


144
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级: 202214
姓名: 漆心雨
学号:20221420
实验教师:王志强
实验日期:2022年5月11日
必修/选修: 公选课
目录
运用python的爬虫,爬取起点中文网站的月票榜(包括排名、书籍名和作者)。
查找网址
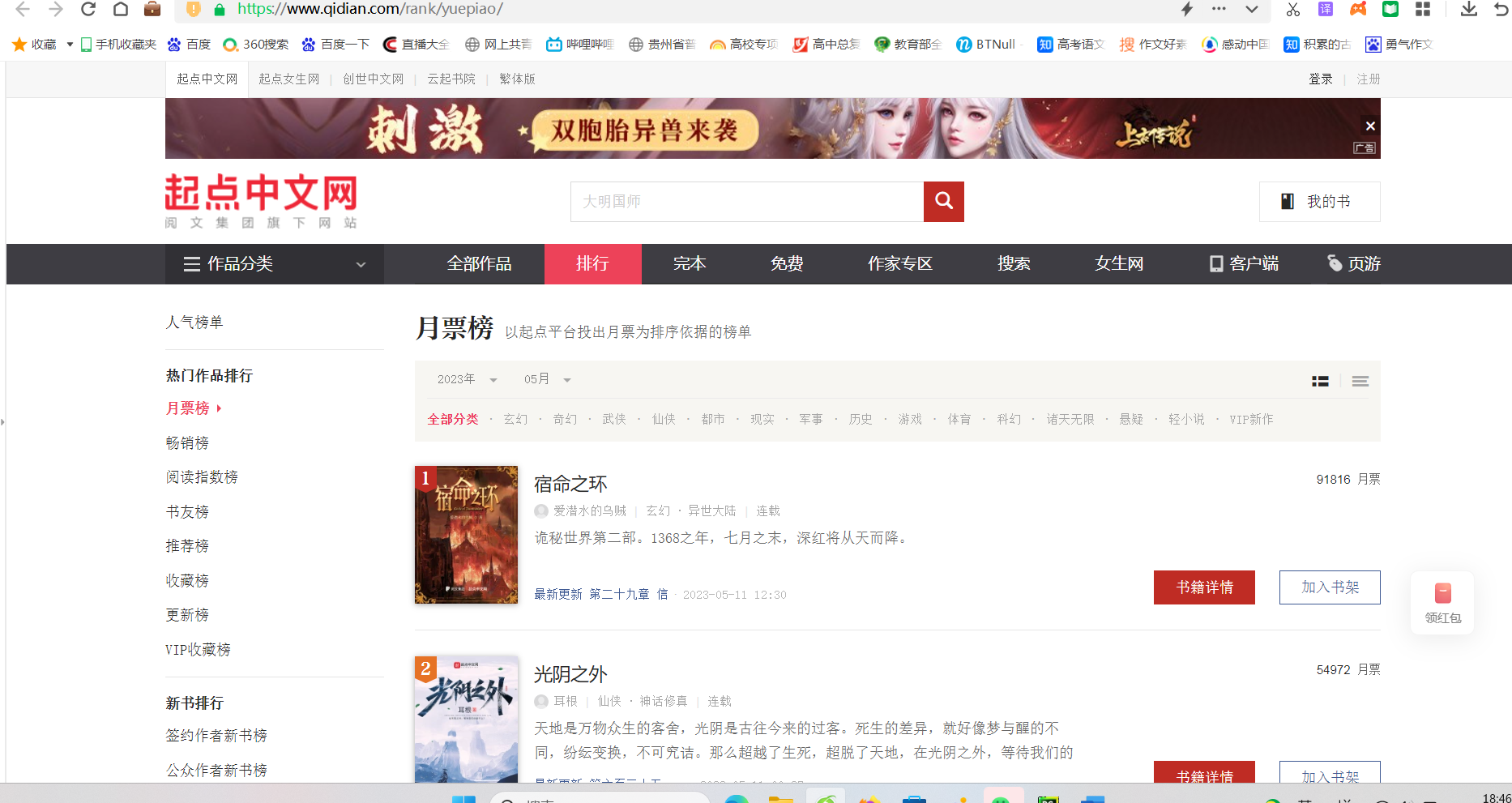
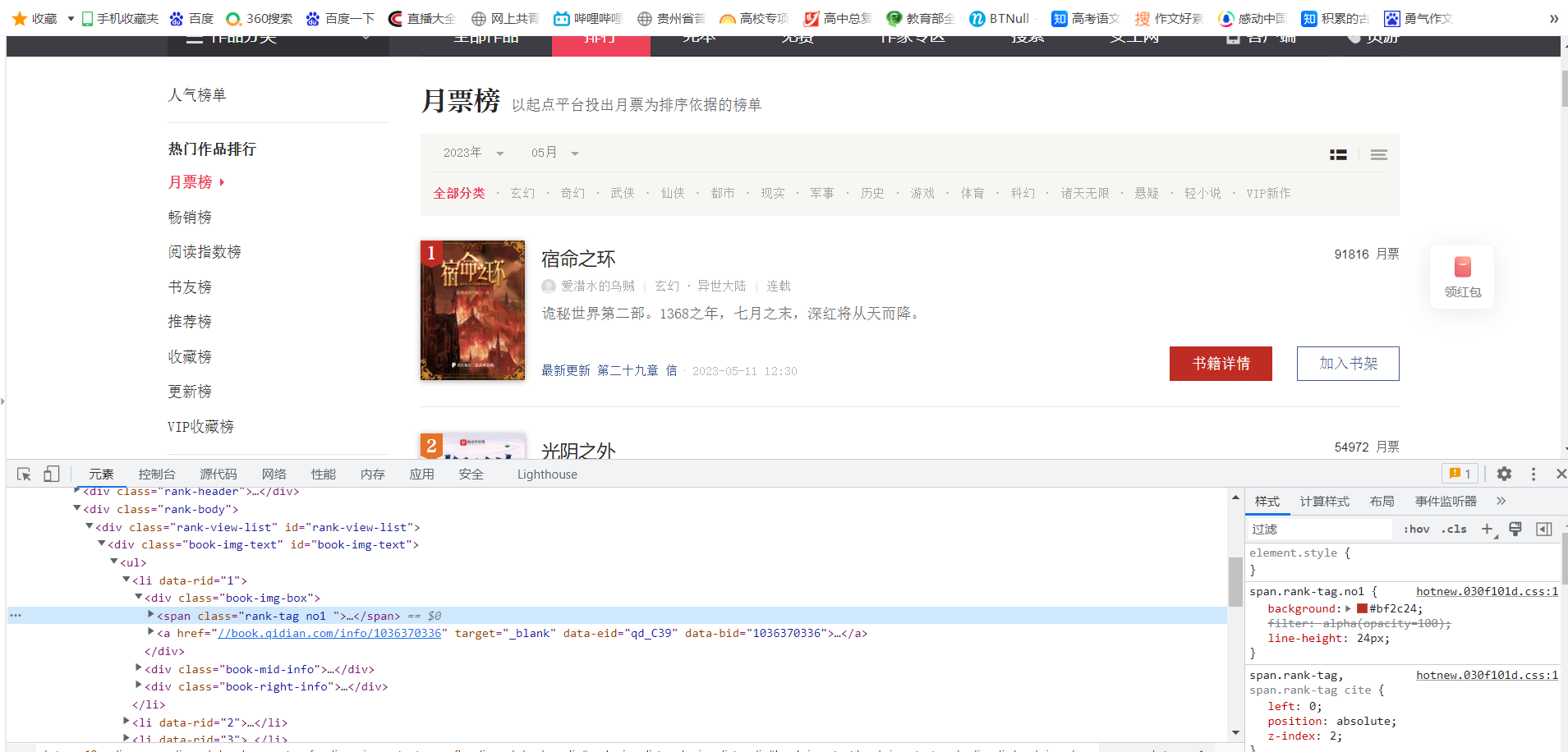
查看对应的HTML代码
