

















20
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享为业务团队发搭建效率平台,提高研发效率,高效支撑日常业务迭代一直是我们的目标。得物作为业界体量巨大的纯 swift 开发的 App,由于其庞大的组件数量, 编译速度一直是我们开发效率的拦路虎。
虽然我们做了很多的努力,让编译速度有了显著的提升,但是如果日常每一个测试包出现问题都要重新编译运行,那么这对于任何一个开发团队来说都是比较难受的。因此,我们根据 Xcode 的 Attach to Process 研发一整套的实时调试方案。
该方案使得工程师在排查问题时,可以不必进行编译,直接拿到运行 App 的测试机,将之连上电脑,就能够正常进行调试。能够正常下断点、输出变量名等。
本文主要介绍 ** 得物实时调试的全套解决方案,** 实现对测试包还原出包环境和无需编译就可以进行断点调试的功能。整体按实时调试方案的可行性分析,方向调研,优化方案设计,推进优化落地,最后在团队推广的流程。本文主要讲 4 个主要内容,包括:Attach to Process 介绍,环境还原,实时调试探索,组件化工程的实时调试。下面就来详细介绍下得物的实时调试方案设计。
其实苹果对于 Attach to Process 的介绍很少,简而言之,就是_Xcode 在名为 Attach to Process_的 Debug 菜单中包含了这个功能。这会显示一个对话框,让你可以告诉 Xcode 等待你的应用程序的进程开始运行。
点击 Attach 之后 Xcode 将自动附加所选择的程序到其进程并启用调试器,接着,你就可以使用 Xcode 的调试工具设置断点、调试视图层次结构等等,这意味着你无需重新编译运行就可以让 Xcode 来附加你的程序,并且去调试它。
当你从测试手中拿到一个测试包,测试反馈说这个包有一个严重的问题,那么你想要调试这个棘手的问题的时候,尽管它会发生多少次,但是当它发生时,你会发现这个测试包没有在 Xcode 上运行。更糟糕的是,你的 App 代码库可能非常庞大,需要很久的编译时长才可再次运行。这时候,我们想到可以通过埋点、用户行为路径等方式来猜测这问题发生的可能性,但是这可能并不能最好的解决方式。
对于绝大多数的 iOS 开发来说,在 XCode 上使用 Debug 模式来调试程序才是我们最得心应手的方式,我们严重依赖断点来调试一段代码。因此 Xcode 提供了一个 Attach to process 的功能,其实这也依赖 LLDB 的强大功能,可以让 LLDB 附加到正在运行的程序中去。根据这一特性,我们就可以不必重新编译运行我们的程序来完成对测试包的断点调试。
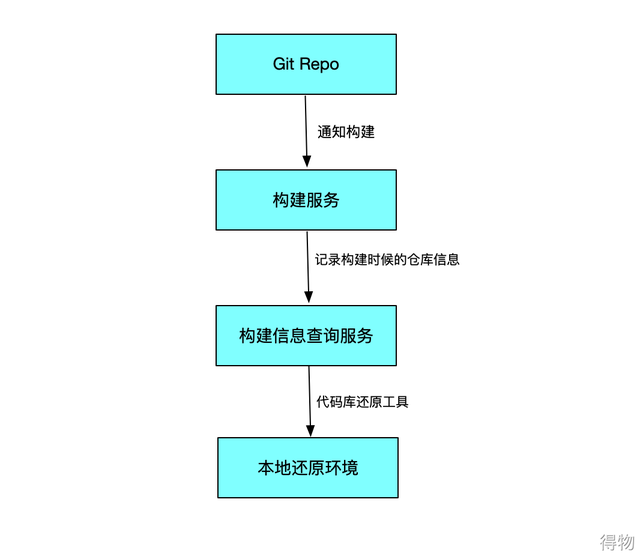
这里的环境还原指的是出包的时候的代码库还原。我们都知道每一个应用程序都有其唯一的一份代码,我们的测试包一般是根据如图所示的 CI/CD 流程来到测试手上,所以这里所指的环境也可以理解为构建机器在构建测试包时候,本地所处的代码库。
上面我们说到,我们将会利用 xcode 的 Attach to process 来实时断点调试。尽管你无需编译就可以来调试你的 App,但是本地的代码也是要和你的测试包相匹配,这么做的主要原因有两个:
其一,为了可以让 Xcode 在正确的代码上打上断点,这样你在调试的时候才能更准确的找到问题代码所在。
