


444
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元针对括号拆分、表达式化简进行迭代,帮助同学们理解Java的基本语法、递归下降思想、面向对象思想等。
第一次作业的任务是针对一个由x,y,z三种变量,通过加、减、乘、幂次、还有括号构成的表达式的建模和展开。下面是作业的形式化表达:
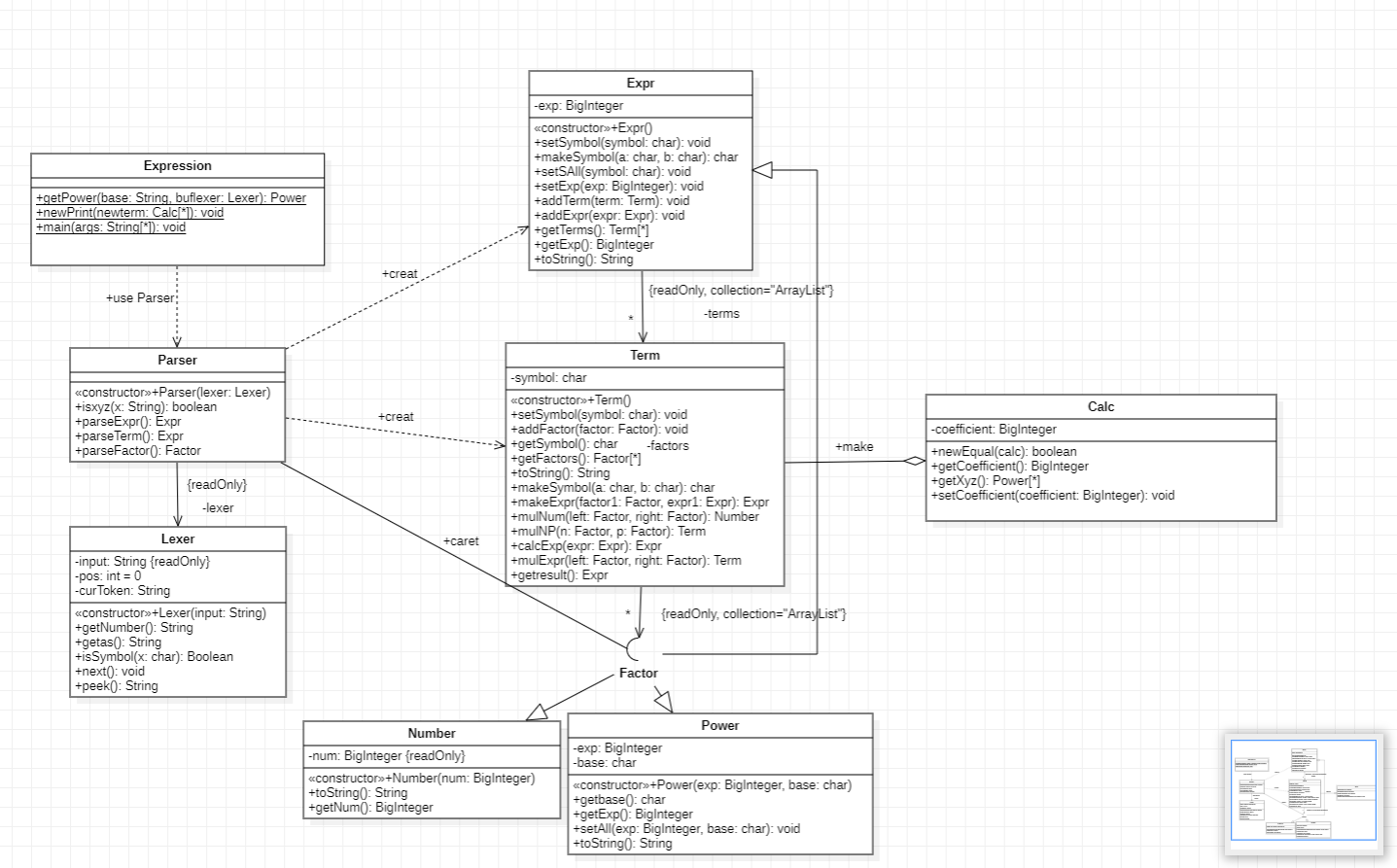
第一次作业较为简单,需要完成的类较少。在完成作业时,我基于实验和提示中的递归下降算法完成本次作业。下面介绍类图中出现的类。
Factor: 接口统一管理所有因子。Number: 常数因子,实现了Factor接口。Power: 变量因子,在这次作业中为幂函数,实现了Factor接口。Expr: 表达式(因子),在作业中我将读入的字符串视为一个指数为1的表达式因子,同样实现了Factor接口。Term: 项,由因子组成,即Arraylist。Calc: 用于加减时合并同类项,形式为 $系数\times x^{m_1}y^{m_2}z^{m_3}$。Parser、lexer:语法分析器、词法分析器,在总结递归下降算法时详解。