


8
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享PNAS重磅:词向量带你洞悉美国性别与种族歧视百年历史演变
性别歧视、种族歧视都是存在了上百年的社会现象,这些现象在不同历史时期有怎样的发展变化呢?发表在《美国国家科学院院刊》(PNAS)的一篇论文中,研究者用词向量的方法研究大量文本数据,挖掘出美国近一百年文化刻板印象的演化。下面是对这篇论文的解读。
论文题目:Word Embeddings Quantify 100 Years of Gender and Ethnic Stereotypes论文作者:Nikhil Garg,Londa Schiebinge,Dan Jurafsky,James Zou论文地址:http://www.pnas.org/content/115/16/E3635/tab-article-info
对性别和种族刻板印象的研究是许多学科的一个重要课题。语言分析作为一种标准工具,被用于发现、理解和呈现这些刻板印象(1-5)。以前的文献总体上认为,语言既反映又延续了文化刻板印象。然而,这些研究主要利用人类调查(6,7)、字典和定性分析(8),或对不同语言的深入了解(9)。这些方法往往需要耗费时间和昂贵的人工分析,而且可能不容易跨越不同时间段和语言来研究各种刻板印象。
 How Decision Bias Works by Ashley Siebels
How Decision Bias Works by Ashley Siebels
本文采用了一种新的方法,使用词向量对历史趋势进行定量研究——这里着重探讨了20世纪和21世纪,美国在性别和种族两方面刻板印象的发展趋势。研究结果展示了特定的偏见随着时间推移而减少的趋势,也展示了其他类型的刻板印象随时间增加的现象。此外,词向量所展示出的历史动态与美国社会的人口和职业变化也有着密切的关系。例如,在20世纪60年代至70年代的妇女运动和1960年代和1980年代亚裔美国人口增长期间,性别和种族群体相关的描述都发生了变化。
词向量简单回顾:在词向量模型中,给定语言中的每个单词都被转换成一个高维向量,向量的普通计算就能够捕捉词语之间的语义关系。例如,在向量空间中更为接近的向量被证明对应于更相似的词(10)。这些模型通常在大型的文本语料库上自动进行无监督训练,例如谷歌新闻文章或维基百科合集,而且它们捕捉到的关系不是通过简单的共现分析找到的。例如,法国的向量与奥地利和意大利的向量在向量空间上相近,而XBox的向量接近于PlayStation(10)。除了向量空间中的近邻,词向量也可以捕获更多的词汇之间的全局关系。伦敦减去英格兰,约等于巴黎减去法国。这种模式允许词向量来捕捉类比关系,例如伦敦之于英格兰就像巴黎之于法国。
研究数据
为了分析现当代的性别和种族刻板印象,本文使用在谷歌新闻数据集上训练的标准谷歌新闻词向量(Google News word2vec Vectors, 11)。同时,作者使用了在谷歌图书/COHA(美国历史英语语料库)上训练的词向量来分析历史的发展趋势,这些词向量以10年为单位,一共有9组 (12)。另外,为了进一步验证,作者使用GLoVe算法(13)在1988至2005年的纽约时报标注文本(14)中训练了词向量。
然后作者整理了几个单词列表,分别代表性别(男性和女性)、种族(白人、亚裔和拉丁裔),以及中性词汇(形容词和职业)。 对于职业,研究者们使用美国历史普查数据(15)来提取每个职业中每个性别或种族群体的劳动者比例,并将其与词向量中的偏差进行比较。
词向量偏差,是指两组词表(男性和女性、白人和亚裔)与一个中性词表的偏差,它是由相对范数差(relative norm difference)来度量。其计算方法如下: (a)在给定的性别或种族词表中,所有词向量的平均值作为该组的代表向量; (b)计算每个代表向量与中性词表中每个矢量之间差异的平均l2范数;(c)相对范数差是平均l2范数的差异。
这个度量指标测量在性别和种族群体词汇与中性词之间的相对距离(也就是相对的关联强度,参见下列公式)。??
