



688
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2023年福大-软件工程实践-W班 |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业--编程实现 |
| 结对学号 | 222000429&052006130 |
| 这个作业的目标 | 1.学会结对使用gitcode 2.网页部署 3.网页代码的实现 |
| 其他参考文献 | 《构建之法》 |
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 685 | 660 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 90 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 20 | 15 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| • Design | • 具体设计 | 120 | 100 |
| • Coding | • 具体编码 | 300 | 330 |
| • Code Review | • 代码复审 | 60 | 50 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| Reporting | 报告 | 40 | 45 |
| • Test Repor | • 测试报告 | 10 | 10 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 755 | 740 |


由于时间问题,仅实现了day1和day2的切换


由于时间问题,仅实现了day1的前两个


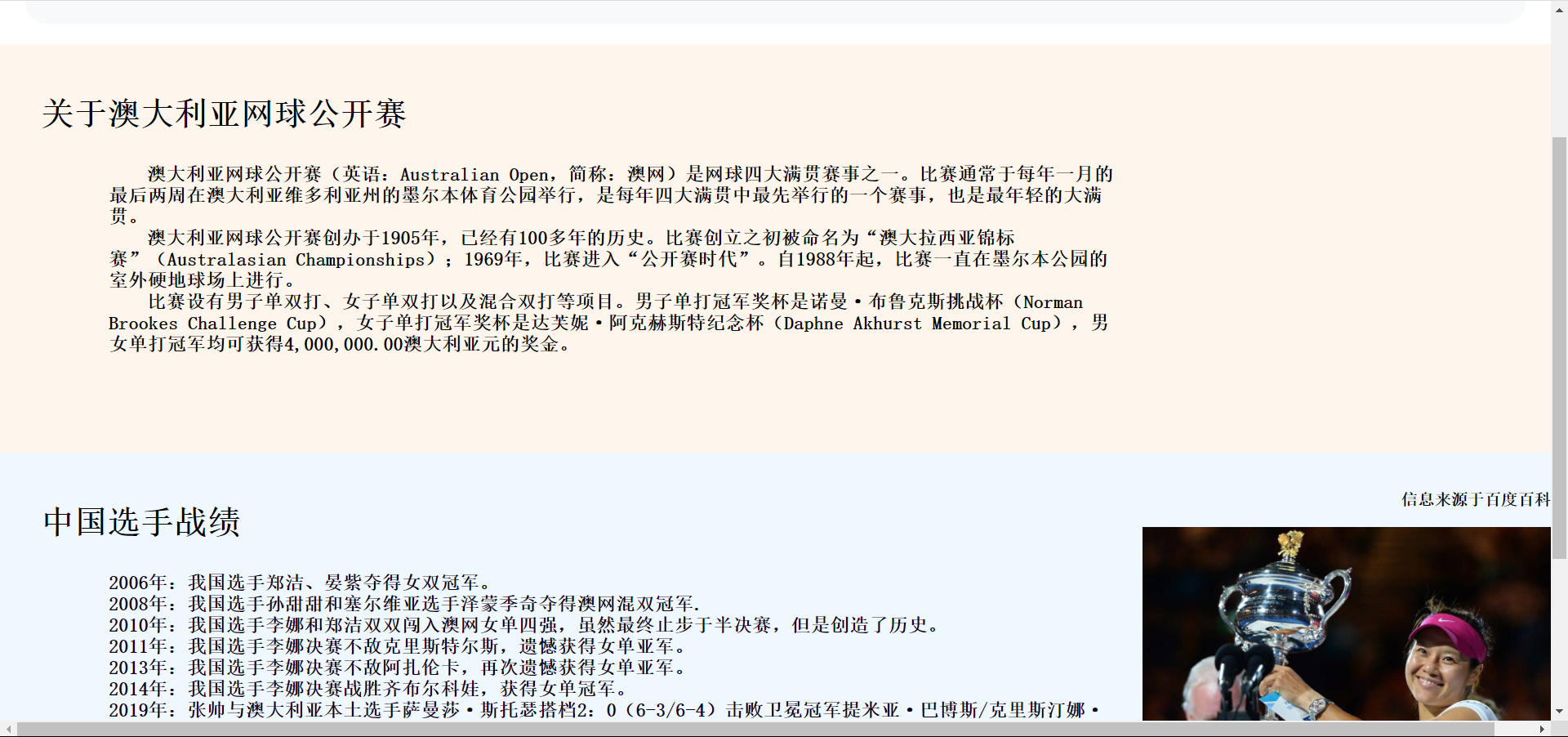

(1)首先,我们先讨论确定了大致的分工:222000429负责页面的展示实现,052006130负责数据的填充及页面跳转等动态功能。
