



794
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Arctic 是一个开放式架构下的湖仓管理系统,在开放的 lceberg 数据湖格式之上, 提供更多面向流和更新场景的优化,以及一套可插拔的数据自优化机制和管理服务。
湖数据与数据仓库都是常见的大数据存储系统。得益于其低廉的成本优势,数据湖一般用来存储海量的原始数据。原始数据经过清洗、标准化后会再导入到数据仓库中进行数据分析。数据在两个系统间流转无疑增加了额外的存储与维护开销。
近年来随着 Apache lceberg、Apache Hudi、Delta Lake 等数据湖表格式技术的不断发展使得直接在数据湖上构建一套统一的存储系统来满足所有的大数据存储需求成为可能。业界将这种直接建立在数据湖之上,却能同时覆盖数据湖与数据仓库存储场景的架构为湖仓一体(LakeHouse)。
然而开源表格式距离生产可用的湖仓一体架构还有着较大的鸿沟,在这个背景下网易在 2022 年开源了湖仓管理系统 ——Arctic。Arctic 是一个开放式架构下的湖仓管理系统,在开放的数据湖格式之上,Arctic 提供更多面向流和更新场景的优化,以及一套可插拔的数据自优化机制和管理服务。基于 Arctic 可以帮助各类数据平台,工具和产品快速搭建开箱即用,流批统一的湖仓。
要构建一套开箱即用的湖仓系统,自动优化是第一个需要解决的需求。现在大部分开源的数据湖表格式都要求用户投入大量的精力来维护你数据湖表中的文件结构,稍不留神表的查询性能就可能出现较大的下滑。
湖仓上有两类常见的优化需求:文件合并与文件清理。文件合并可分为以下场景:
合并碎片文件:数据写入时受限于本次写入的数据量和写入并发,很难保证每个写入文件都达到用户预期的大小。特别的在实时场景下为了降低湖仓中数据的延迟,需要频繁地提交新文件,这无疑将会带来大量的碎片文件。过多的碎片文件会造成数据膨胀,进一步降低湖仓表的读取性能,故及时得合并碎片文件到用户的预期大小对湖仓表的性能至关重要。
合并变更文件:现代的湖仓表格式通常都有行级更新的能力,而实现行级更新的一般方法是将更新操作写入到单独的变更文件里,这样能快速完成数据变更。但随着变更文件越来越多,在读取表中数据时需要的合并变更文件与数据文件的资也越来越多,而这个变化一般成指数级上升,故用户也需要及时合并变更文件到数据文件中。
常见的文件清理场景包括:
清理过期文件:表中被删除的文件现在一般不会被立即删除掉以应对用户查询历史数据的需求,而过期了的历史书库文件则需要文件清理流程来处理。
清理垃圾文件:写入失败的任务可能遗留下一些不再需要的垃圾文件,这些文件同样需要文件清理流程来应对。
Apache lceberg 通过在 Spark 引擎内提供了丰富的存储过程来应对文件合并与文件清理的优化需求。不过在实际使用时需要用户来判断何时需要进行优化、使用什么样的优化参数,并保证优化任务能正确完成工作。这无疑增大了用户的使用成本。
Apache Hudi 则提供在写入任务里同时运行优化任务,与使用另一个独立任务来完成优化的方式。前者可能造成写入任务与优化任务互相影响的问题。后者则需要为每个表维护一个长期运行的优化任务,任务多了将难以管理,同时很难保证优化任务的资源使用率。