其二,排除代码因素的干扰,因为有时候可能测试反馈的问题只会在特定的代码节点才会发生,如果代码和当时出包时候的不一样,那么有可能后续的代码将影响该问题的复现。
所以在实时调试之前,将本地代码还原到出包环境是很有必要的。
由于每个公司的代码管理、工程管理、CI/CD 等不同,因此没有一套统一的方式来进行代码库还原。不过大致的流程应该如下:
1. 在构建机器进行测试包构建的时候记录仓库的信息;
2. 保证每一个测试包都有其对应的仓库信息;
3. 通过接口或者其他辅助工具可以让开发人员快速将本地代码仓库切换到出包时候的代码库。
补充说明:
如果公司的工程中有二进制组件存在的话,在记录代码仓库信息的同时,也要记录其二进制仓库信息。
目前,得物已经有了自己的环境还原工具链,可以根据测试包的唯一 ID 来还原代码库并且获取产物信息、构建信息等其他相关信息。
如果我的 App 已经成功 Attach 到 xcode 上,并且利用辅助工具,将代码还原到了出包时候的环境。那么是不是立即打上断点来调试了。如果你立即就这么干了,那么你会出现一些意想不到的问题,本节将列举得物在实时调试实践中所遇到的困难和解决方式。
这里我准备了一个名为 DuAttachProcess(使用 cocoapods 来管理组件) 的测试工程来对我们的实时调试进行探索。
●通过 xcode 的 archive 的功能,手动构建一个 IPA 包,然后通过 Xcode 将 IPA 安装到手机上;
●运行我们安装的 DuAttachProcess 程序 **,然后通过 Xcode 的工具栏的 Debug->Attach to Process 将我们的程序进行 Attach**,此时会有一个等待的标志,等待其完成就好。
为了更好的模拟我们的出包环境,我们需要在一个新的路径打开 DuAttachProcess 源码工程并且进行 Attach。
●Attach 完成之后,打上我们的断点,神奇的一幕发生了,断点竟然变成了虚线,如图所示:
那么是什么原因,是不是我们哪里的操作步骤有问题?我们可以将鼠标放到断点的虚线上,此时 Xcode 会给出提示:
因此要想断点成功生效,必须满足以下三个条件
●断点所在行的代码必须被编译
●编译器生成未剥离符号的调试信息,并且提醒我们去检查 Build Settings 配置信息
●断点所在 Library 必须被加载
那么为了补足以上三个条件,我们的必须调整配置或者加入一些配置。
从上述所示的三个条件来看,我们首先最好验证就是当前 Library 是否被加载。没错,我们首先想到的就是 image 这个命令,因此在 xocde 的终端中输入如下命令:
(lldb) image list DuAttachProcess
该命令可以查看当前 DuAttachProcess 模块是否被加载进来,输入如下:
从上面可以看到,DuAttachProcess 是有被加载到调试器的,那么会不会是该断点的代码没有被加载呢,其实我们也可以通过 image 的命令来验证:
(lldb) image lookup -rn ViewController.log DuAttachProcess
参数解析:
-r:表示正则匹配
-n:表示名字
-rn ViewController.log DuAttachProcess:通过 ViewController.log 这个正则在名字为 DuAttachProcess 模块中查找
通过下图可以看到有两个匹配结果,说明该 log 方法是有被加载到调试器的。