(2)其次,我们讨论了具体功能的实现顺序,先实现基本功能,再实现一些我们觉得需要实现的功能,最后才实现一些我们认为可以实现与否对整个网站影响较小的功能。
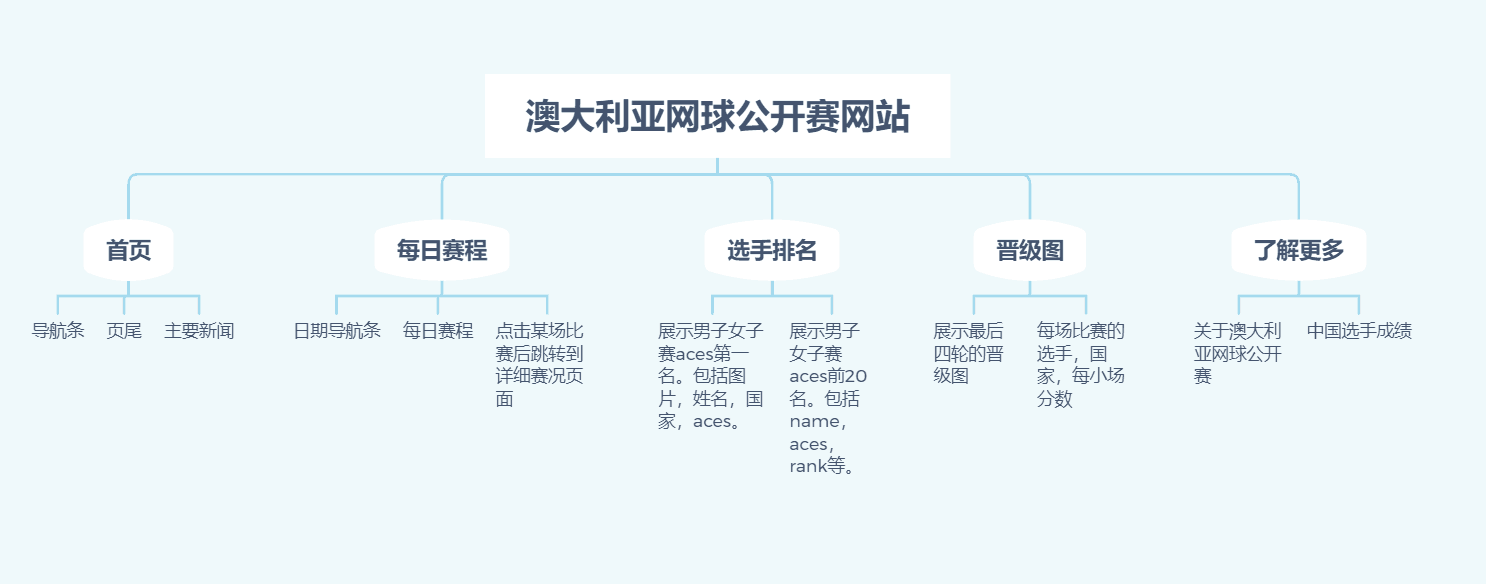
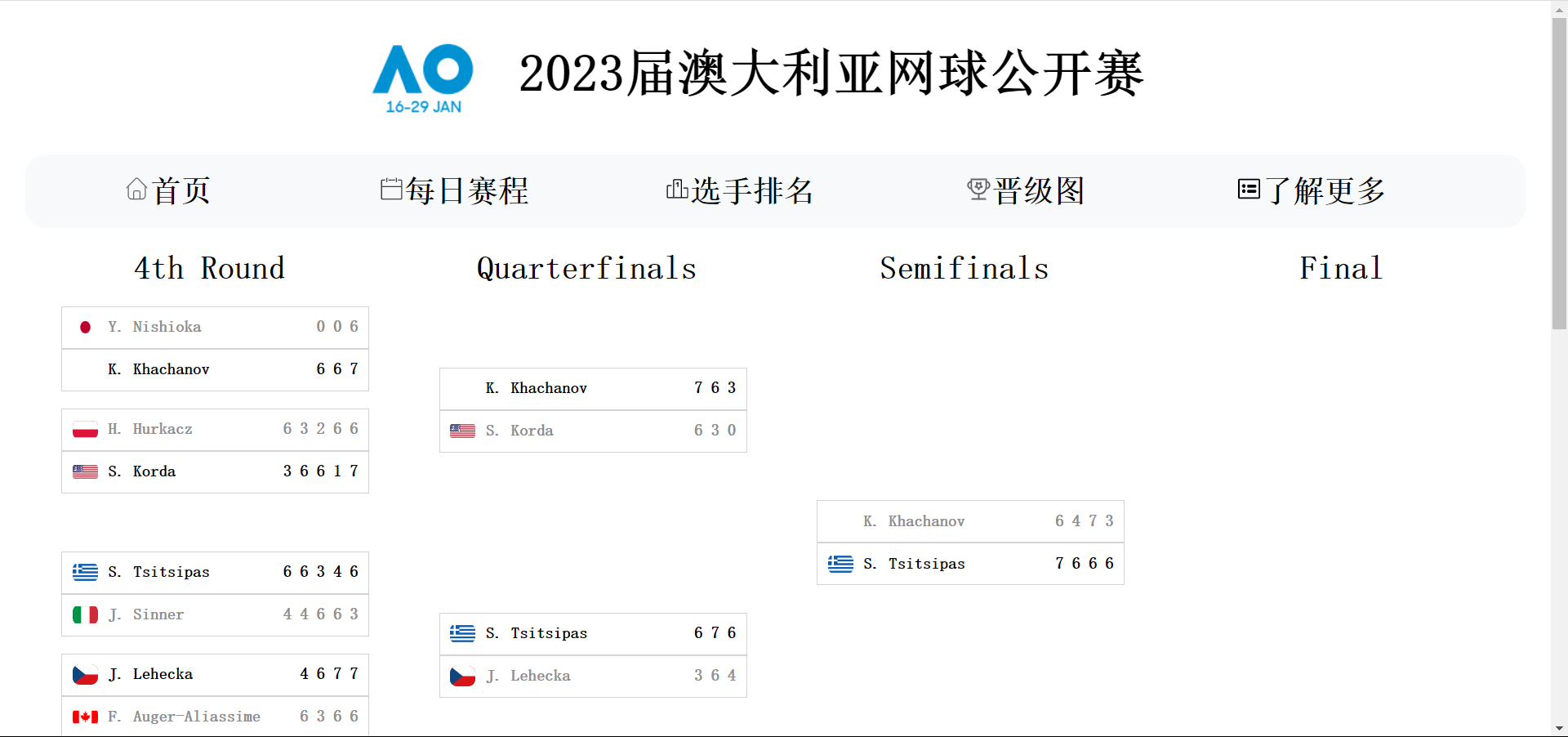
功能结构图
(3)然后我们就是按照分工去实现各自的东西,并实时将实现后的东西给对方展示,以免一些讨论时语言的错误使得对方理解有偏差导致最后的功能不能使双方都满意。
(1)首先是222000429先将页面的html代码写出来,将大致需要传的数据的位置先用一个模板数据占住位置,并将哪些位置需要传数据告诉052006130。
(2)然后就是共同coding阶段。222000429写别的页面的html代码,052006130将已有页面的数据传入并对页面的一些小位置进行改动。
(3)然后当所有页面都写完后,两人共同对页面进行查缺补漏。
(4)将代码部署到云服务器上。
实现方法:通过传入的的dayIndex,将该dayIndex的面板的display设置为block,即展示出来;并利用for循环将其他的面板的display设置为none,即隐藏起来
<script>
function showDay(dayIndex) {
// 隐藏所有day元素
const days = document.getElementsByClassName('day');
for (let i = 0; i < days.length; i++) {
days[i].style.display = 'none';
}
// 显示指定的day元素
const day = document.getElementById(`day${dayIndex}`);
day.style.display = 'block';
}
</script>
