



571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享参考了这篇帖子的两个工具https://blog.csdn.net/m0_58353302/article/details/127253474
(RISCV-32位体系结构具有32位指令长度)
1、选择一个交叉编译平台Compiler Explorer,将之前的test.c粘贴进去,选择risc-v32位:

2、生成的汇编代码:
g:
addi sp,sp,-32
sw s0,28(sp)
addi s0,sp,32
sw a0,-20(s0)
lw a5,-20(s0)
addi a5,a5,3
mv a0,a5
lw s0,28(sp)
addi sp,sp,32
jr ra
f:
addi sp,sp,-32
sw ra,28(sp)
sw s0,24(sp)
addi s0,sp,32
sw a0,-20(s0)
lw a0,-20(s0)
call g
mv a5,a0
mv a0,a5
lw ra,28(sp)
lw s0,24(sp)
addi sp,sp,32
jr ra
main:
addi sp,sp,-16
sw ra,12(sp)
sw s0,8(sp)
addi s0,sp,16
li a0,8
call f
mv a5,a0
addi a5,a5,1
mv a0,a5
lw ra,12(sp)
lw s0,8(sp)
addi sp,sp,16
jr ra
参照 RISC-V 常用汇编指令里的寄存器含义和伪指令含义理解代码:
(1)寄存器
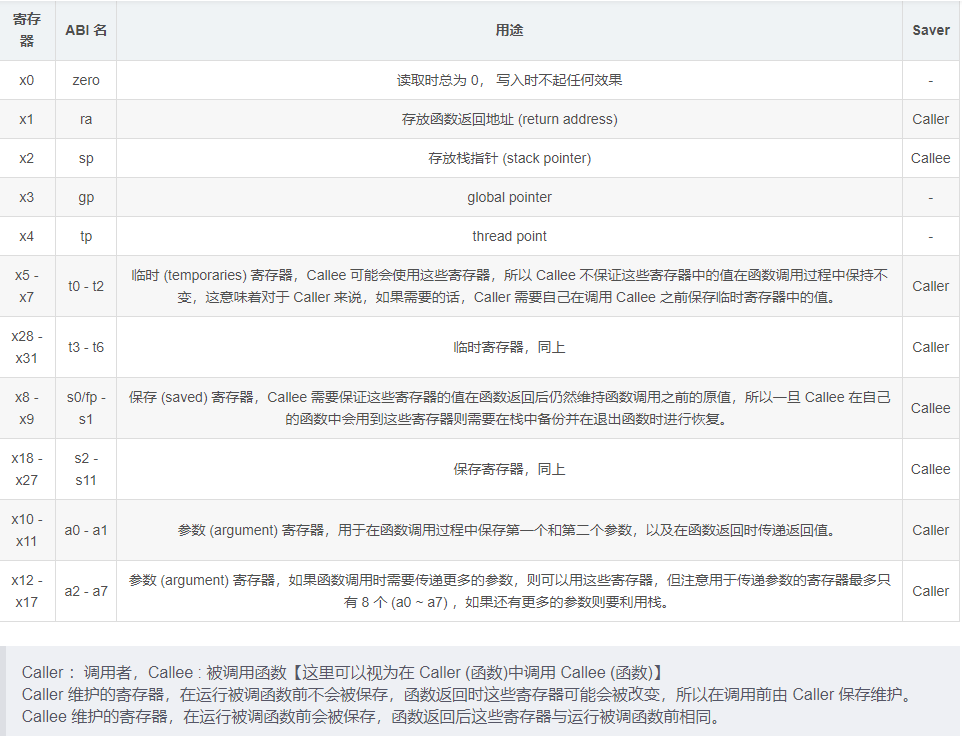
(2)用到的伪指令和指令的含义
| 伪指令 | 语法 | 等价语句 | 描述 | 例子 |
| call | call offset |
auipc x1,offset[31:12]+offset[11]; jalr x1,ofsset[11:0] (x1) | call f | |
| jr | jr rs | jalr x0,0(rs) | [不会保存跳转前的地址] | jr x5 |
| li | li rd,imm | … | rd = imm (32bit)直接加载32位立即数 | li x5,0x12345678 |
| mv | mov rd,rs addi rd,rs,0 | rd = rs | mov x5,x6 |
| 指令 | 语法 | 描述 | 例子 |
| addi | add rd,rs,imm | (rs +imm) 的值保存到 rd | addi x5,x6,8 |
| auipc | auipc rd,imm(20bit) | rd = (imm << 12) + pc (相对 pc 的偏移值) | auipc x5,0x1234 |
| sw | sw rs2,imm(rs1) | 将rs2中的32bit数据写入内存 imm+rs1 处 | sw x5,40(x6) |
| lw | lw rd,imm(rs) | 从内存 imm+rs 处读取32bit数据到 rd 中 | lw x5,40(x6) |