结论:通过以上验证,Xocde 给出的 The library for the breakpoint is loaded 这个条件是满足的,所以我们要看其他两个条件是否满足 。
现在我们来看第一个条件,该断点所在行的代码必须被编译。可是我们文章开头说过,实时调试是不需要编译的,但是 Xcode 又必须要求我们被编译,这不是自相矛盾了吗?其实是有办法可以解决的。
首先我们是不是会有疑问,Xcode 是如何知道这一行有没有被编译?我们一般都会有一个简单粗暴的想法:
Xcode 在编译生生成二进制的过程中,在二进制中某个地方存储了该二进制所对应的源码的文件路径。Xcode 就是通过该文件路径来判断某块代码是否被编译。
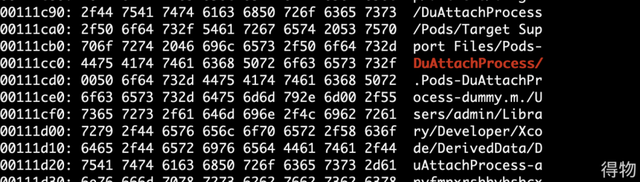
要验证这个猜想,我们必须要读取我们的可执行文件中的路径信息,我们可以通 xxd 这个命令来验证:
xxd DuAttachProcess | grep -C 10 'DuAttachProcess/'
xxd: 给定的标准输入或者文件做一次十六进制的输出。
从 xdd 命令的输出可以看出该可执行文件里面确实包含了源码的路径信息。既然这样的话,那么我们是不是可以做一个映射,让 Xcode 直接去找到的时候的源码路径?当然是可以的,LLDB 已经为我们准备了充足的命令来供我们使用。其中一个 settings 命令就是用来给 LLDB 增加额外配置的,通过 help 命令,我们可以看到有个 set 的设置命令,因此我们可以在 lldb 中输入如下命令:
(lldb) settings set target.source-map "构建机器源码路径" "Attach工程源码路径"
输入完成命令之后,我们看到断点果然是可以打上了,如图:
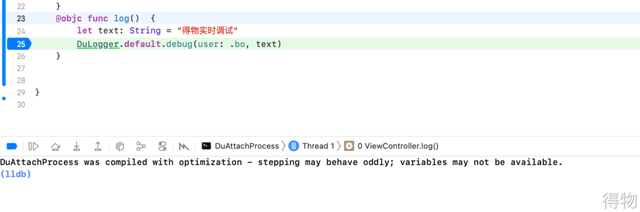
那么我们试试断点是否正常吧!点击屏幕,我们看到断点也会正常运行,但是 LLDB 会抛出一个断点可能滞后和变量可能无法读取的警告:
在控制台使用 po 命令验证变量读取,LLDB 会抛出无法读取变量的警告,如图所示:
其实原因已经显示在上面了,就是因为你开启了 Xcode 的编译优化,因此我们需要修改 Xcode 的 Build Settings 配置。
通过上面的尝试,我们基本已经解决断点无法打上的问题,但是在控制台依然不能打印出变量,因此我们需要修改相应的配置。
由于我们的测试工程是 swift 工程,因此我们需要关闭 swift 的编译优化,在 Build Settings 中找到对应出包 config(debug、release、internal 等) 下的 SWIFT_OPTIMIZATION_LEVEL 的配置,将其设置为 **-Onone**,如图所示:
并不是所有的 config 都要改成 **-Onone,** 否则将无法享受苹果带来的编译优化,根据自己需求,选择对应出包的 config 来关闭编译优化。
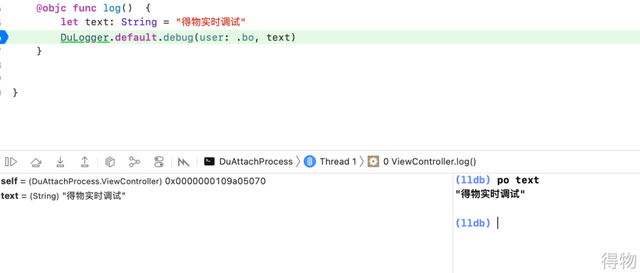
接下来,我们重新打包,重复之前的都 attach 流程和 LLDB 配置,点击屏幕,触发断点之后使用 po 命令输出变量,发现可以正常打印,如图:
那么之后就可以愉快地使用实时调试了。
现在已经很少有单体工程了,一般我们都会使用 cocoapods 来管理组件,进行组件化开发,因此上一节的修改配置也只是针对主工程的 target 的。那么我们如果需要在组件中打断点会怎么样呢?