实现方法:如果是<--按钮则将scroll_nav_1的hidden设置为false、scroll_nav_2的hidden设置为true,即将第一个导航条显示出来,第二个导航条隐藏起来;如果是-->按钮则将scroll_nav_2的hidden设置为false、scroll_nav_1的hidden设置为true,即将第一个导航条隐藏起来,第二个导航条显示出来。
<script>
const scrollNav = document.getElementById('scroll_nav');
const nav1 = document.getElementById('scroll_nav_1');
const nav2 = document.getElementById('scroll_nav_2');
// 隐藏第二个导航栏
nav2.hidden = true;
scrollNav.addEventListener('click', (event) => {
// 检查点击的元素是否是导航栏的左右箭头
if (event.target.tagName === 'SPAN') {
const direction = event.target.textContent;
if (direction === '<--') {
// 显示第一个导航栏,隐藏第二个导航栏
nav1.hidden = false;
nav2.hidden = true;
}
else if (direction === '-->') {
// 显示第二个导航栏,隐藏第一个导航栏
nav1.hidden = true;
nav2.hidden = false;
}
}
});
</script>
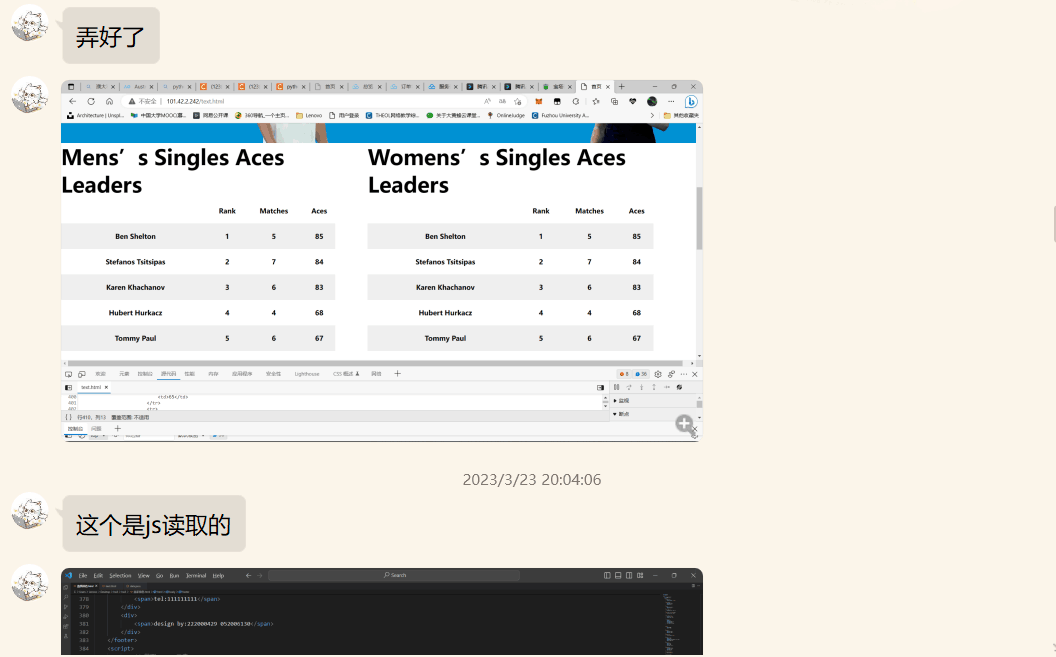
实现方法:利用js获取到要填入数据的区域,再读出json文件里的所需数据,将其填入指定区域(此处为了json文件读取方便,先利用python对原json文件进行了处理,将json文件里需要的数据先提取到新json文件,使得js读取时可以直接读新json文件的数据)
<script>
// 获取 HTML 元素
const nameElement = document.querySelectorAll('.event-stat-table__name');