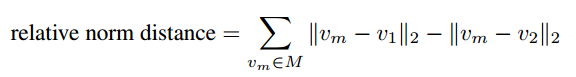
验证词向量偏差
为了验证词向量中的偏差是否准确地反映了社会趋势,文中对比了词向量趋势与人口普查中职业参与比例的趋势。
与女性职业参与比例的比较
图1a与图1b展示了词向量偏差与女性在特定职业的就业参与比例的关系。
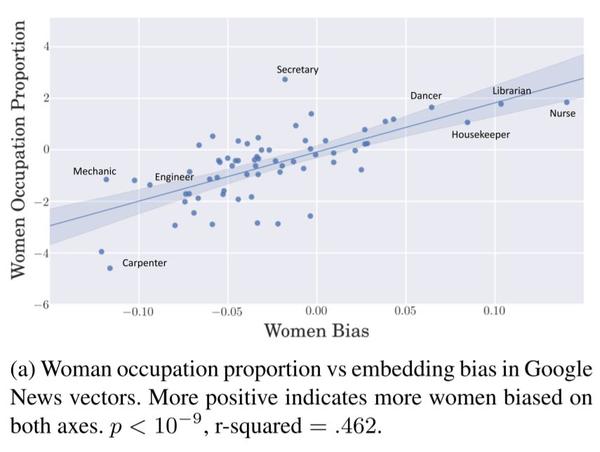 图1a
图1a
纵坐标轴为女性与男性在特定职业参与比例的log值,这个值是统计数据。通俗的来解释,纵坐标为正值y时,从业人员的男女比例大概是1:10^y;纵坐标为负值时,男女比例为1:10^-y。例如,在纵坐标为-4的点,图中的木匠(Carpenter)这一职业的男女比例大致为10000:1。而在纵坐标为2,图中的护士(Nurse)这一职业中,男女比例大概为1:100。
而横坐标展示了本文所使用的词向量方法计算出来的男女职业偏差值,所使用的语料库是谷歌新闻。图中每个点都是一个职业,可以明显看出词向量偏差与就业比例成正相关,这基本能够证明词向量偏差这一测量指标的有效性。
更有意思的是,根据这两个值做出的回归线(图中直线)经过了原点,也就是男女就业比例为1:1的行业在词向量中也不存在明显差异,这说明了词向量偏差能较好的匹配到统计数据中男女就业比例的不同幅度。
为了证实以上结果并不依赖特定历史时期,原文还分析了上文提到的基于COHA语料库1910~1990的9组词向量,并得到了类似的结果。相关内容可以在原文的附录B2部分查阅。
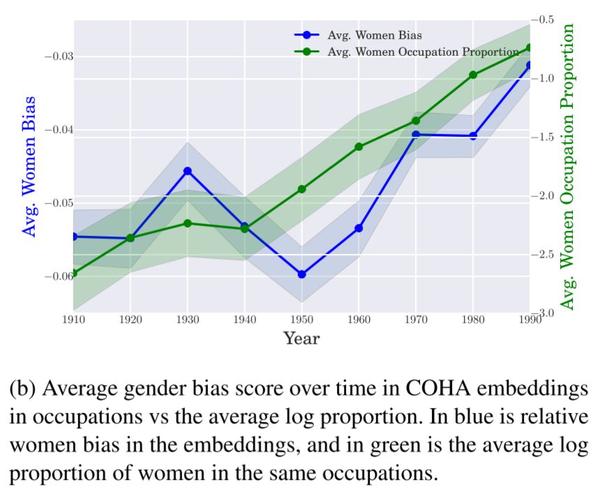 图1b
图1b
接下来,作者考察了1910-1990年间词向量的变化,观察结果是否可以反映妇女职业参与比例的变化。
图1b 显示了随着时间的推移,平均(指对各种不同职业的词向量取平均值)词向量的偏差(图中蓝色实线),与女性职业参与平均比例值的变化(指不同职业参与比例的平均值)。
随着时间的推移,词向量偏差与职业比例密切相关。平均偏差是负的,这意味着职业与男性的联系比女性更为密切。然而,作者发现,从20世纪50年代到20世纪90年代,这种偏见逐渐接近于0,这表明偏见正在减少。这一趋势与妇女在这些职业中参与比例增加的趋势相吻合。
图1c与图1d展示了不同种族在就业方面的一些情况。
 图1c
图1c
与性别偏见类似,种族词向量捕捉到可被外部验证的种族偏见。 图1c 显示了词向量中最偏向于拉丁裔、亚裔和白人姓氏的十种职业。亚裔美国人“模范少数族裔”的刻板印象占据了主导地位(16);教授、科学家和物理学家等学术职位似乎都是最偏向于亚裔的职业。同样,白人和拉丁裔的刻板印象也出现在他们各自的职业列表中。与性别词向量结果类似,词向量偏差得分与美国人口普查中少数族裔群体的职业比例有显著的相关性。这方面的结果在原文附录 C.1。
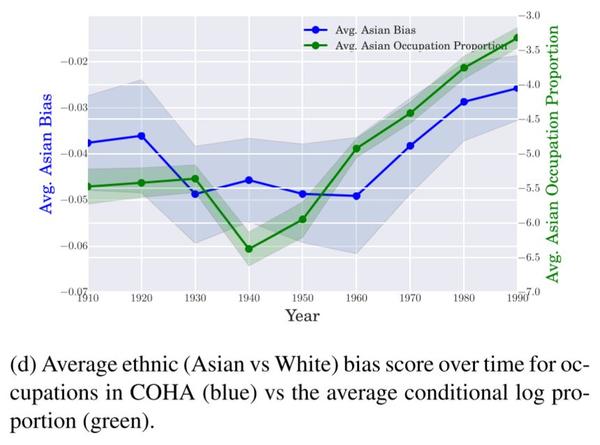 图1d
图1d
