


19
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在文章《自然语言处理中的 Attention Model:是什么以及为什么[一]》中,介绍了实现 Attention Model 常常用到的 Encoder-Decoder 框架。那么如何直观理解 Attention Model 的工作原理呢?本文继续为你解析。
Attention Model
图一见下:
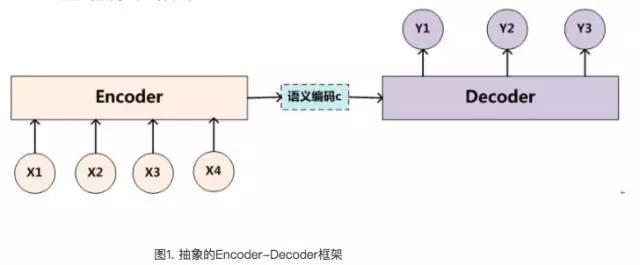
图1中展示的Encoder-Decoder模型是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。
为什么说它注意力不集中呢?请观察下目标句子Y中每个单词的生成过程如下:
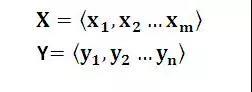
其中f是decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的句子X的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)。
这就是为何说这个模型没有体现出注意力的缘由。
这类似于你看到眼前的画面,但是没有注意焦点一样。如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候估计问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入AM模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。
这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。
这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。
理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。
增加了AM模型的Encoder-Decoder框架理解起来如图2所示。
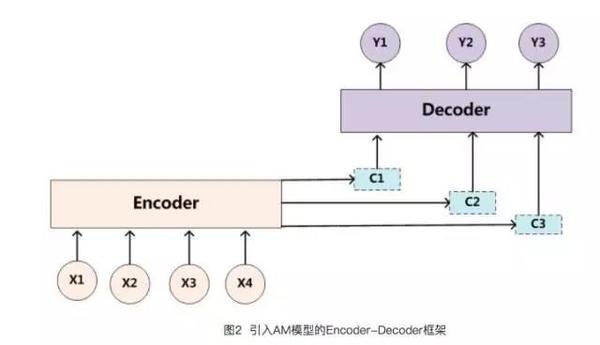
即生成目标句子单词的过程成了下面的形式:

而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;
g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,也就是常常在论文里看到的下列公式:
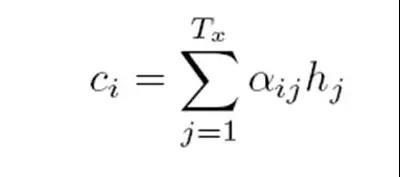
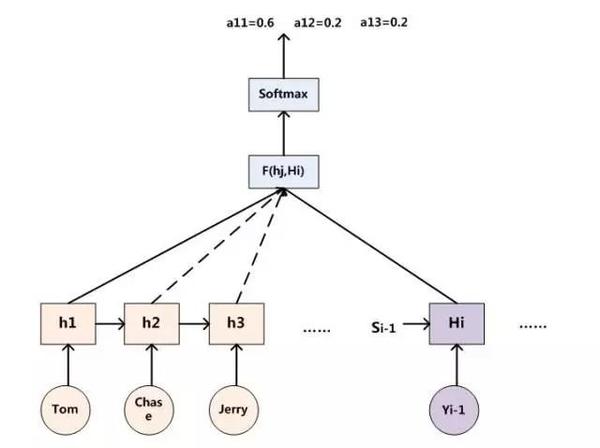
假设Ci中那个i就是上面的“汤姆”,那么Tx就是3,代表输入句子的长度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),对应的注意力模型权值分别是0.6,0.2,0.2,
所以g函数就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似下图:

这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,你怎么知道AM模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的概率分布:
(Tom,0.6)(Chase,0.2)(Jerry,0.2)是如何得到的呢?
为了便于说明,我们假设对图1的非AM模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图1的图转换为下图:
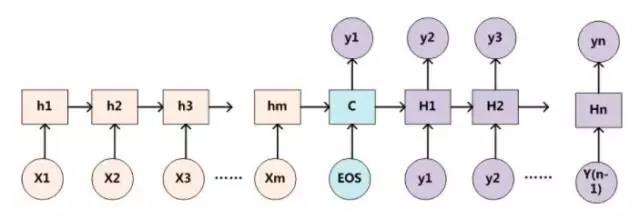
那么用下图可以较为便捷地说明注意力分配概率分布值的通用计算过程:
对于采用RNN的Decoder来说,如果要生成yi单词,在时刻i,我们是可以知道在生成Yi之前的隐层节点i时刻的输出值Hi的,而我们的目的是要计算生成Yi时的输入句子单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布。
那么可以用i时刻的隐层节点状态Hi去一一和输入句子中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi)来获得目标单词Yi和每个输入单词对应的对齐可能性。
这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
图5显示的是当输出单词为“汤姆”时刻对应的输入句子单词的对齐概率。
绝大多数AM模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。
上述内容就是论文里面常常提到的Soft Attention Model的基本思想,你能在文献里面看到的大多数AM模型基本就是这个模型,区别很可能只是把这个模型用来解决不同的应用问题。
那么怎么理解AM模型的物理含义呢?一般文献里会把AM模型看作是单词对齐模型,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
在其他应用里面把AM模型理解成输入句子和目标句子单词之间的对齐概率也是很顺畅的想法。
当然,我觉得从概念上理解的话,把AM模型理解成影响力模型也是合理的,就是说生成目标单词的时候,输入句子每个单词对于生成这个单词有多大的影响程度。这种想法也是比较好理解AM模型物理意义的一种思维方式。
图6是论文“A Neural Attention Model for Sentence Summarization”中,Rush用AM模型来做生成式摘要给出的一个AM的一个非常直观的例子。
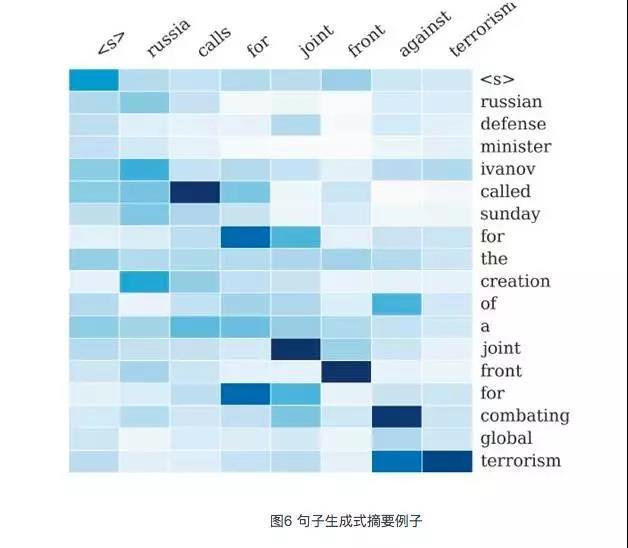
这个例子中,Encoder-Decoder框架的输入句子是:“russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism”。
对应图中纵坐标的句子。系统生成的摘要句子是:“russia calls for joint front against terrorism”,对应图中横坐标的句子。可以看出模型已经把句子主体部分正确地抽出来了。
矩阵中每一列代表生成的目标单词对应输入句子每个单词的AM分配概率,颜色越深代表分配到的概率越大。这个例子对于直观理解AM是很有帮助作用的。
原文地址:
转载声明:本文转载自「机器学习算法与自然语言处理」,搜索「yizhennotes」即可关注。
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.tokenpocketl.net;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。