const rankElement = document.querySelectorAll('.rank');
const matchElement = document.querySelectorAll('.matches');
const aceElement = document.querySelectorAll('.aces');
fetch('men_final_result.json')
.then(response => response.json())
.then(data => {
// 将对象转换为数组
const dataArray = Object.keys(data).map(key => {
return {
id: key,
name: data[key].name,
rank: data[key].Rank,
matches: data[key].Matches,
aces: data[key].Aces
}
});
// 更新 HTML 元素
for(let i=0;i<nameElement.length;i++) {
nameElement[i].textContent = dataArray[i].name;
rankElement[i].textContent = dataArray[i].rank;
matchElement[i].textContent = dataArray[i].matches;
aceElement[i].textContent = dataArray[i].aces;
}
})
.catch(error => console.error(error));
</script>
实现方法:利用python爬虫爬取详细赛况里面的数据,然后将数据转换为json格式,传入前端对应需要填入数据的区域。
该爬取仅用于学习
原网页的数据格式为:
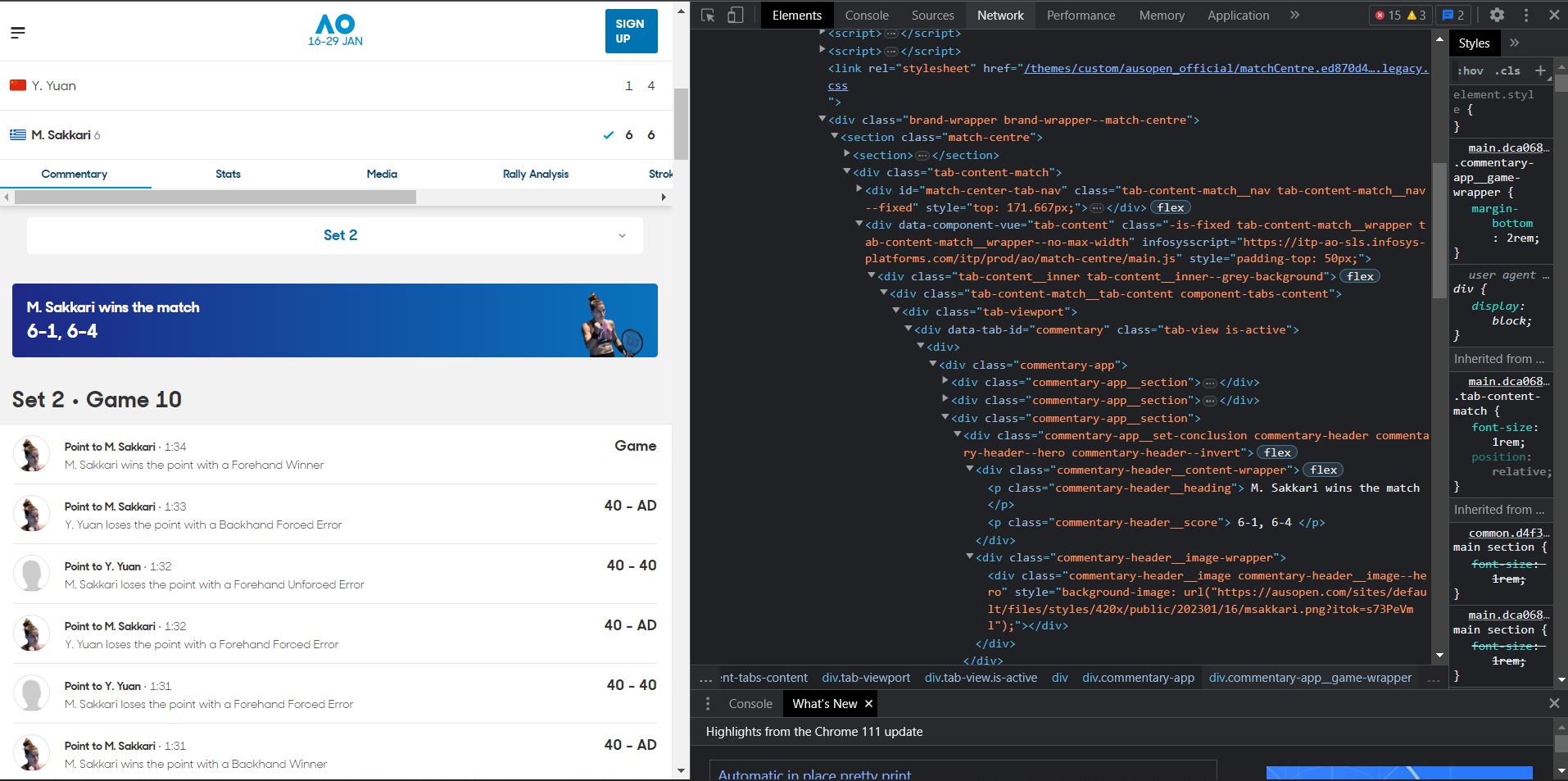