作者同样追踪了职业偏差分数随时间推移的情况,并将其与人口普查数据中的职业参与比例进行比较;图1d中,纵坐标是职业参与比例数据(蓝色实线),其中分母是白人职业参与比例,而分子则是亚裔美国人,绿色实线是在 COHA语料库训练的词向量所获得的偏差值。所有职业的就业占有比例的增加,与词向量的偏差基本成正比。
拉丁族裔的分析在原文附录C.2,这里不再展开。
词向量可量化性别刻板印象
研究者们已经知道,可以通过比较不同时间段的词向量来考察刻板印象如何随着时间演化。那么是否可以通过这种方法来获得对于女性的具体描述呢?比如,通过形容词的使用?作者们立即意识到这是个绝妙的方法。文学作品里充满了各种各样的形容词,而对文学作品本身的量化分析又比较困难。所以通过分析文学作品和新闻中形容词的使用,就能够获得一个可以被量化的不同时代的女性群像。同时,因为历史数据的缺乏,这种方法的价值也更加重要。此外,作者还显示了1960年代和1970年代的妇女运动如何导致这种形象的系统性变化。
作者利用的形容词数据是现有的最佳数据,这些数据是由人类参与者给一组230个形容词的性别偏见程度所做的评分(17,18)。这项研究首次在1977年进行,然后在1990年重复进行。
 图2a
图2a
让我们考虑描述智力的形容词的一个子集,如智慧、逻辑和深思熟虑(完整的单词列表可参见附录 A.3)。随着时间的推移,这组词汇与女性的联系有所增加(从强烈偏向于男性,到程度较少地偏向),特别是在1960年代之后。作为比较,文章还分析了一组描述外表的形容词,例如,有吸引力的,丑陋的,时髦的,这些词的偏差随着时间的推移没有明显的变化。可以注意到,尽管这些趋势令人鼓舞,但正如图2a所示,排名最靠前的形容词仍然存在潜在的问题。
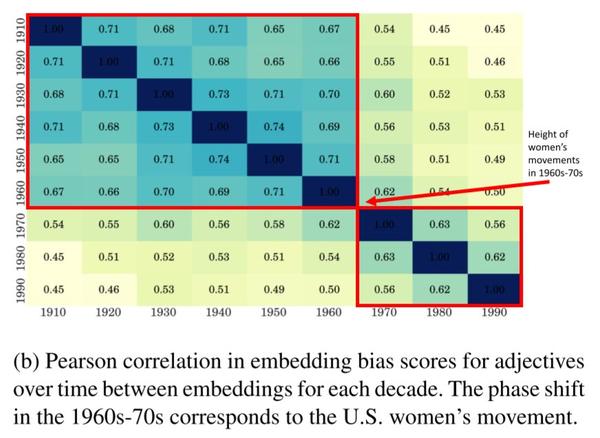 图2b
图2b
除了具体的形容词,作者假设随着时间的推移,词向量的比较可以揭示更多的全局的社会变化。 图2b 显示了每两组词向量之间相关性,即在每两个十年的 COHA词向量中,词向量形容词的偏差得分之间的相关性。正如预期的那样,最高的相关值在对角线附近(因为是同一年的);两组词向量之间的时间越近,就越相关。
更引人注目的是,该矩阵显示出两个清晰的区块。1960年代和1970年代之间存在着巨大的差距,这正是美国妇女运动的最高峰。在这期间,妇女运动大力地推动和扫除女性在教育和工作场所的法律和社会障碍。这种分歧表明,上述智力与外表相关的形容词的分化其实是一个更大规模语言转变的一部分。这项工作提供了一种新的量化方法来衡量变化的速度和程度。这项工作的可能延伸和应用将是研究妇女的各种叙述和描述是如何随着时间的推移而发展和竞争的。
 Women Engineering by Nick Slater
Women Engineering by Nick Slater
一些单独的词汇也会随着时间的推移而改变。这种词向量也揭示了个别单词与性别的关联如何随着时间的推移演变出有趣的模式。