可见要解决湖仓表的自动优化需求并没有那么简单,我们要面临如下难点:
什么时候进行优化:不同的表在数据写入上一般存在着较大的差异,即使同一张表在不同时间段也可能有着较大的数据写入变化,在进行优化时我们需要根据表当前的实际文件情况来判断是否需要进行优化。
对哪些文件进行优化:优化过程将对表中的文件进行重写,这个过程会造成写放大问题。而读取未优化过的文件将增大读取开销,造成读放大问题。文件优化过程需要追求达到写放大与读放大的平衡,用最小的优化资讯开销取得最大的优化收益。为了达到这个目的选取合适的文件来进行优化就至关重要了。
如何执行优化任务:随着表的增多,可能同事存在较多的优化任务,如何保证这些优化任务能够快速完成,在出现异常时能够自动恢复,并且能保证优化资源的利用率是另外一个需要解决的问题。
如何评估优化效果:优化任务完成后我们还需要能够直观的看到其开销和带来的收益,以帮助用户进一步评估优化任务的合理性,并进一步优化这个过程。
Arctic 引入了一套 Self-optimizing 机制,目标是基于新型数据湖表格式打造像数据库,传统数据一样开箱即用的流式湖仓服务,Self-optimizing 包含但不限于文件合并、去重、排序、孤儿文件和过期快照的清理。Self-optimizing 的架构与工作机制如下图所示:
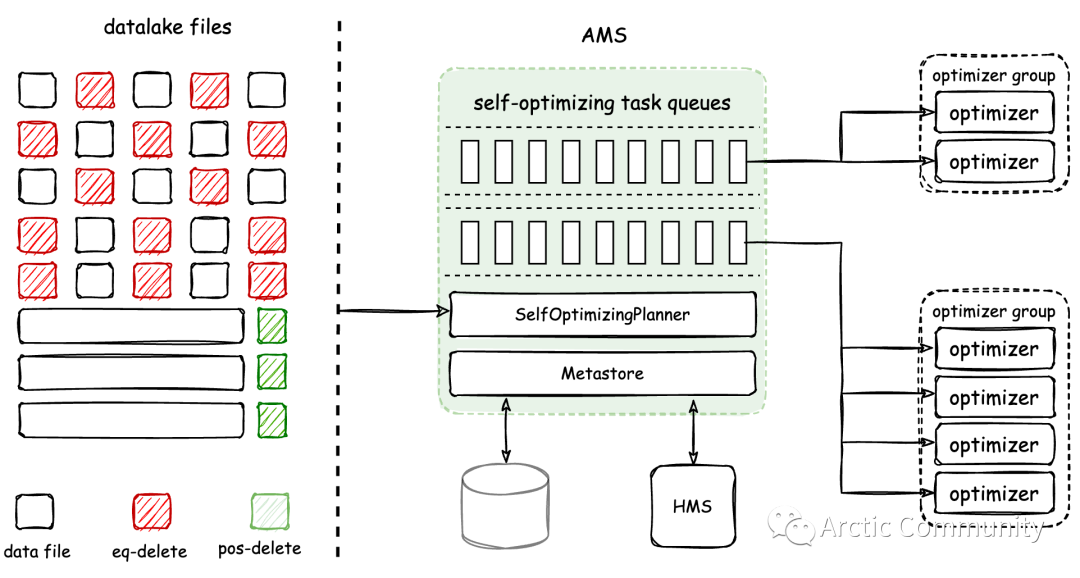
AMS (Arctic Management Service) 是 Arctic 的中心管理服务,它负责规划所有表的 self-optimizing 任务,并将任务下发给下面的 Optimizer 执行。Optimizer 是 self-optimizing 的执行组件,收到优化任务后负责具体的任务执行过程,最后再将执行结果上报给 AMS 后进行提交。Arctic 通过 Optimizer Group 对 Optimizers 实现物理隔离。
Arctic 的 self-optimizing 的核心特性有:
自动、异步与透明 —— 后台持续检测文件变化,异步分布式执行优化任务,对用户透明无感
资源隔离和共享 —— 允许资源在表级隔离和共享,以及设置资源配额
灵活可扩展的部署方式 —— 执行节点支持多种部署方式,便捷的扩缩容
AMS 会持续收集表上的写入信息并实时更新表上的统计信息,当表上的统计指标达到了触发自动优化的条件即会开始对表进行自动优化。统计指标会精确到分区级别,即写入频繁的分区会更频繁得触发自动优化。触发自动优化的条件包括:
分区的文件碎片数量:当分区内新增的文件碎片达到一定数量会触发当前分区的自动优化。
分区内的变更文件体量:当分区内的变更文件体量达到配置的大小会触发自动优化。
周期性进行文件优化:如果配置了周期性执行自动优化的策略,则会定期进行自动优化。
频繁的对表里的文件进行优化会消耗过多的资源,而如果不及时进行文件优化又会造成表上查询性能的下降。为了权衡资源开销与查询性能,Arctic 将文件优化任务进行了进一步的细分。
Arctic 将表中的文件按照大小分为了两类:
Fragment File:碎片文件,默认配置下小于 16MB 的文件,此类文件需要及时得合并成更大的文件,以及升读取性能
Segment File:默认配置下大雨 16MB 的文件,此类文件已经具备一定的大小,但还不到理想的 128MB.