Parser(语法分析器)和Lexer(词法分析器)实现。Parser中有Lexer属性,Lexer负责把字符串拆成一个个子串提供给Parser,辅助Parser识别子串。在读入表达式后,使用Parser根据Lexer解析的子串,调用对应的Parser方法,构造Expr、Term、fatror等对象。parseTerm()方法得到一个新的Term时,对Term进行乘法运算,将乘法运算得到的表达式作为parseTerm()的返回值,这样最后解析得到的表达式会是一个不含Expr因子的Term的集合。Expr中的Term格式化为了Calc形式,即 $系数\times x^{m_1}y^{m_2}z^{m_3}$。这样合并时只需要依次比较所有Calc的xyz的幂次即可。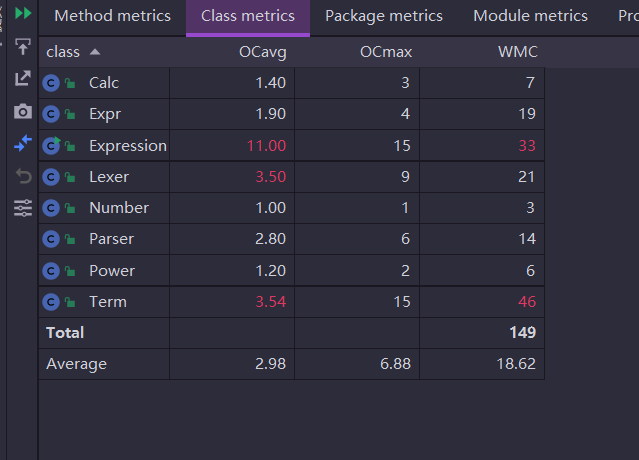

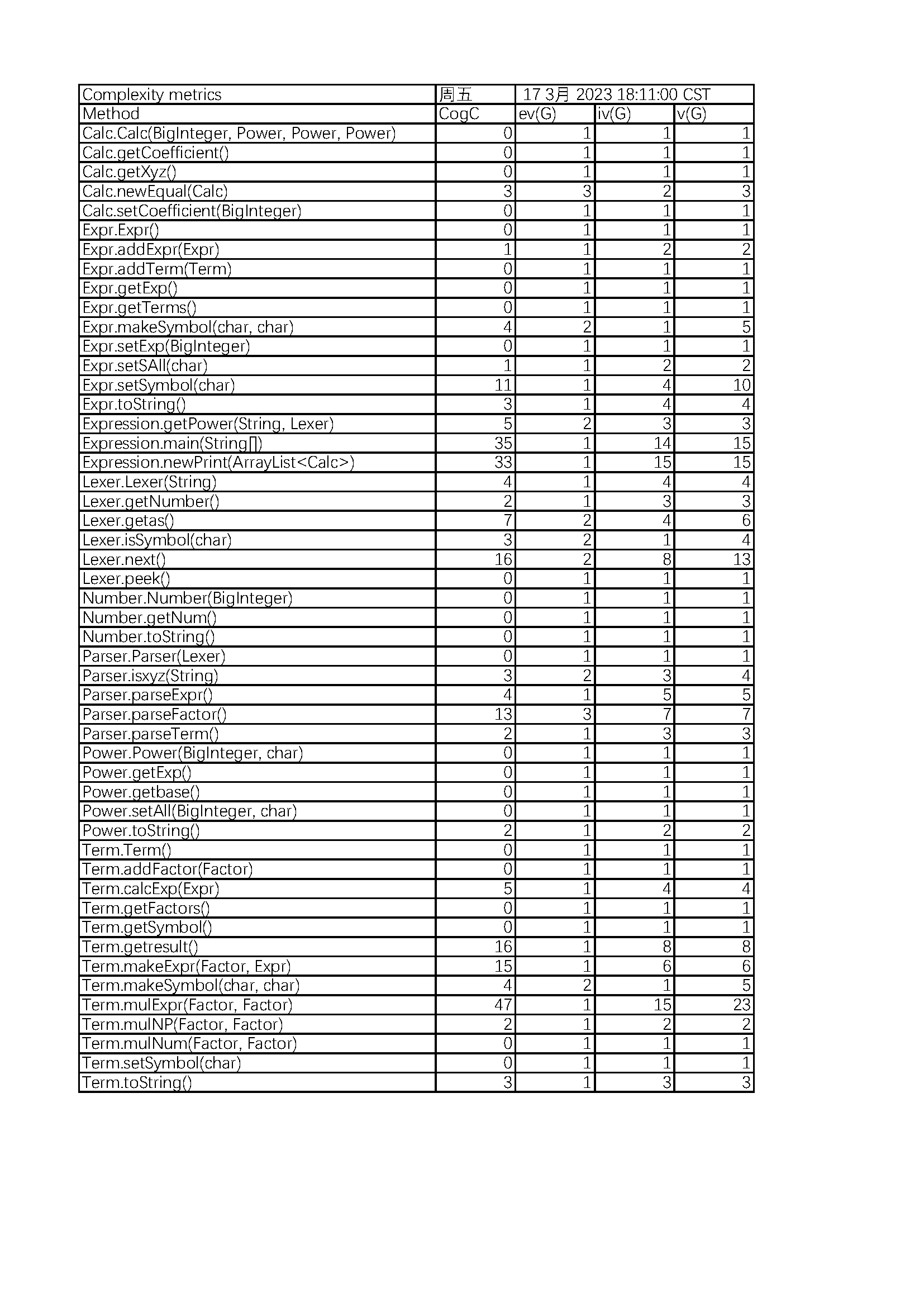
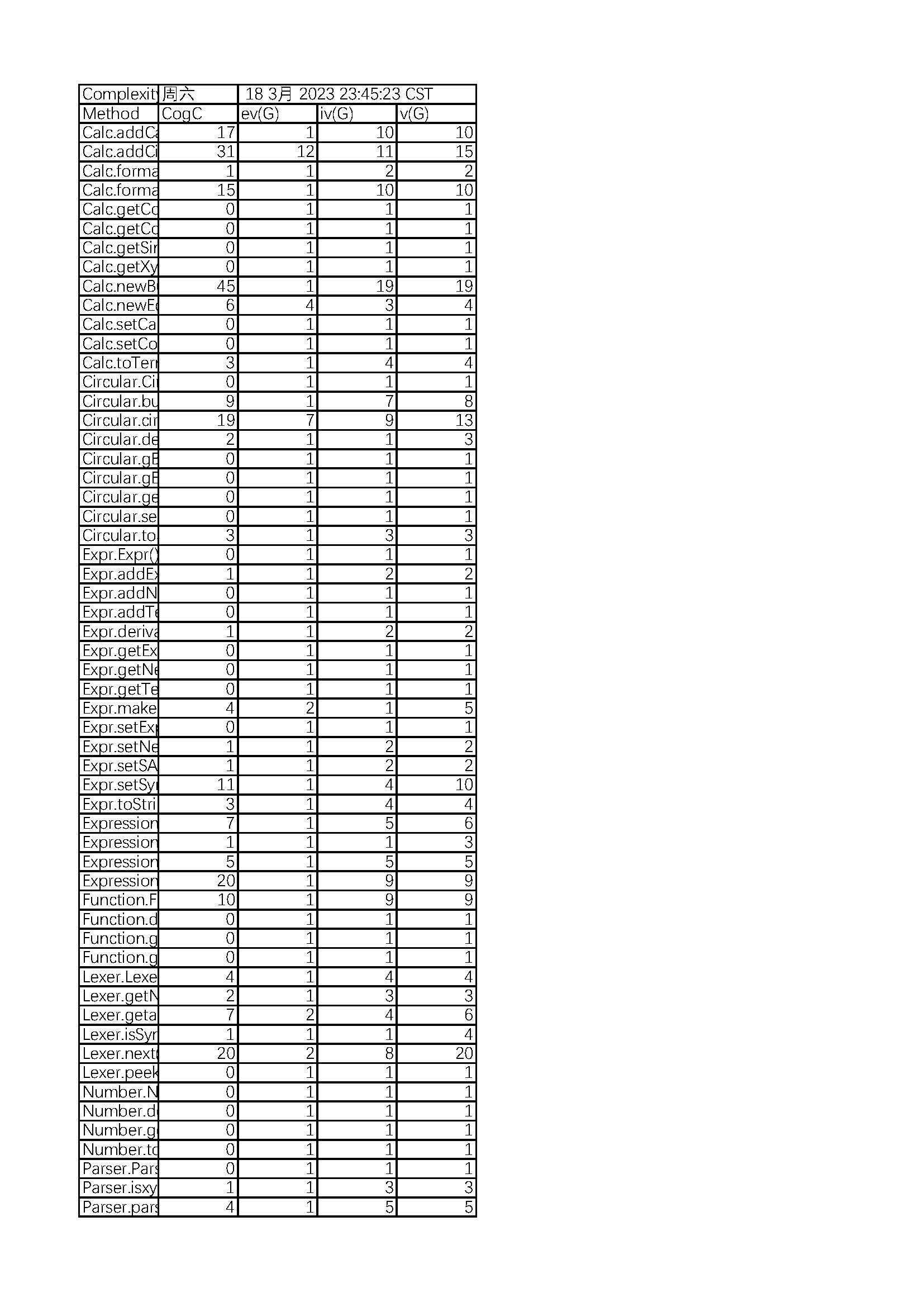
从度量分析可以看出复杂度主要集中在Expression、Lexer、Term三个类中,究其原因是这三个类中方法设计的不合理,出现了许多巨型方法。特别是为了图方便,在主函数中写了过多方法。