| jalr | jalr rd,imm(rs) | 12bit的imm符号拓展,(rs+imm)低位置0存到rd,跳转 | jarl x1,0(x5) |
(不过他的jalr指令和jr伪指令没太看懂,搜了两个合起来好像看得懂得解释伪指令jr的含义和指令2.2 JALR(jalr的含义):)


因此对汇编代码进行分析注释如下:
g:
addi sp,sp,-32#sp=sp-32
sw s0,28(sp) #将s0中的32bit数据写入内存 sp+28 处
addi s0,sp,32 #s0=sp+32
sw a0,-20(s0) #将a0中的32bit数据写入内存 s0-20 处
lw a5,-20(s0) #从内存 s0-20 处读取32bit数据到 a5 中
addi a5,a5,3 #a5=a5+3
mv a0,a5#a0=a5
lw s0,28(sp)#从内存 sp+28 处读取32bit数据到 s0 中
addi sp,sp,32 #sp=sp+32
jr ra #保存返回地址到x0,跳转到ra寄存器保存的地址
f:
addi sp,sp,-32 #sp=sp-32
sw ra,28(sp) #将ra中的32bit数据写入内存 sp+28 处
sw s0,24(sp) #将s0中的32bit数据写入内存 sp+24 处
addi s0,sp,32 #s0=sp+32
sw a0,-20(s0) #将a0中的32bit数据写入内存 s0-20 处