注意:我们在爬取数据的过程中发现,这个网页的数据是动态生成的,并不同于简单的静态数据可以直接获取到,需要使用python的模拟请求网站才可以获取到真实的数据内容。
以下是处理数据的核心代码:
from bs4 import BeautifulSoup
import json
soup = BeautifulSoup(html, "html.parser")
comments = soup.find_all("div", class_="commentary-row")
# 定义空列表,用于存储每条评论的信息
data = []
# 遍历评论列表并输出
for comment in comments:
# # 获取时间
# time = comment.find('p', class_='commentary-row__heading').span.text.strip()
#
# 获取球员姓名
player_name = comment.find('p', class_='commentary-row__heading').text.strip()
# 获取球员图片链接
player_image = comment.find('div', class_='commentary-row__image')['style']
player_image = player_image.replace('background-image: url(', '').replace(');', '').replace('"', '')
# 获取比分情况
score = comment.find('p', class_='commentary-row__score')
if score:
score = score.text.strip()
else:
score = ''
# 获取评论内容
text = comment.find('p', class_='commentary-row__commentary')
if text:
text = text.text.strip()
else:
text = ''
# 输出评论信息
print(f'Player Name_time: {player_name}\nPlayer Image: {player_image}\nScore: {score}\nText: {text}\n')
# 将评论信息添加到列表中
data.append({
# 'Time': time,
'Player Name': player_name,
'Player Image': player_image,
'Score': score,
'Text': text
})
# 将列表转换为 JSON 格式的字符串
json_data = json.dumps(data)
# 将 JSON 格式的字符串写入文件
with open('data_2.json', 'w') as f:
f.write(json_data)
# 输出提示信息
print('Data saved to data.json')
实现方法:我们采用了Caddy进行服务器的部署而替代了传统的Nginx+Apache,这款框架对于部署轻量级网页还是十分友好和便捷的,我们最终经过商量讨论还是选择了这款框架。另一方面,我们租用的服务器平台为腾讯云服务器,既具备自主开发的远程操作的可视化面板,同时也集成了宝塔面板;使得整体操作都十分的方便容易。
下图是我们的宝塔面板:
下图是我们部署网站的框架:Caddy
在刚开始看到这个作业的时候,感觉实现方法清晰明了,但当真正实现的时候才发现困难多多。由于组内两个人都对前端不是很感兴趣,导致实现的时候很多东西都需要现学才可以勉强完成,虽然如此,但最后做出来的东西还算是可以,不至于非常差劲。通过这次作业,收获了更多的前端经历(
也让自己更加坚定地选择后端)。其次,通过本次的实践,让我们对js的应用有了一个更直观的理解和认识,通过合理利用js,一方面可以大大简化重复性的代码量;同时也让前端代码有了逻辑功能;最后,我们还学会了如何部署一个网站在云服务器上,这对于未来的开发有很大帮助。
222000429->052006130:该同学的知识面很广,虽然自己的后续方向是深度学习方向,但对于前端的网页部署、前端的一些框架都有一定的了解,与该同学结对很放心!