Term中实现,使架构较为臃肿,应该将这两个抽象为一个工具类。mulExpr中实现了多个if语句,使该方法成为了巨型方法,应该将该方法作为一个入口,具体实现细节应该在多个不同的方法中实现。Expr中是Term的容器,但最后化简和输出是要使用的Calc容器,代码缺乏统一性。bug分析x**0=0和负的常数因子无法识别符号等。两个bug分别出现在newprint和parseFactor方法中,两个的圈复杂度分别为7和15,均高于平均值。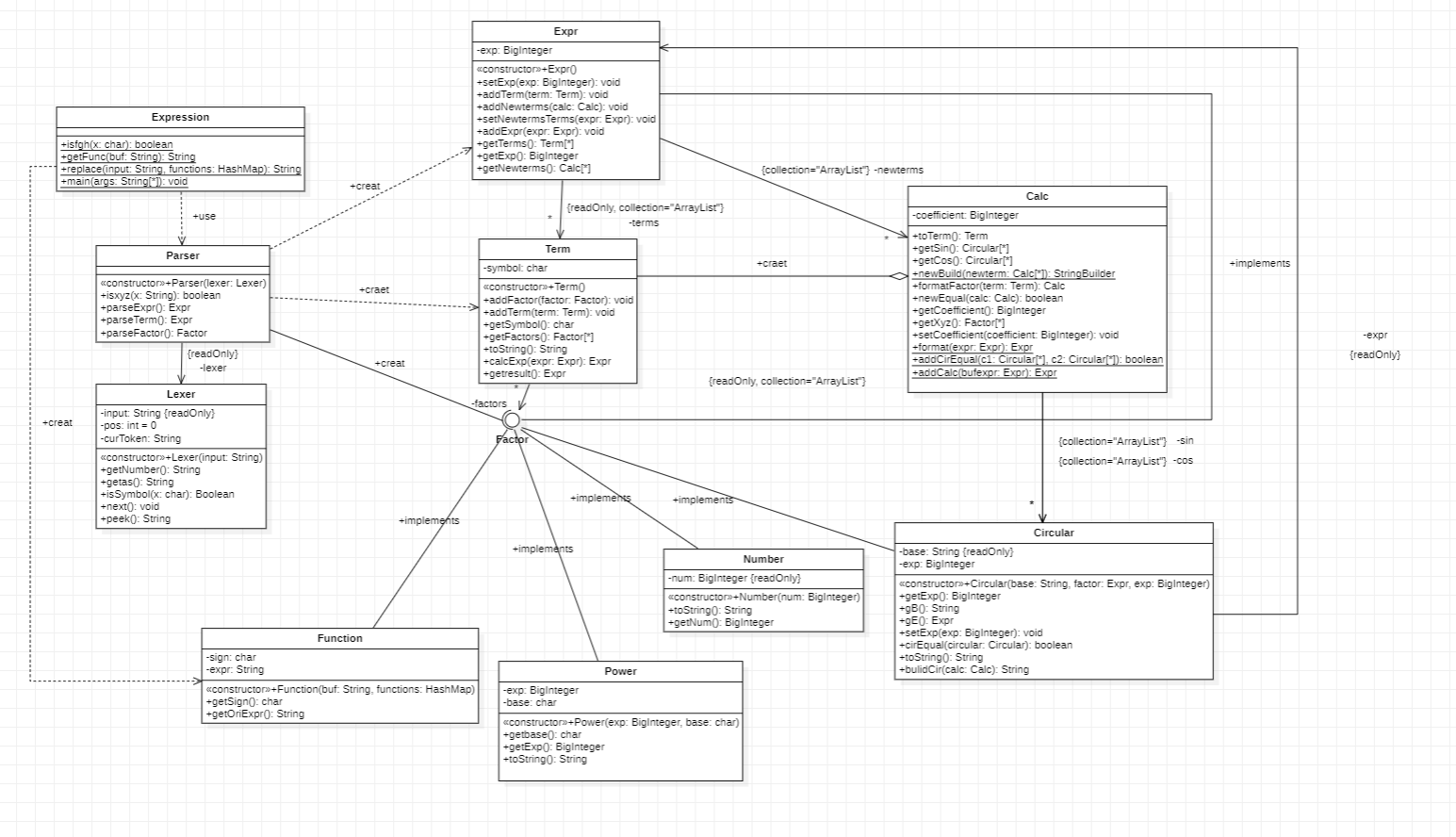
这次作业为解决三角函数和函数调用问题,新增了两个类:
Function: 用于装载自定义函数,将函数表达式和函数形参建立联系。Circular: 三角函数类,实现了Factor接口。具体属性如下: private final String base;//用于辨认sin和cos
private final Expr expr;//记录三角函数中因子
private BigInteger exp;//记录指数
本次采用字符串替换解决自定义函数问题,具体实现是设置一个Function类,Function类属性为:
private char sign;//记录函数名(f|g|h)
private String expr;//记录函数表达式
在读入函数定义时,将表达式中的形参依次替换为u、v、w,并储存在一个Function中的expr里。在函数调用时,再将u、v、w依次替换为因子。比如:
读入函数f(x,z,y) = x+y+z,储存为f(u,v,w) = u+w+v
调用f(sin(x),z,y),整体替换为sin(x)+y+z
对于三角函数,我新设了一个Circular类,具体定义在程序结构已经解释。而在处理三角函数一个重要的问题是如何判断两个三角函数中的表达式是否相等,为了处理这个问题,我选择在递归下降途中进行加减法化简,保证三角函数中的表达式形式唯一,正常遍历比较即可判断两个三角函数中的表达式是否相等。具体实现是在Expr中设置了一个新的属性:
private ArrayList<Calc> newterms;
在parseExpr()得到一个新的Expr时,先将这个表达式格式化为Calc形式,再根据newterms进行加减法化简,实现表达式唯一性。
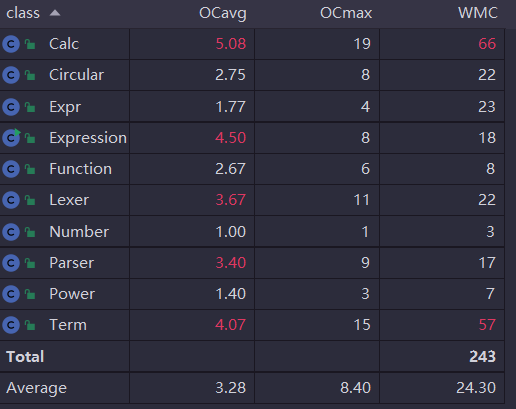