lw a0,-20(s0) #从内存 s0-20 处读取32bit数据到 a0 中
call g #跳转到g
mv a5,a0 #a5=a0
mv a0,a5 #a0=a5
lw ra,28(sp)#从内存sp+28中读取32bit数据到ra中
lw s0,24(sp)#从内存sp+24中读取32bit数据到s0中
addi sp,sp,32#sp=sp+32
jr ra #保存返回地址到x0,跳转到ra寄存器保存的地址
main:
addi sp,sp,-16 #sp=sp-16
sw ra,12(sp) #将ra中的32bit数据写入内存sp+12处
sw s0,8(sp) #将s0中的32bit数据写入内存 sp+8 处
addi s0,sp,16 #s0=sp+16
li a0,8 #a0=8
call f #跳转到f
mv a5,a0 #a5=a0
addi a5,a5,1#a5=a5+1
mv a0,a5 #a0=a5
lw ra,12(sp) # 从内存 sp+12 处读取32bit数据到 ra 中
lw s0,8(sp) #从内存 sp+8 处读取32bit数据到 s0 中
addi sp,sp,16#sp=sp+16
jr ra#保存返回地址到x0,跳转到ra寄存器保存的地址
但是call指令还是没明白咋跳转的。。(太笨了)
在risc-v运行平台上得到了汇编代码运行对应的可执行的机器指令:(看之前博主说这个网站它不支持64位的)
而且那个riscv汇编代码运行的网站上汇编代码放进去只能运行g的函数,运行不了f因为ra寄存器初始值是0。改了下g和f的顺序,都放在了main之后:
| Machine Code | Basic Code | Original Code |
|---|---|---|
| 0xff010113 | addi x2 x2 -16 | addi sp,sp,-16 |
| 0x00112623 | sw x1 12(x2) | sw ra,12(sp) |
| 0x00812423 | sw x8 8(x2) | sw s0,8(sp) |
| 0x01010413 | addi x8 x2 16 | addi s0,sp,16 |
| 0x00800513 | addi x10 x0 8 | li a0,8 |
| 0x00000317 | auipc x6 0 | call f |
| 0x024300e7 | jalr x1 x6 36 | call f |
| 0x00050793 | addi x15 x10 0 | mv a5,a0 |
| 0x00178793 | addi x15 x15 1 | addi a5,a5,1 |
| 0x00078513 | addi x10 x15 0 | mv a0,a5 |
| 0x00c12083 | lw x1 12(x2) | lw ra,12(sp) |
| 0x00812403 | lw x8 8(x2) | lw s0,8(sp) |
| 0x01010113 | addi x2 x2 16 | addi sp,sp,16 |
| 0x00008067 | jalr x0 x1 0 | jr ra |
| 0xfe010113 | addi x2 x2 -32 | addi sp,sp,-32 |
| 0x00112e23 | sw x1 28(x2) | sw ra,28(sp) |
| 0x00812c23 | sw x8 24(x2) | sw s0,24(sp) |
| 0x02010413 | addi x8 x2 32 | addi s0,sp,32 |
| 0xfea42623 | sw x10 -20(x8) | sw a0,-20(s0) |
| 0xfec42503 | lw x10 -20(x8) | lw a0,-20(s0) |
| 0x00000317 | auipc x6 0 | call g |
| 0x020300e7 | jalr x1 x6 32 | call g |
| 0x00050793 | addi x15 x10 0 | mv a5,a0 |
| 0x00078513 | addi x10 x15 0 | mv a0,a5 |
| 0x01c12083 | lw x1 28(x2) | lw ra,28(sp) |
| 0x01812403 | lw x8 24(x2) | lw s0,24(sp) |
| 0x02010113 | addi x2 x2 32 | addi sp,sp,32 |
| 0x00008067 | jalr x0 x1 0 | jr ra |
| 0xfe010113 | addi x2 x2 -32 | addi sp,sp,-32 |
