




19,318
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
人脸关键点检测指的是用于标定人脸五官和轮廓位置的一系列特征点的检测,是对于人脸形状的稀疏表示。关键点的精确定位可以为后续应用提供十分丰富的信息。因此,人脸关键点检测是人脸分析领域的基础技术之一。许多应用场景(如人脸识别、人脸三维重塑、表情分析等)均将人脸关键点检测作为其前序步骤来实现。本文将通过深度学习的方法来搭建一个人脸关键点检测模型。
1995年,Cootes提出 ASM(active shape model) 模型用于人脸关键点检测,掀起了一波持续多年的研究浪潮。这一阶段的检测算法常常被称为传统方法。2012年,AlexNet 在 ILSVRC 中力压榜眼夺冠,将深度学习带进人们的视野。随后 Sun 等在 2013 年提出了 DCNN 模型,首次将深度方法应用于人脸关键点检测。自此,深度卷积神经网络成为人脸关键点检测的主流工具。本期主要使用 Keras 框架来搭建深度模型。
目前,开源的人脸关键点数据集有很多。例如AFLW、300W、MTFL/MAFL 等,关键点个数也从 5 个到上千个不等。本章中采用的是 CVPR 2018 论文Look at Boundary: A Boundary-Aware Face Alignment Algorithm中提出的 WFLW(wider facial landmarks in-the-wild) 数据集。这一数据集包含了 10000 张人脸信息,其中 7500 张用于训练,剩余 2500 张用于测试。每张人脸图片被标注以 98 个关键点,人脸关键点分布如图1所示。

■ 图1 人脸关键点分布
由于关键点检测在人脸分析任务中的基础性地位,工业界往往拥有标注了更多关键点的数据集。但是由于其商业价值,这些信息一般不会被公开,因此目前开源的数据集还是以 5 点和 68 点为主。在本项目中使用的 98 点数据集不仅能够更加精确地训练模型,同时还可以更加全面地对模型表现进行评估。
然而另一方面,数据集中的图片并不能直接作为模型输入。对于模型来说,输入图片应该是等尺寸且仅包含一张人脸的。但是数据集中的图片常常会包含多个人脸,这就需要首先对数据集进行预处理,使之符合模型的输入要求。
数据集中已经提供了每张人脸所处的矩形框,可以据此确定人脸在图像中的位置,人脸矩形框示意如图2所示。但是直接按照框选部分进行裁剪会导致两个问题:一是矩形框的尺寸不同,裁剪后的图片还是无法作为模型输入;二是矩形框只能保证将关键点包含在内,耳朵、头发等其他人脸特征则排除在外,不利于训练泛化能力强的模型。

■ 图2 人脸矩形框示意
为了解决上述的第一个问题,将矩形框放大为方形框,因为方形图片容易进行等比例缩放而不会导致图像变形。对于第二个问题,则单纯地将方形框的边长延长为原来的1.5倍,以包含更多的脸部信息。相关代码如代码清单1所示。
代码清单1

代码清单1以及其余的全部代码中涉及的 image 对象均为 PIL.Image 类型。PIL(python imaging library) 是一个第三方模块,但是由于其强大的功能与广泛的用户基础,几乎已经被认为是 Python 官方图像处理库了。PIL 不仅为用户提供了 jpg、png、gif 等多种图片类型的支持,还内置了十分强大的图片处理工具集。上面提到的 Image 类型是 PIL 最重要的核心类,除了具备裁剪 (crop) 功能外,还拥有创建缩略图(thumbnail)、通道分离 (split) 与合并 (merge)、缩放 (resize)、转置 (transpose) 等功能。下面给出一个图片缩放的例子,如代码清单2所示。
代码清单2

代码清单2将人脸图片和关键点坐标一并缩放至 128×128px。在 Image.resize()函数的调用中,第一个参数表示缩放的目标尺寸,第二个参数表示缩放所使用的过滤器类型。在默认情况下,过滤器会选用 Image.NEAREST ,其特点是压缩速度快但压缩效果较差。因此,PIL官方文档中建议是如果对于图片处理速度的要求不是那么苛刻,推荐使用 Image.ANTIALIAS 以获得更好的缩放效果。在本项目中,由于 _resize() 函数对每张人脸图片只会调用一次,因此时间复杂度并不是问题。况且图像经过缩放后还要被深度模型学习,缩放效果很可能是决定模型学习效果的关键因素,所以这里选择了 Image.ANTIALIAS 过滤器进行缩放。图2经过裁剪和缩放处理后的效果图如图3所示。

■ 图3 经过裁剪和缩放处理后的效果示意
经过裁剪和缩放处理所得到的数据集已经可以用于模型训练了,但是训练效果并不理想。对于正常图片,模型可以以较高的准确率定位人脸关键点。但是在某些过度曝光或者经过了滤镜处理的图片面前,模型就显得力不从心了。为了提高模型的准确率,这里进一步对数据集进行归一化处理。所谓归一化,就是排除某些变量的影响。例如,希望将所有人脸图片的平均亮度统一,从而排除图片亮度对模型的影响,如代码清单3所示。
代码清单3