基于以上的文件分类,Arctic 将文件优化任务分为以下三类:
|
类型 |
定义 |
目标 |
任务大小 |
调度频率 |
|
Minor Optimizing |
在 Fragment File 上的优化任务 |
降低文件碎片,将写友好的文件转换为读友好的文件 |
较小(比如 16MB) |
非常频繁(比如每 5 分钟一次) |
|
Major Optimizing |
在 Segment File 上的优化任务 |
将文件大小推进到目标大小,并减少冗余数据 |
中等(比如 128MB) |
较频繁(比如每 1 小时一次) |
|
Full Optimizing |
表或者分区内所有文件上的优化任务 |
将所以文件全局排序后重写 |
取决于表或分区的大小 |
不频繁(比如每一天) |
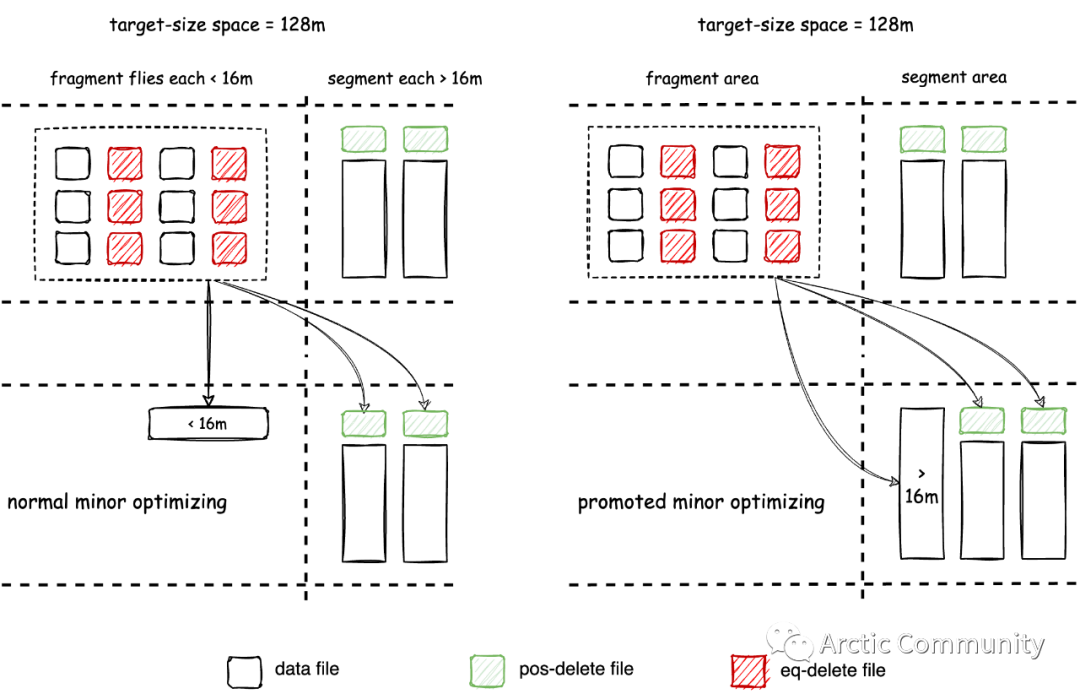
具体来说,对于 Iceberg 格式的表,Minor optimizing 会将小于 16MB 的 insert File 合并到大于 16MB,并将 equality-delete file 转换为 position-delete file,转换过程中会为每个 insert file 生成对应的 position-delete file,并将已有的 position-delete file 数据合并到新的 position-delete file 内,具体过程如下图:
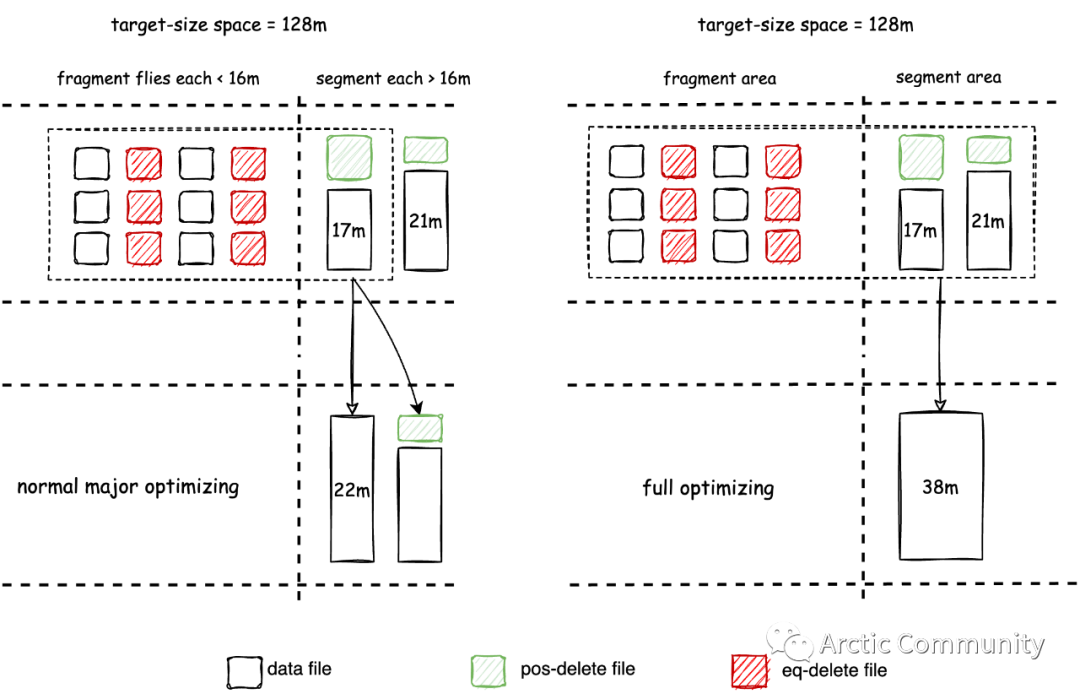
而 Major optimizing 则会将那些已经积攒了较大的 position-delete file 的 insert file 与其对应的 delete file 进行合并而消除其冗余数据。Full optimizing 会将所有的文件进行重写,重写过程会消除掉多有的 delete file。具体过程如下图:
为了保证优化任务能被及时调度执行,Arctic 采用维护一套长期运行的优化资源而非为每个优化任务临时调度优化资源的方案。所有表的优化任务都运行在统一的资源上,为了提升优化资源的利用率,同时避免表与表之间的相互影响,Arctic 提出了如下概念:
Optimizing group:一个优化组,每个表必须且只能归属于一个优化组,相同优化组内的表共享优化资源,不同优化组的表在优化资源上进行物理隔离。
Optimizing quota:每个表会被分配一个自动优化的配额,如果表上优化任务过多,导致配额被使用完则该表需要等待一段时间之后才能继续进行自动优化。
一个 Optimizing group 下一般会有多个 Optimizer,Optimizer 是一个独立的无状态的计算资源,如果某个 Optimizer 离线了,它上面的任务会被重新调度到同 group 下的其他 optimizer 上继续执行。当某个 group 下的 optimizer 利用率过大时,用户也可以简单的扩容新的 optimizer 来提升处理能力。
Arctic 抽象了一套 Optimizer container 接口来扩展不同的 optimizer 调度方式,项目内已经实现了新增本地进程和在 Yarn 集群上调度 Flink 任务的实现。用户也可以根据自己内部的调度框架扩展自己的 optimizer 运行方式。
Arctic 在其 WEB 界面工具中提供了单独的页面展示系统内每个表所处的自动优化状态,具体如下图:
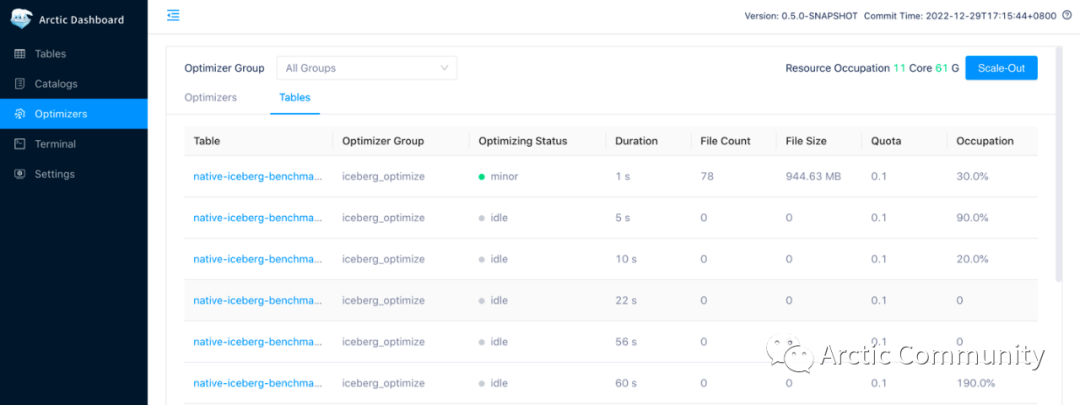
界面中不仅展示了表当前是否正在进行 自动优化,也给出了当前待优化的文件的具体情况,及配置和已经消耗的优化资源。
另外每个表的详情页面里也能看到已经发生过的自动优化任务,具体如下图:
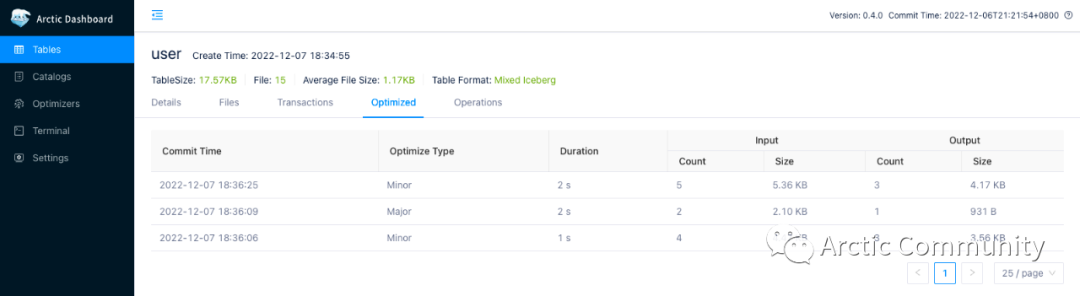
界面中展示了每次自动优化任务的类型、耗时、优化前的文件情况和优化后的文件情况。
Arctic 提供了一套自动、异步、透明的自动优化服务保证湖仓表的性能。这套实现方案已经在网易内部和开源社区内都得到了验证。
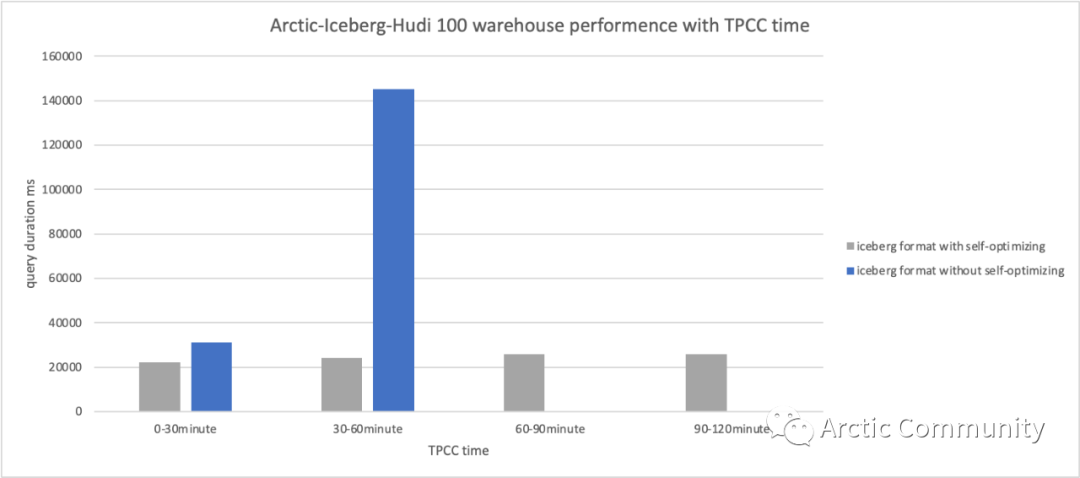