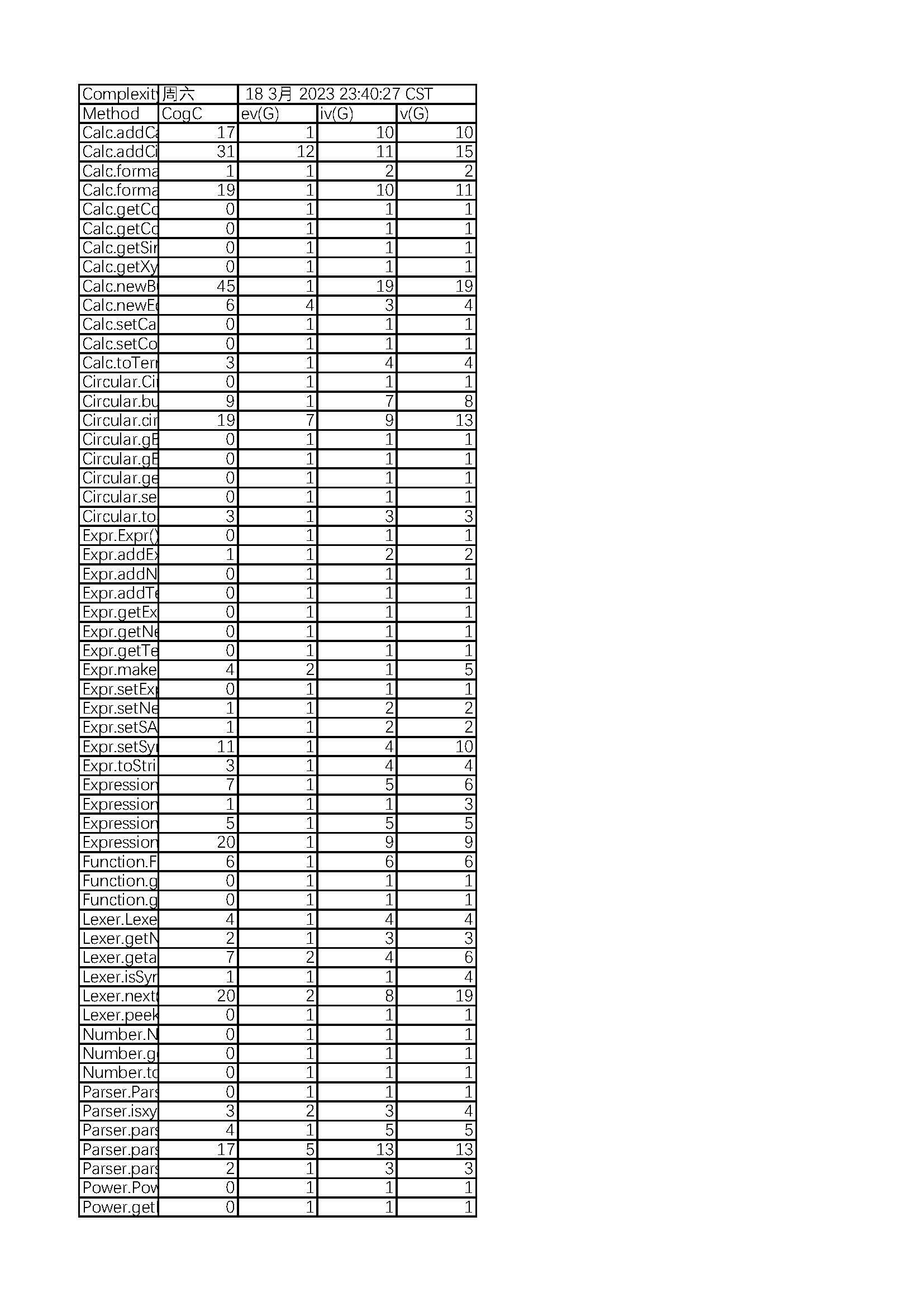
由于需要分析的语法增加,Parser和Lexer的复杂度不可避免地增加,但Term和Calc的复杂度过大是由于我将加减法和乘法加入该类中,并未把他抽象为一个新的工具类。而且因为我并未实现表达式的排序和哈希值编写,所以我所有设计表达式的比较都是使用了双层循环,这导致了我所有涉及比较的函数复杂度极高。
我认为本次作业的我的架构极为糟糕,巨型类和方法较多,许多行为并未抽象成新的类。类于类之间的耦合度过高,许多方法的条件分支过多,导致我在代码维护和检测时都遇到了极大的困难。
sin(0)**0输出错误,浅克隆,函数调用时出现空白字符会死循环等。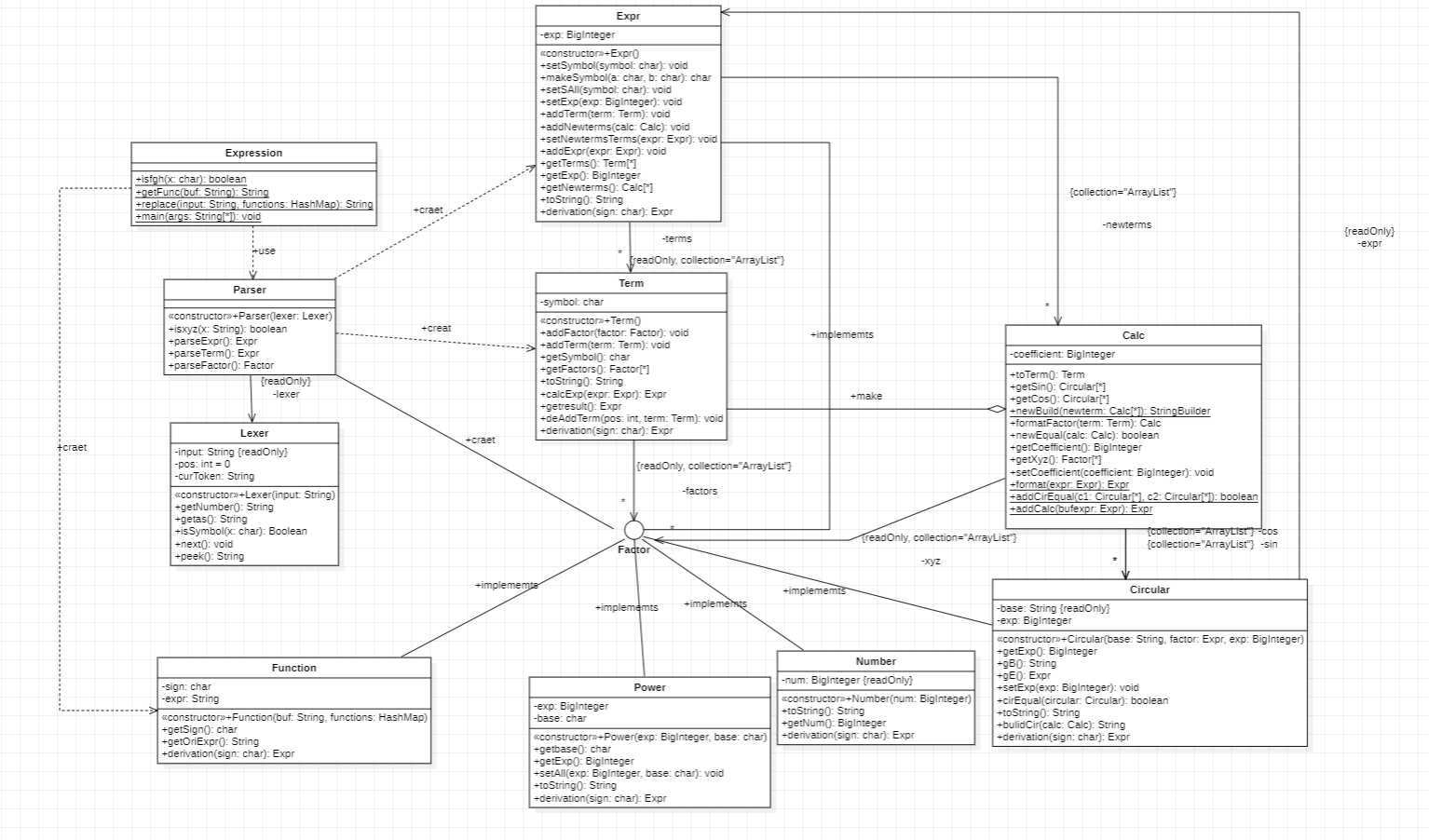
本次作业增加类容较少,程序结构并未发生过多的改变,主要是实现新的函数。
Expr转化为字符串储存在Function中,之后的流程与第二次作业几乎相同。Factor中定义求导方法derivation,在Factor的各个不同实现中重写不同的求导规则,最后直接对求导因子中的表达式调用方法即可得到结果。