现在我们重复上一节的操作,并且使用 settings set target.source-map 命令进行路径映射,之后我们在组件中打上断点,发现断点式无法打上的。
既然无法打上断点,那么就是断点三大条件没有满足,经过排查,发现是组件的 Build Settings 的设置问题,组件中的 SWIFT_OPTIMIZATION_LEVEL 的配置没有被设置成 **-Onone**,那么我们就需要将每一个组件也设置成 SWIFT_OPTIMIZATION_LEVEL= "-Onone", 通过 cocoapods 的 Hook 功能可以很容易做到这一点,这里简单示例 (实际可能比这复杂的多) 如下:
post_install do |installer|
installer.pods_project.build_configurations.each do |podConfig|
if podConfig.name == '出包时的config(debug、release、internal等)'
podConfig.build_settings["SWIFT_OPTIMIZATION_LEVEL"] = "-Onone"
end
end
end
** 说明:出包时的 config:** 由于在工程中可能有多个 config,因此我们只需要更改构建出包的 config 即可。
完成上述步骤之后,我们接下来再来进行断点调试,此时可以正常打上断点了,如图所示:
除了正常的组件依赖管理,我们时常会在开发的时候使用组件的本地依赖,这里又可以分两种情况:
●构建机器本地依赖出包,attach to process 的工程正常依赖
●构建机器正常依赖出包,attach to process 的工程本地依赖正常依赖:在 Podfile 文件中没有 path 指定
本地依赖:在 Podfile 文件中做了 path 指定
此时尽管可能两个组件的代码都是一样的,但是我们尝试打上断点,发现断点也是无法打上的,如下所示:
此时我们应该很快就会想到,肯定是这块源码没有被编译,添加路径映射就可以解决了。
(lldb) settings set target.source-map "构建时组件地址" "本地依赖组件实际地址"
输完命令之后,发现就可以正常打断点了。
但是我们只设置了一个组件的映射,那么其他组件是不是打不上断点呢?** 经过探索发现,其他组件确实是无法打上断点的,** 那么怎么解决呢?
其实 LLDB 除了 settings set 命令还有 setttings append 命令,我们可以用 appen 命令再追加一个全局的工程路径就好了,如下所示:
(lldb) settings append target.source-map "构建机器源码路径" "Attach工程源码路径"
追加该命令之后,我们发现断点可以正常运行,变量也是可以正常打印的。
为了加快编译速度,现在有很多公司都是采用二进制组件的方式集成进工程,但是这为我们调试也带来了一定的困难。我们碰见最多的应该就是这个场景了:测试包使用的是二进制组件,但是我们想实时调试的工程希望是源码。这样在源码组件中可以打上断点吗?显然是不行的。这是什么原因呢?我们可以继续使用 xxd 命令查看:
xxd DuAttachProcess | grep -C 10 '要调试的组件名称/'
我们可以看到,输出结果是包含二进制制作时候的路径地址,并不是我们出包时候的组件路径。因此我们还需要单独对该二进制组件做一次路径映射:
(lldb) settings set target.source-map "二进制制作时组件路径" "Attach工程源码/组件地址"
这样我们就可以实时调试二进制组件了。
本文主要介绍了团队在实时调试方案设计和落地的过程中遇到的问题以及解决方案,解决了实时调试最核心的两个关键点:环境还原和 ** 保证断点可用。** 在日益膨胀的业务代码累积场景下,为了改善团队小伙伴的调试效率和排查问题效率,于是设计了这样一套实时调试的方案,实现了拿到测试包无需编译可以直接打断点调试的功能。
未来我们计划开发更高效可用的辅助工具来简化实时调试的流程,提高调试的效率。最后着重感谢组内同学对本篇 blog 的建议与支持。如果你对实时调试有什么独特的见解,欢迎评论区与我交流,大家一起探讨学习,共同进步。
小知识分享:每一个HTML 文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><meta http-equiv=Content-Type content=www.zyhsqjfw.com ;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来,主要告知搜索引擎本页面的关键字以及对应网址,在SEO中传递相关权重起到非常重要的作用。