052006130->222000429:该同学虽然对前端的框架不是很了解,但是该同学比较耐心,对于一些框架能简便实现,但由于时间不够无法学习框架时,她采用了最原始的方法实现了功能,并且命名合理易懂,为我后续实现数据传入提供了便利。

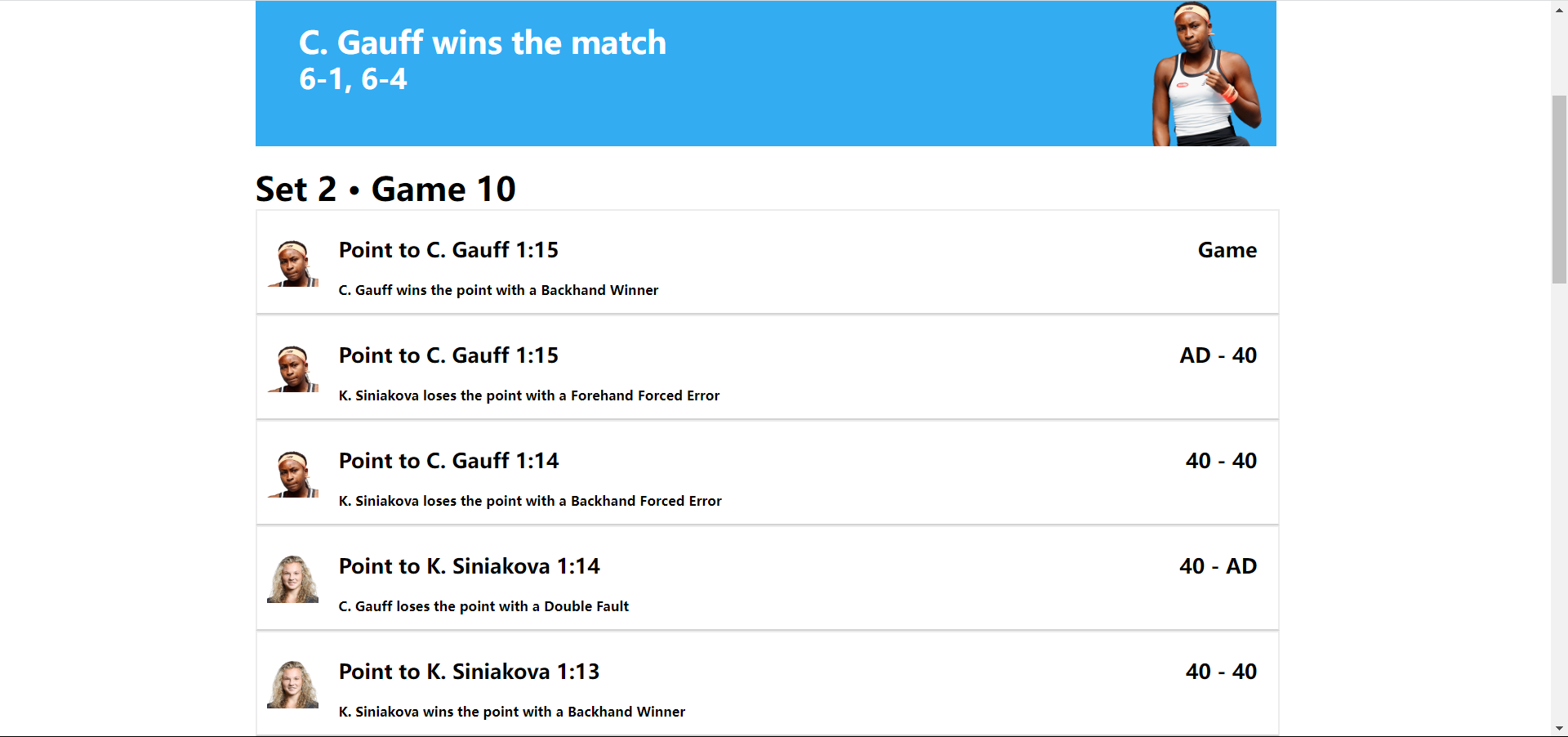
1.每日赛程的详细赛况,选择set1无效;
2.晋级图未连线,晋级选手不够突出;
3.借助Chat GPT学习前端框架,很赞!建议写一篇博客,记录自己学习过程,同时也能帮助更多学习者。