例如,直到20世纪中期,“歇斯底里”这个词还是诊断妇女精神疾病的一个标志性词汇,但是现在已经变成了一个更普遍的词;这些变化在词向量中得到了清晰的反映,因为“歇斯底里”从一个在1920年前五名的反映女性偏见的词语降到了1990年COHA词向量中排名前100名以外。另一方面,随着时间的推移,情绪化的(emotional)这个词语与女性之间的联系越来越紧密,这反映了它是当前一个很大程度上对女性带有贬义意义的词语。
这些结果共同证明了本文提出的方法在研究时间尺度上偏见的价值和潜力。词向量能够捕捉到关联中微妙的个体变化,以及更大的历史变化。总的来说,他们描绘了一个性别偏见正在减少但仍然很明显的社会。
为了研究关于亚洲人的刻板印象,文章使用了常见和明显的亚洲姓氏,这些姓氏是通过附录A.2部分描述的方法来确定的。这个方法产生了一个20个姓氏的列表,这些姓大部分是中国人的,但也包含其他亚洲国家。这些词向量说明了20世纪亚裔美国人的刻板印象是如何发展和变化的。
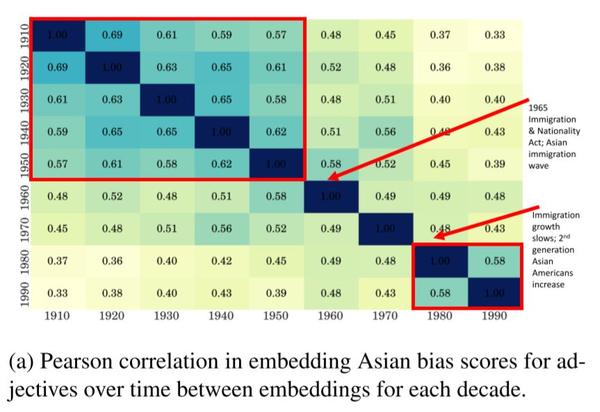 图3a
图3a
图3a显示了随着时间的推移,每组词向量的相关系数。与性别类似,这里的分析显示了外部事件如何改变人们的态度。图中的相关系数有两个阶段的变化: 1960年代,由于1965年《移民和国籍法案》的通过,亚洲移民大量增加;1980年代,移民持续增加,第二代亚裔美国人开始出现(19)。
研究者们提取出对亚洲人最有偏见的形容词(与白人相比) ,以便更深入地了解导致这些全局性变化的因素。
 图3b
图3b
图3b 显示了1910年、1950年和1990年最具亚洲偏见的形容词。在1950年之前,极度负面的词汇,尤其是那些经常被用来形容外来者的词汇,与亚洲人联系最紧密:野蛮、可恨、可怕、怪异和残忍。然而,从1950年开始,特别是从1980年开始,随着美国亚裔人口的增加,如今这些词汇在很大程度上被另外一组印象所取代:敏感、被动、自满、活跃和热情。而这些印象被认为是亚裔美国人的刻板印象。附录中的表35,列出了每个十年中与亚洲人联系最紧密的10个词汇。
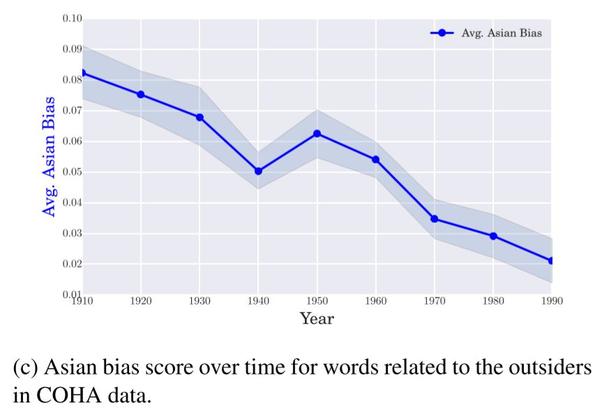 图3c
图3c
利用对于趋势的度量方法可以更精确地量化这种变化:图3c 显示了随着时间推移,用来描述外来者的词语与亚洲有关的词汇的相对关联强度。与总体上的形容词相反,亚洲关联词汇中出现了两个截然不同的阶段性变化,同时随着时间的推移,与外来者相关的词语在亚洲关联词汇中逐渐减少——包括在西方国家出现少量中国移民时——这表明,更广泛的全球化趋势导致人们对这种负面描绘的态度发生了变化。
总的来说,对词向量(特别是形容词)变化的研究,揭示了20世纪主流文化对亚裔美国人的态度发生了显著的变化。
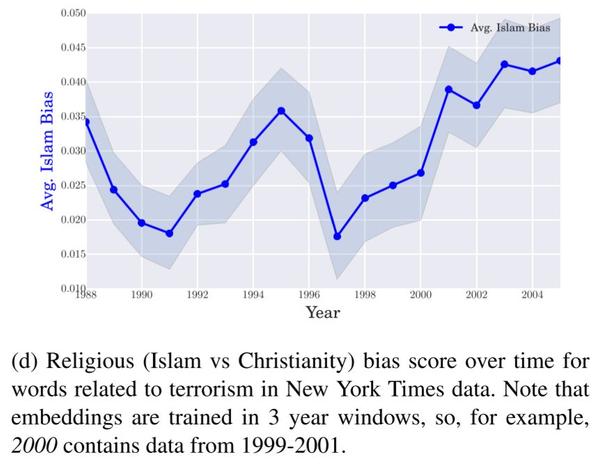 图3d
图3d
类似的趋势也出现在其他数据集中。图3d显示,在过去二十年的《纽约时报》上,与伊斯兰教相关的词汇(与基督教相关的单词相比)如何与恐怖主义有关的词汇联系起来。