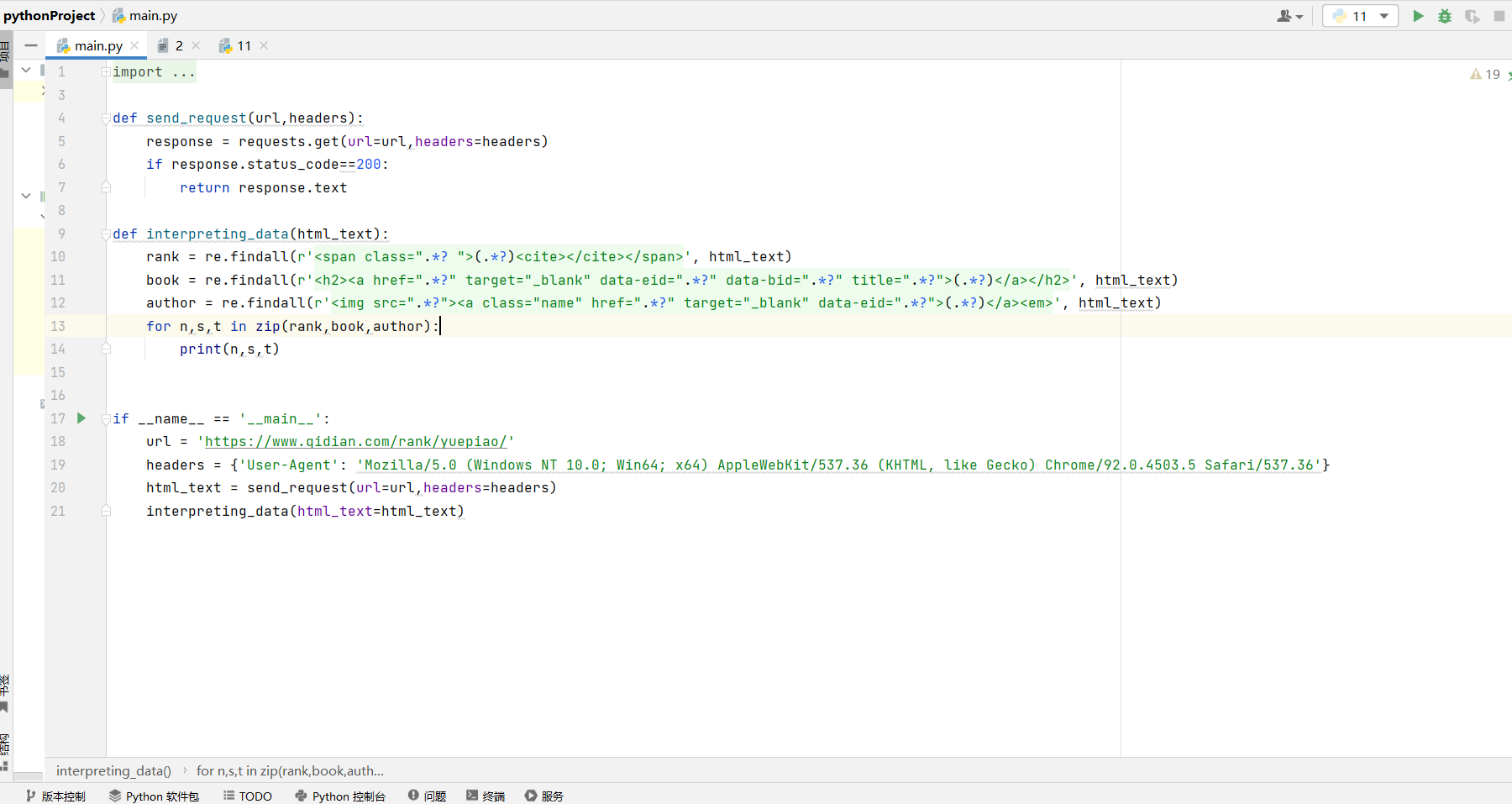
编写代码
运行结果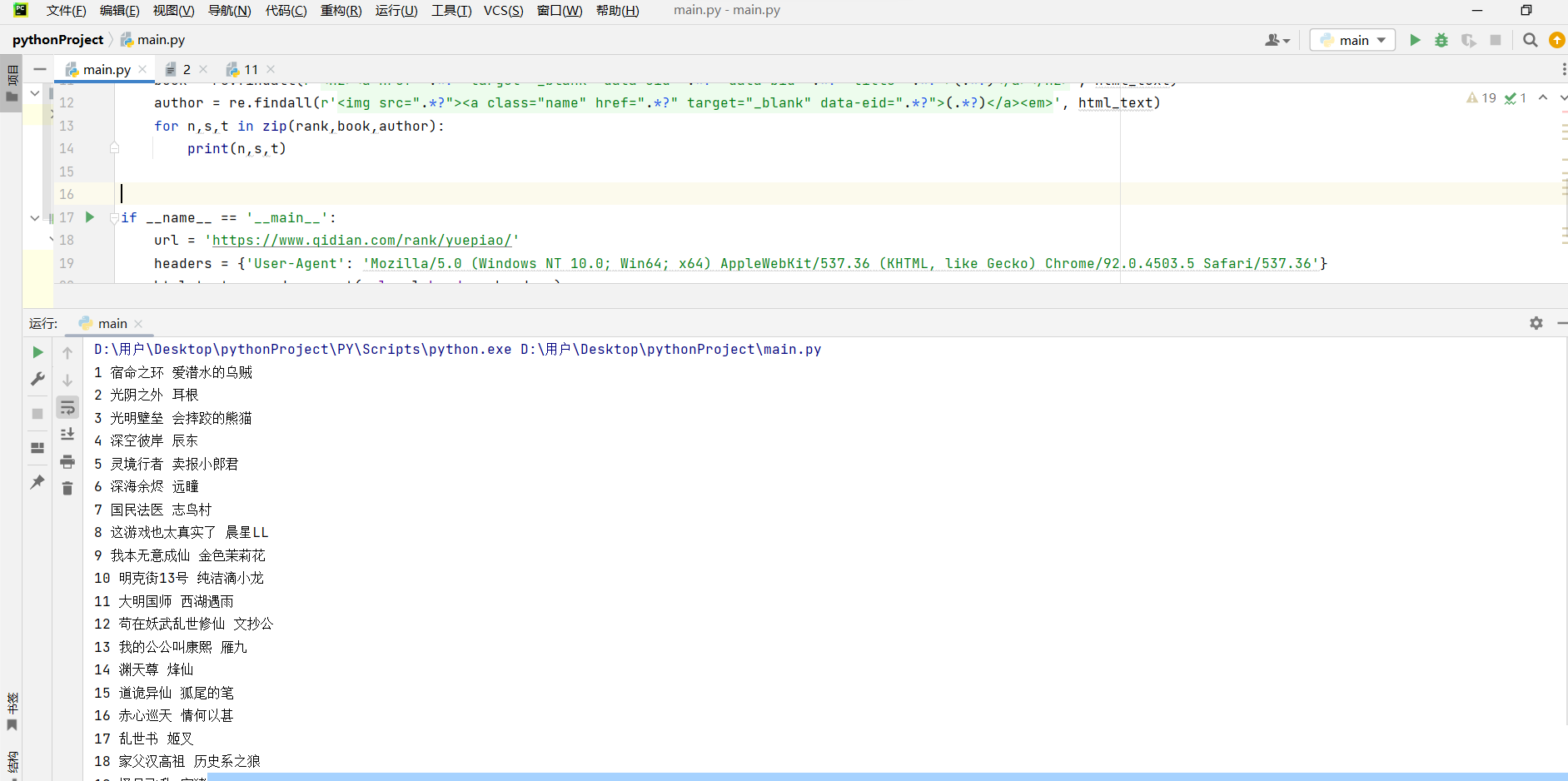
上传到gitee
4.源代码以及运行视频
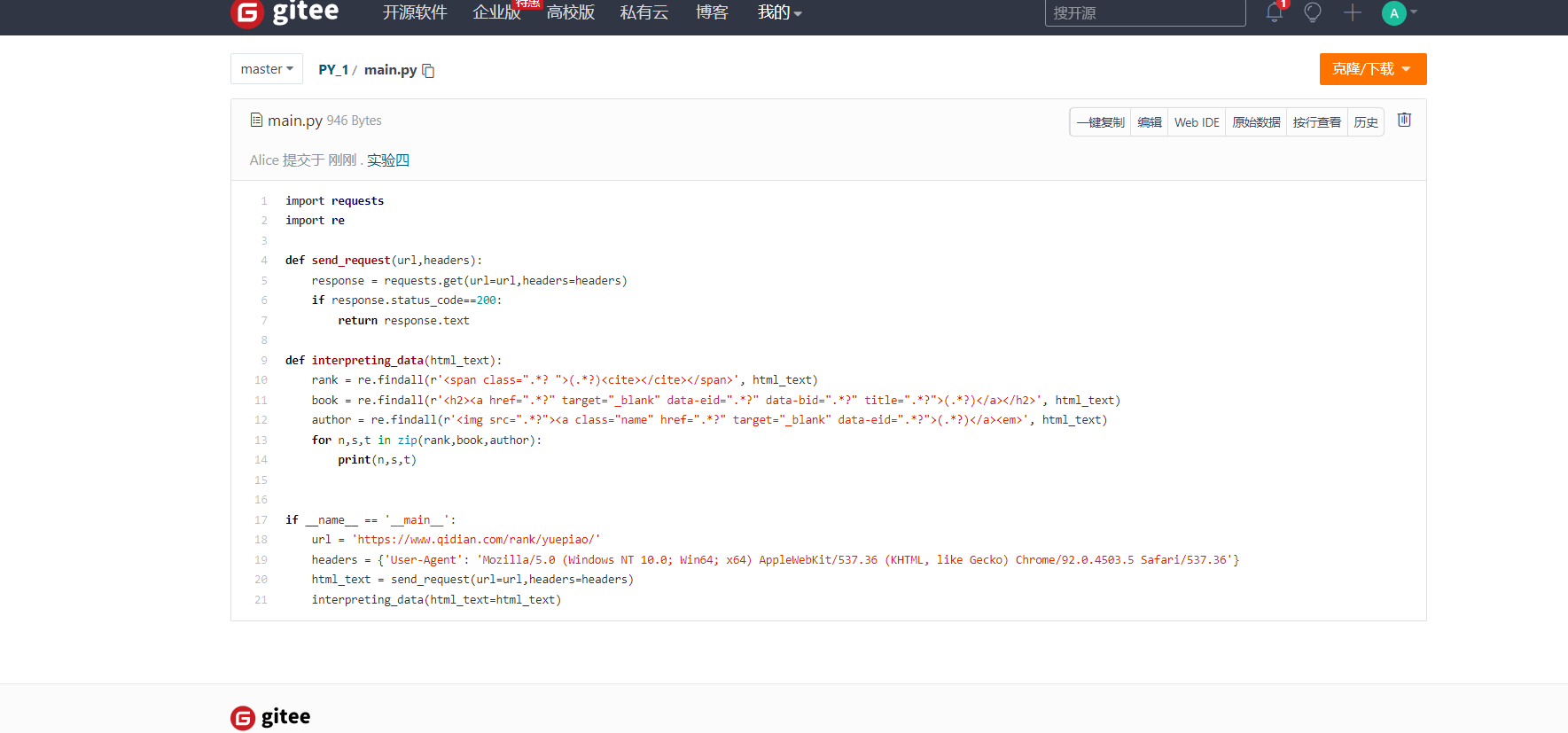
源代码
import requests
import re
def send_request(url,headers):
response = requests.get(url=url,headers=headers)
if response.status_code==200:
return response.text
def interpreting_data(html_text):
rank = re.findall(r'<span class=".*? ">(.*?)<cite></cite></span>', html_text)
book = re.findall(r'<h2><a href=".*?" target="_blank" data-eid=".*?" data-bid=".*?" title=".*?">(.*?)</a></h2>', html_text)
author = re.findall(r'<img src=".*?"><a class="name" href=".*?" target="_blank" data-eid=".*?">(.*?)</a><em>', html_text)
for n,s,t in zip(rank,book,author):
print(n,s,t)
if __name__ == '__main__':
url = 'https://www.qidian.com/rank/yuepiao/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4503.5 Safari/537.36'}
html_text = send_request(url=url,headers=headers)
interpreting_data(html_text=html_text)
学会了爬虫的基本原理与简单的爬虫,明白了python带来的方便便捷,程序还改进的空间,比如加入UI、查看更多的排名
通过这一个学期的学习,我掌握了大部分python语法应用,但在类这一方面还没有实践。python还有许多未知的领域,我应该进一步的学会python。在学习代码中要经常通过网络来学习,并且要多看多写代码。在编程的学习中还有掌握其他学科的知识,这样才能写出更好的程序。
人生苦短,我用python