下面是各个类的求导方法:Expr: 由于在求导因子的表达式解析中一定化简了乘法,所以Expr的指数一定为1,只需要对Expr中的每一个Term调用求导方法,返回值为表达式。Term: 对Term使用乘法法则,即遍历所有因子,每次循环时,对当前因子求导,保留其他因子,伪代码如下:public Expr derivation(){
Expr expr = new Expr();
for(Factor factor : this.getFactors){
Term term = new Term();
term.addTerm(otherFactors);
term.addFactor(factor.derivation());
//处理符号函数(有一定篇幅,此处省略)
expr.addTerm(term);
}
return expr;
}
Number:常数因子的求导为0。Power:幂函数求导只需要将整体乘以指数,再将指数减一即可。Circular:三角函数的求导较为复杂,需要考虑指数,链式求导,函数名变化,伪代码如下:public Expr derivation() {
Expr expr = new Expr();
Term term = new Term();
String base = (this.base.equals("sin")) ? "cos" : "sin";//处理函数名
term.addFactor(new Number(this.exp));//最外层的幂函数求导
term.addFactor(new Circular(this.base, this.expr, this.exp.subtract(BigInteger.ONE)));//最外层的幂函数求导
term.addFactor(new Circular(base, this.expr, BigInteger.ONE));//三角函数求导
term.addFactor(this.expr.derivation());//对三角函数内表达式求导
//处理符号函数(有一定篇幅,此处省略)
expr.addExpr(bufexpr);
return expr;
}
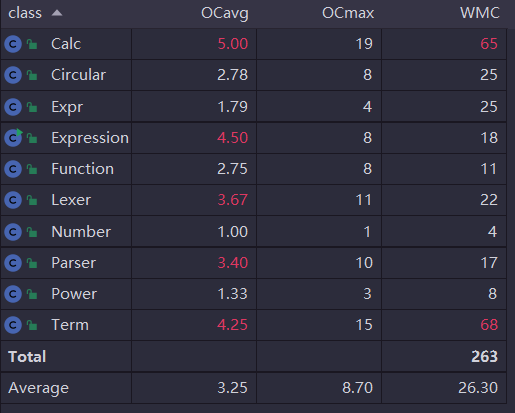

本次因为作业类容简单,我没有进行重构,所有不论是代码规模,类复杂度还是方法复杂度都雪上加霜,特别是对函数表达式还要进一步解析,导致主函数和Function类的复杂度极高