| 0x00812e23 | sw x8 28(x2) | sw s0,28(sp) |
| 0x02010413 | addi x8 x2 32 | addi s0,sp,32 |
| 0xfea42623 | sw x10 -20(x8) | sw a0,-20(s0) |
| 0xfec42783 | lw x15 -20(x8) | lw a5,-20(s0) |
| 0x00378793 | addi x15 x15 3 | addi a5,a5,3 |
| 0x00078513 | addi x10 x15 0 | mv a0,a5 |
| 0x01c12403 | lw x8 28(x2) | lw s0,28(sp) |
| 0x02010113 | addi x2 x2 32 | addi sp,sp,32 |
| 0x00008067 | jalr x0 x1 0 | jr ra |
对比了下过程好像是ra存了call指令的下一条指令地址: x1=x6+36
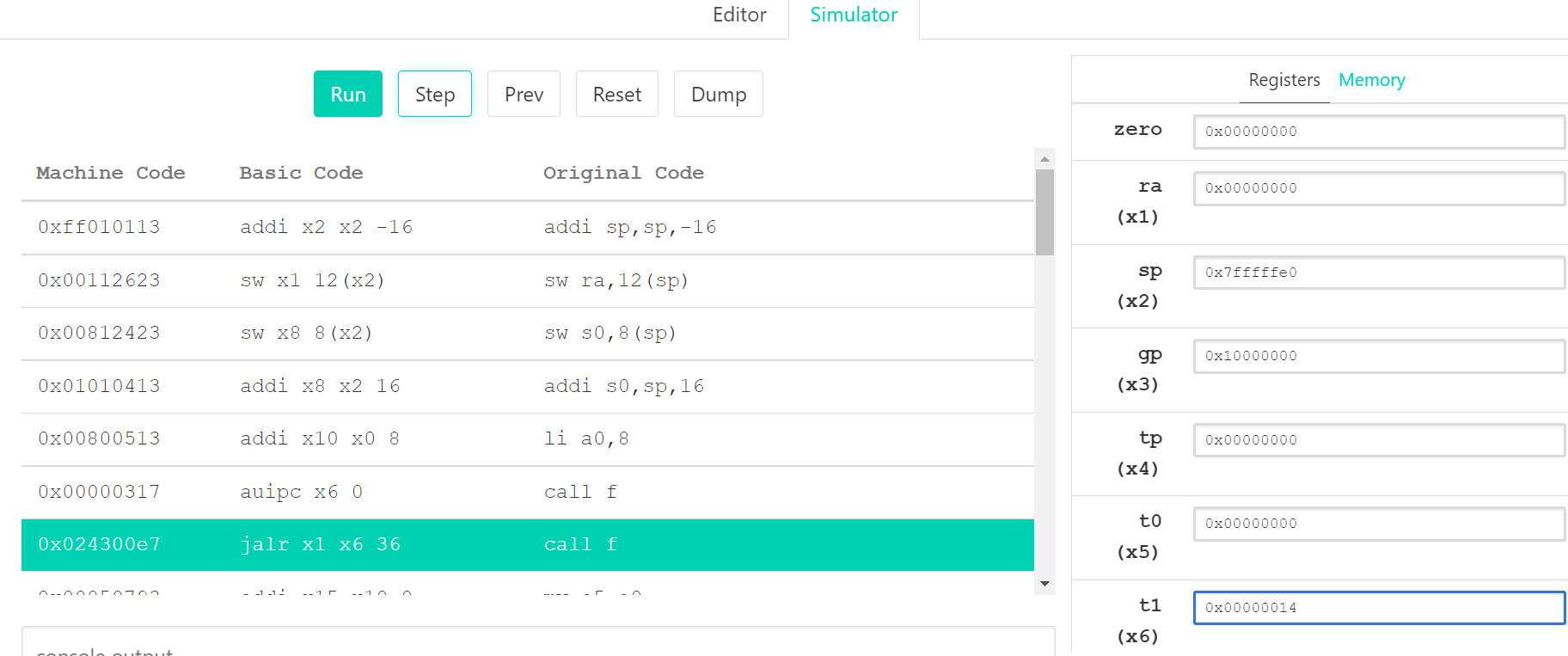
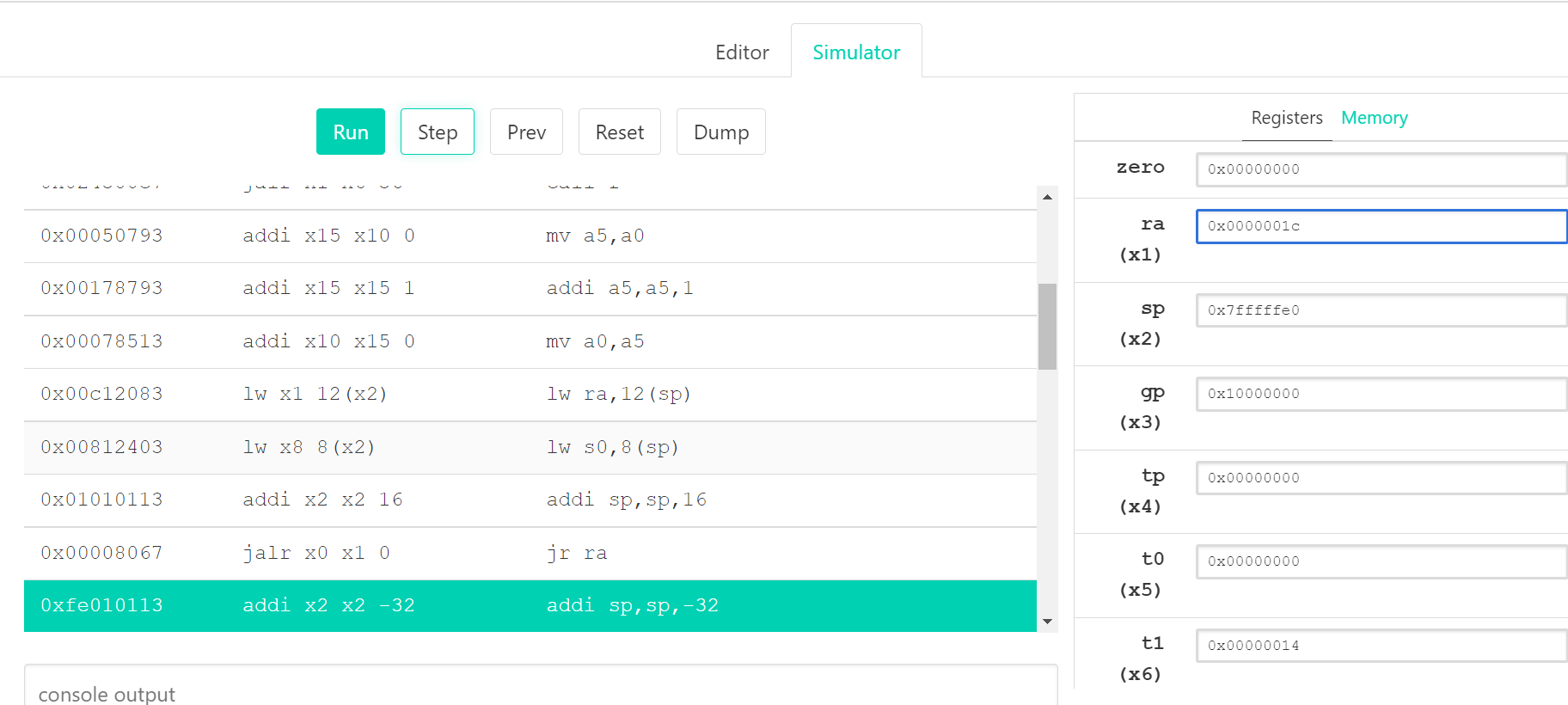
不明白的地方搜到的答案好像让我搞明白了两个地方:为什么返回地址是x0
 因此call f 的机器代码为:auipc x6 0 jalr x1 x6 36 实际意思是把当前pc存入x6,再把当前pc+4存入x1(ra)并跳转到x6+36(f放在了main后面正好就是即f的入口处。:
因此call f 的机器代码为:auipc x6 0 jalr x1 x6 36 实际意思是把当前pc存入x6,再把当前pc+4存入x1(ra)并跳转到x6+36(f放在了main后面正好就是即f的入口处。:
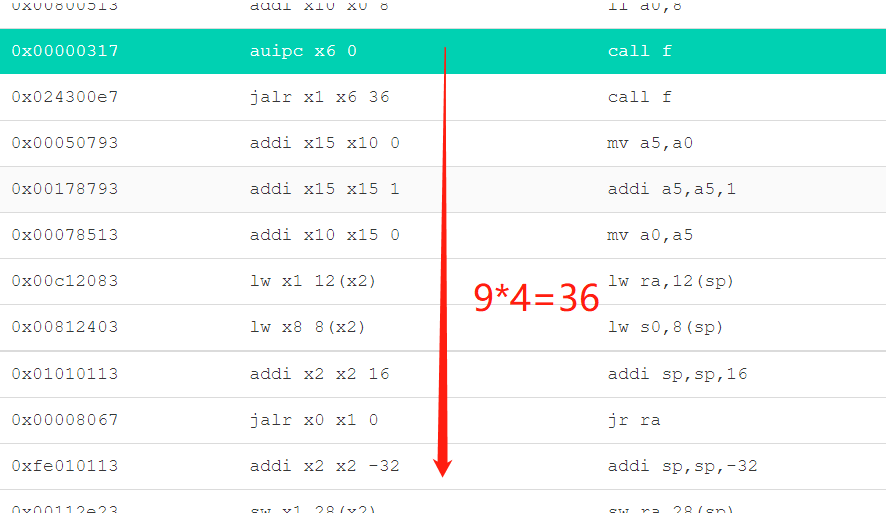
因此可以分析堆栈操作了: s0是栈底指针,sp是栈顶指针
(1)main函数开始

(2)进入到f函数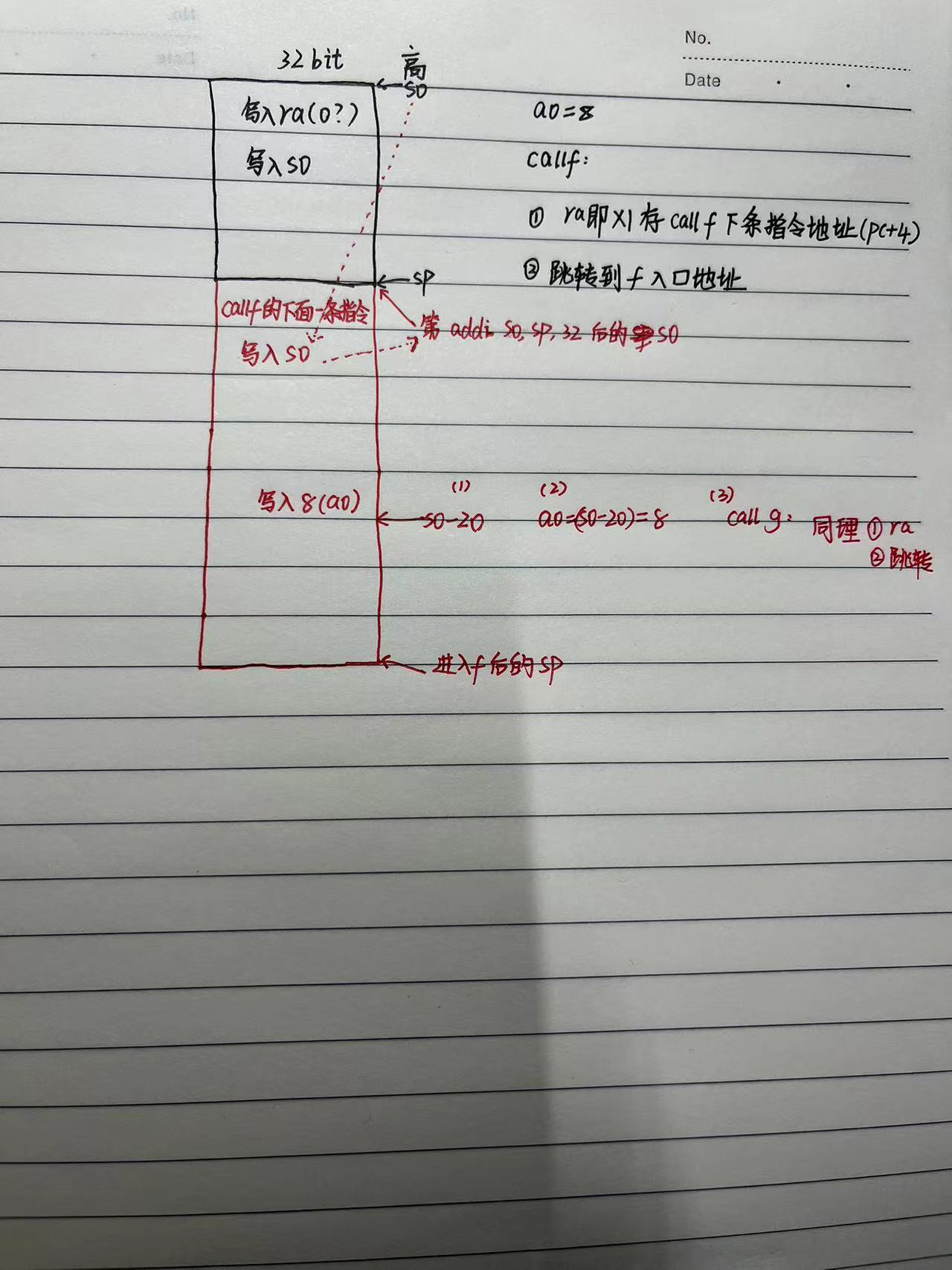
(3)进入到g函数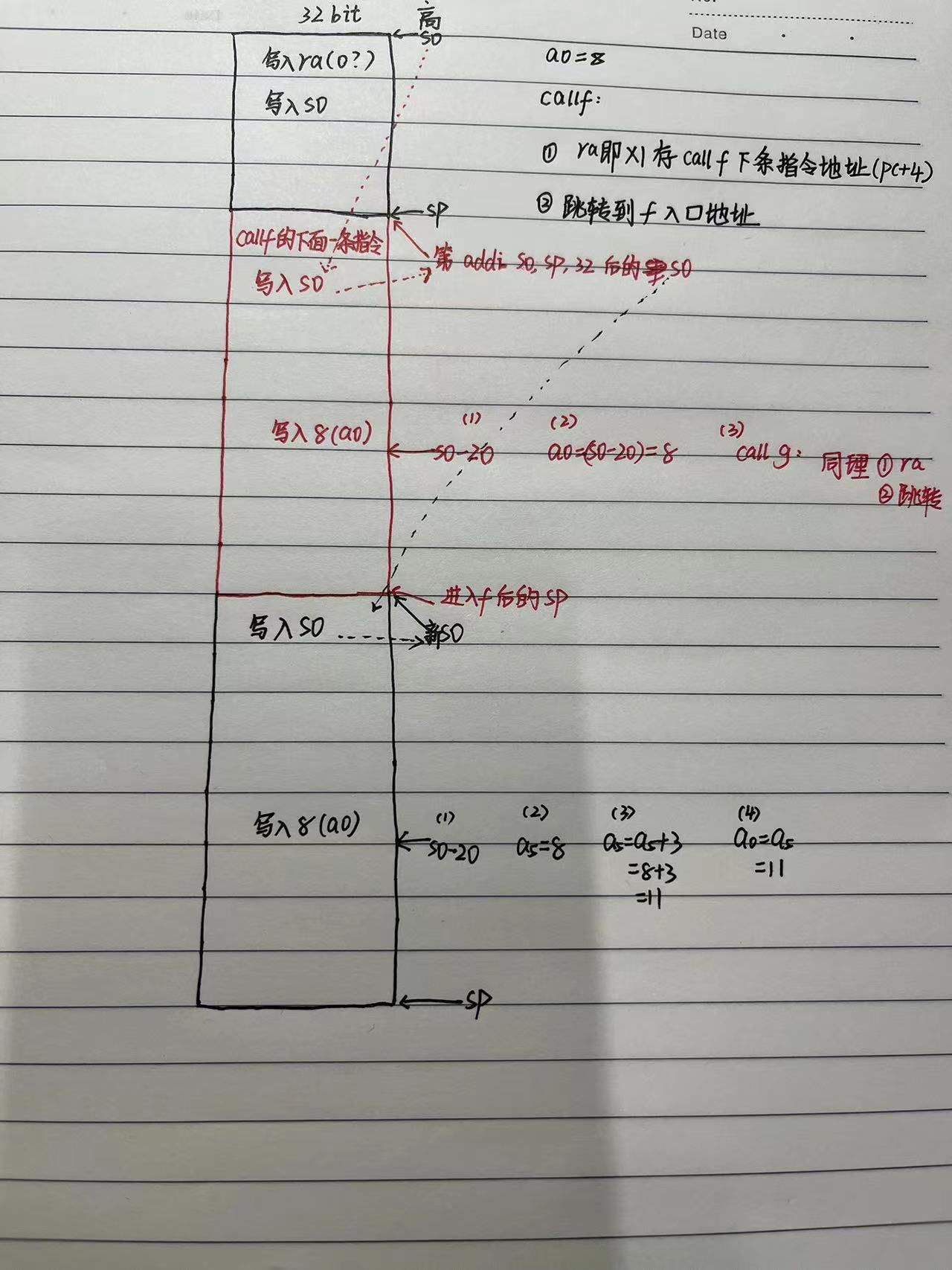
(4)g函数开始返回到call g的下一条指令,栈顶和栈底指针都回退了。即继续执行了f函数。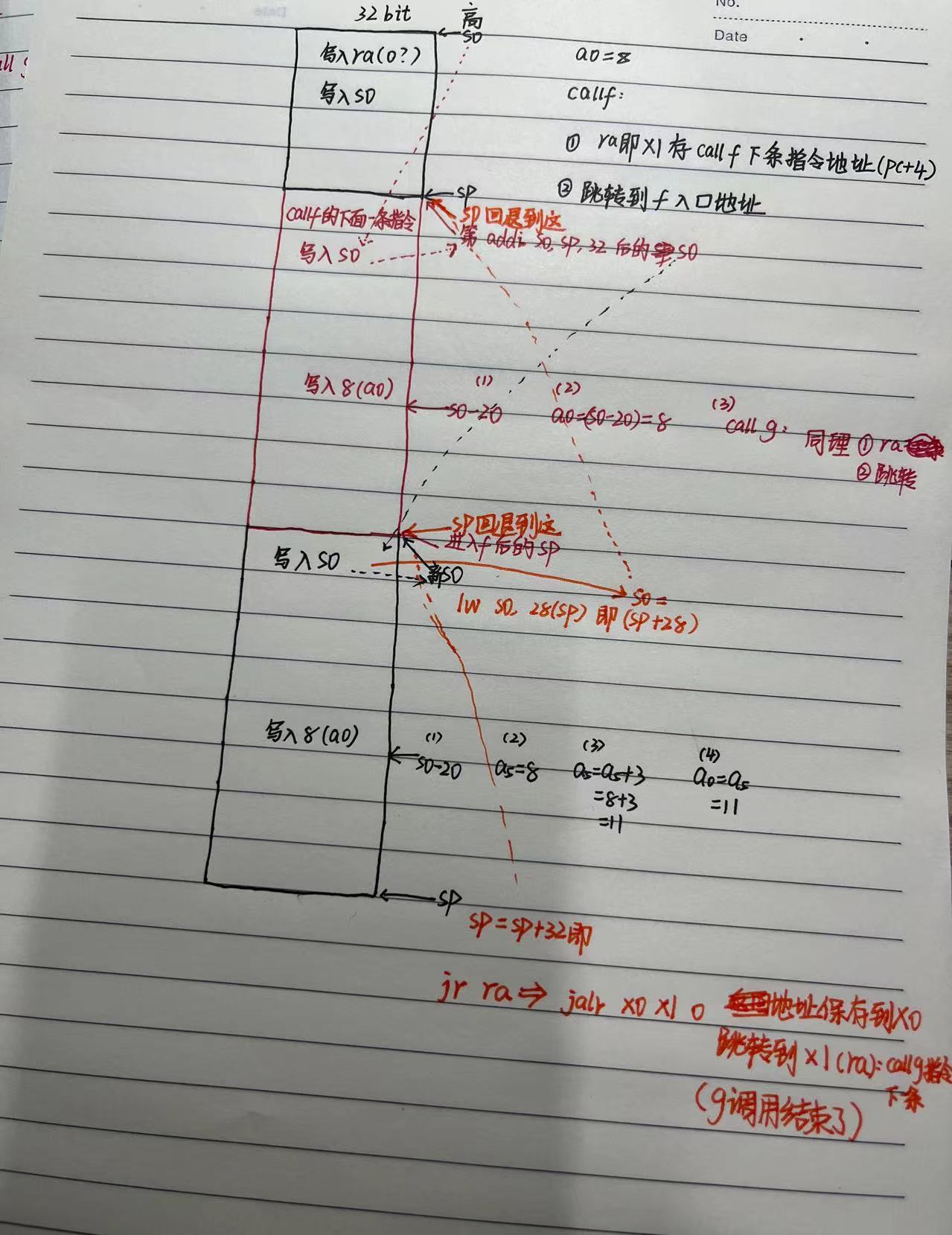
(5)接下来就是f结束然后回到main,执行结束,跟(4)过程类似。
不知道
sw a0,-20(s0) #将a0中的32bit数据写入内存 s0-20 处
lw a5,-20(s0) #从内存 s0-20 处读取32bit数据到 a5 中
以及
sw a0,-20(s0) #将a0中的32bit数据写入内存 s0-20 处
lw a0,-20(s0) #从内存 s0-20 处读取32bit数据到 a0 中
和
mv a5,a0 #a5=a0
mv a0,a5 #a0=a5
的意义是不是与课上arm64的刚存进又取出,寄存器传参和准备返回值同样道理。