mageStat和 ImageEnhance 分别是 PIL 中的两个工具类。顾名思义 ImageStat 可以对图片中每个通道进行统计分析,代码清单3中就对图片的三个通道分别求得了平均值;ImageEnhance 用于图像增强,常见用法包括调整图片的亮度、对比度以及锐度等。
提示/
颜色通道是一种用于保存图像基本颜色信息的数据结构。最常见的 RGB 模式图片由红、绿、蓝三种基本颜色组成。也就是说,RGB 图片中的每个像素都是用这三种颜色的亮度值来表示的。在一些印刷品的设计图中会经常遇到另一种称为 CYMK 的颜色模式,这种模式下的图片包含四个颜色通道,分别表示青、黄、红、黑。PIL 可以自动识别图片文件的颜色模式,因此多数情况下用户并不需要关心图像的颜色模式。但是在对图片应用统计分析或增强处理时,底层操作往往是针对不同通道分别完成的。为了避免因为颜色模式导致的图像失真,用户可以通过 PIL.Image.mode 属性查看被处理图像的颜色模式。
类似地,希望消除人脸朝向所带来的影响。这是因为训练集中朝向左边的人脸明显多于朝向右边的人脸,导致模型对于朝向右侧的人脸识别率较低。具体做法是随机地将人脸图片进行左右翻转,从而在概率上保证朝向不同方向的人脸图片具有近似平均的分布,如代码清单4所示。
代码清单4

图片的翻转比较容易完成,只需要调用 PIL.Image 类的转置方法即可,但是关键点的翻转则需要一些额外的操作。举例来说,左眼 96 号关键点在翻转后会成为新图片的右眼 97 号关键点(见图1),因此其在 pts 数组中的位置也需要从 96 变为 97 。为了实现这样的功能,定义全排列向量 perm 来记录关键点的对应关系。为了方便程序调用, perm 被保存在文件中。但是如果每次调用 _fliplr()函数时都从文件中读取,显然会拖慢函数的执行;而将 perm 作为全局变量加载,又会污染全局变量空间,破坏函数的封装性。这里的解决方案是将 perm 作为函数对象 _fliplr() 的一个属性,从外部加载并始终保存在内存中,如代码清单5所示。
代码清单5

提示/
熟悉 C/C++ 的读者可能会联想到 static 修饰的静态局部变量。很遗憾的是, Python 作为动态语言是没有这种特性的。代码清单5就是为了实现类似效果所做出的一种尝试。
前面定义了对于单张图片的全部处理函数,接下来就只需要遍历数据集并调用即可,如代码清单6所示。由于训练集和测试集在 WFLW 中是分开进行存储的,但是二者的处理流程几乎相同,因此可以将其公共部分抽取出来作为 preprocess()函数进行定义。训练集和测试集共享同一个图片库,其区别仅仅在于人脸关键点的坐标以及人脸矩形框的位置,这些信息被存储在一个描述文件中。preprocess()函数接收这个描述文件流作为参数,依次处理文件中描述的人脸图片,最后将其保存到 dataset 目录下的对应位置。
代码清单6


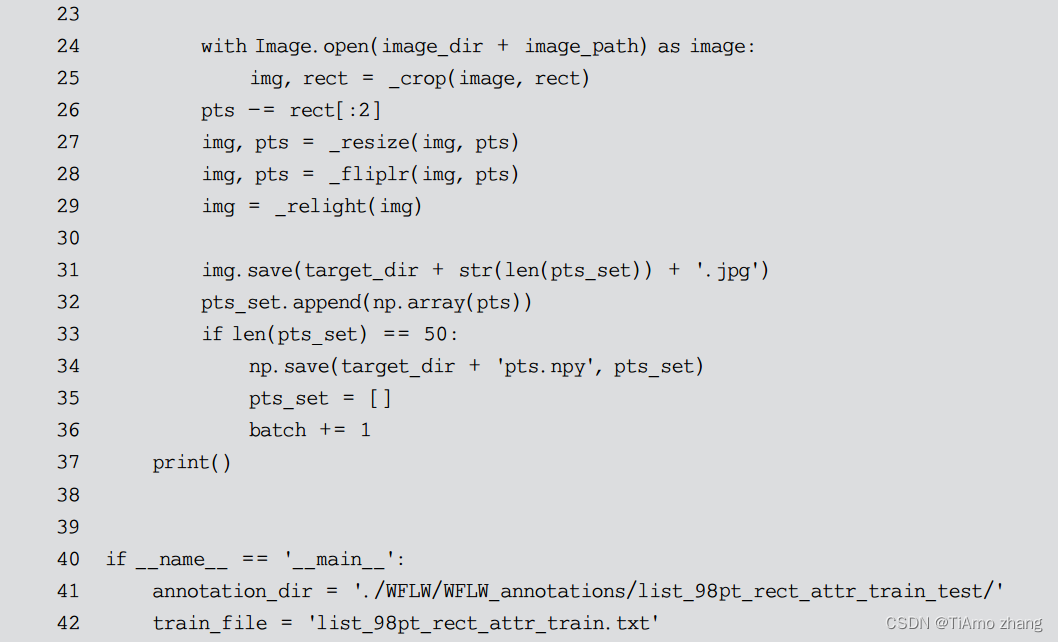

在preprocess()函数中,将 50 个数据组成一批 (batch) 进行存储,这样做的目的是方便模型训练过程中的数据读取。在机器学习中,模型训练往往是以批为单位的,这样不仅可以提高模型训练的效率,还能充分利用 GPU 的并行能力加快训练速度。处理后的目录结构如代码清单7所示。
代码清单7

文末送书
PyTorch深度学习实战 | 基于ResNet的人脸关键点检测 任意评论,3月18日17:00截至,点赞量最高的1位小伙伴,获得《代码的艺术》【中国工信出版集团】*1,后期还有书籍送出,大家敬请期待!



111 想拥抱知识



4





1