因为为进行重构,我程序的架构整体上还是挺糟糕的,但对于求导因子解析的架构我自认为还是比较清晰的。对于每一个类都统一接口,重写求导方法,使程序处理求导时调用方法形式较为统一。
在本次作业,自己的程序和同房的程序都没有发现什么bug,比较常见的还是对函数定义采取字符串处理而导致的卡性能型bug。
int范围的大数,0次幂等在经历第一单元的作业后,我觉得动笔写代码前的架构设计还是值得花费大量时间去思考的,第一次作业写作前,只思考了递归下降的架构,剩下的乘法和加减法并未深思,导致这方面的架构问题重重,巨型方法扎堆,甚至写进了主函数,测试结构也反映了bug多数都是藏在这些不完善的架构中。的二次作业倒是对第一次作业进行了部分重构,将加法整理进Calc类,乘法整理进Term类,但仍然没有对本单元新增的任务进行结构分析,导致错误频出。第三次作业倒是依靠第二次作业时激烈的互测幸免于难,侥幸无伤过关,但架构问题还是值得我在下次作业时认真思考的。
同时我认为java的知识储备还需增强,因为不熟悉HashMap和TreeMap的使用,我第一单元走了很多弯路,并遇到了极难化简、比较和查找的问题。为此,我应该夯实基础,不断弥补自身的不足,写出更加完善的项目。



