int len = is.available();
bytes = new byte[len];
is.read(bytes);
is.close();
}
catch (FileNotFoundException e)
{
System.out.println(path+"文件未找到");
}
catch (IOException e)
{
System.out.println("读取文件异常");
}
if (args.length != 2)
{
System.out.println("参数数量错误");
return;
}

可以使用hashMap对已经访问过的数据进行缓存,可以提高程序的运行效率。
是否有实验数据支持?