为了更直观得展现自动优化的效果,下面是 Arctic 团队内部分别测试在开启和关闭自动优化功能时,Iceberg 表的分析性能表现。测试模拟了表上持续有写入的情况下,Iceberg 表的查询性能,测试中发现随着时间推移不开启自动优化功能时,Iceberg 表查询性能急剧下降,在超过一小时后甚至因为内存溢出无法正确查询出需要的数据,而开启自动优化后随着时间变化表的查询耗时都能维持在一个较低的水平。具体的测试场景可以参考:Arctic Benchmark(https://arctic.netease.com/ch/benchmark/benchmark/)
未来 Arctic 在湖仓表的自动优化方面将沿着下面的路径继续演进:
集成更多的表格式:现阶段 Arctic 只实现了对 Apache Iceberg 表格式的自动优化,后面计划将集成更多的表格式,以帮助其他表格式的用户提升其在湖仓建设上的体验。
更智能的任务规划: 现阶段对表中的哪些文件进行怎样的文件优化仍然基于表上的配置,这就造成有时用户需要手动进行参数调优来取得更好的优化效果。未来 Arctic 将探索如何智能地动态调整优化策略以达到更好的使用体验。
---------------------------------------------------------------------------------------------------------------------------
每日小知识分享:每一个 HTML 文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML里, 我们都可以看到类似下面这段代码:
<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><meta http-equiv=Content-Type content=www.llyz.net imtoken;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来,主要告知搜索引擎本页面的关键字以及对应网址,在SEO中传递相关权重起到非常重要的作用。