类似于他们如何衡量与职业相关的偏见,作者创建了一个与恐怖主义有关的词汇清单,比如恐怖、炸弹和暴力。 然后他们测量这些词语在文本中是如何与代表每一种宗教的词语联系起来的,例如清真寺和教堂对应于伊斯兰教和基督教。在过去二十年的《纽约时报》中,伊斯兰教与恐怖主义的联系比基督教更多。此外,在1993年世界贸易中心爆炸事件和9/11事件之后,这种联系都有所增加。通过更新的数据集和使用更多的新闻渠道,研究自2005年以来这种态度如何演变将会是有益的。
 Make Extremism History 来源:posterfortomorrow.org
Make Extremism History 来源:posterfortomorrow.org
作者还说明了词向量如何捕捉对其他族群的刻板印象。例如,附录中的图34显示了词向量偏差与俄国名字相关联的词向量的关系,表明1950年代冷战开始时发生的巨大变化,以及在1910年至1920年俄国革命的最初几年里发生的轻微变化。
此外,附录中的图33,词向量偏差与拉丁裔名字的相关关系是一个有效的控制组。它显示了更稳定的词向量变化,而不是在亚洲和俄罗斯关联词汇中发现的急剧转变。这种模式符合这样一个事实,即整个20世纪的许多事件影响了拉丁裔移民到美国的故事,但没有一个单独的事件扮演过于重大的角色(20)。
这些模式表明,作者研究种族和性别偏见如何随着时间演变的方法是有用的; 类似的分析还可以应用于考察对其他族裔群体态度的转变,特别是在重大的全球性事件前后。
本文的主要贡献是通过词向量的视角,为探究刻板印象的时间动态演化提出一个新的分析框架。作者的框架可以对偏差进行简单计算、提供定量的测量指标以及简单的可视化。
必须指出,作者认识到他们的目标是进行定量探索性分析,而不是确定某些刻板印象如何产生的具体因果模型。然而,他们相信这个方法使得美国历史上大规模文化转变的分析更加精确,例如,20世纪60年代的女性运动与编码矩阵中(图2b)的急剧变化相关,同时也与特定职业和性别偏见形容词的变化相关(例如歇斯底里vs.情绪化)。
在标准的定量社会科学中,机器学习被用作分析数据的工具。 他们的工作表明,机器学习的工具(这里的词向量)本身是如何成为社会学分析的有趣对象。他们相信这种范式的转变可以导致许多富有成效的研究成果。
---------------------------------------------------------------------------------------------------------------------------
每日小知识分享:每一个 HTML 文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML里, 我们都可以看到类似下面这段代码:
<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><meta http-equiv=Content-Type content=www.tokenpocketl.net TP钱包;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来,主要告知搜索引擎本页面的关键字以及对应网址,在SEO中传递相关权重起到非常重要的作用。

