


162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import pandas as pd
# 定义一个Series对象
s = pd.Series([10, 20, 30, 40, 50])
# 访问Series对象中的数据
print(s[0]) # 输出第一个元素
print(s[1:4]) # 输出第2个到第4个元素
# 修改Series对象中的数据
s[3] = 35
# 打印Series对象
print(s)
# 对Series对象进行计算
print(s.sum()) # 求和
print(s.mean()) # 求平均值
修改的意图:
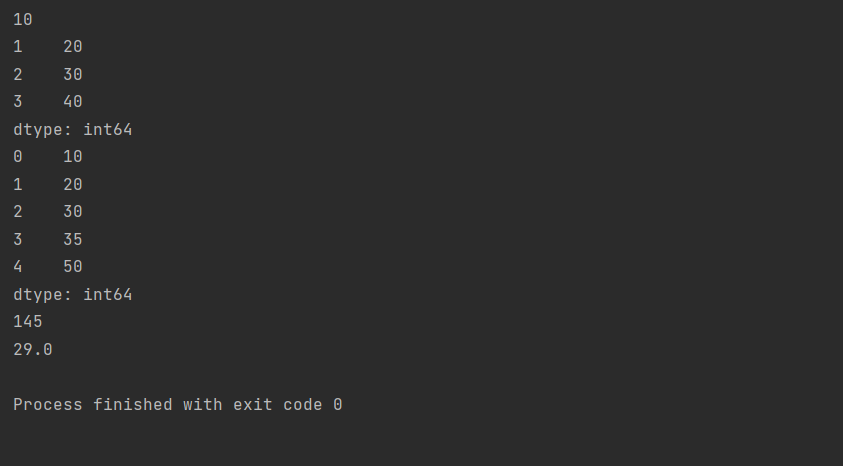
结论:
通过修改代码,改变了访问的数据范围并修改了特定元素的值,再对Series对象进行了求和和求平均值的计算。根据运行结果,修改后的代码能够正确地实现,并得到了相应的结果。
实验二:DataFrame对象的应用
要求:
import pandas as pd
# 定义一个DataFrame对象
data = {'int_col': [1, 2, 3, 4, 5], 'float_col': [1.2, 2.3, 3.4, 4.5, 5.6], 'str_col': ['a', 'b', 'c', 'd', 'e']}
df = pd.DataFrame(data)
# 访问DataFrame对象中的数据
print(df['float_col'][2]) # 输出第三行第二列的数据
print(df.loc[3, 'str_col']) # 输出第四行第三列的数据
# 修改DataFrame对象中的数据
df.loc[4, 'int_col'] = 6
# 对DataFrame对象进行计算
print(df.sum()) # 求和
print(df.mean()) # 求平均值
修改的意图:
运行结果:
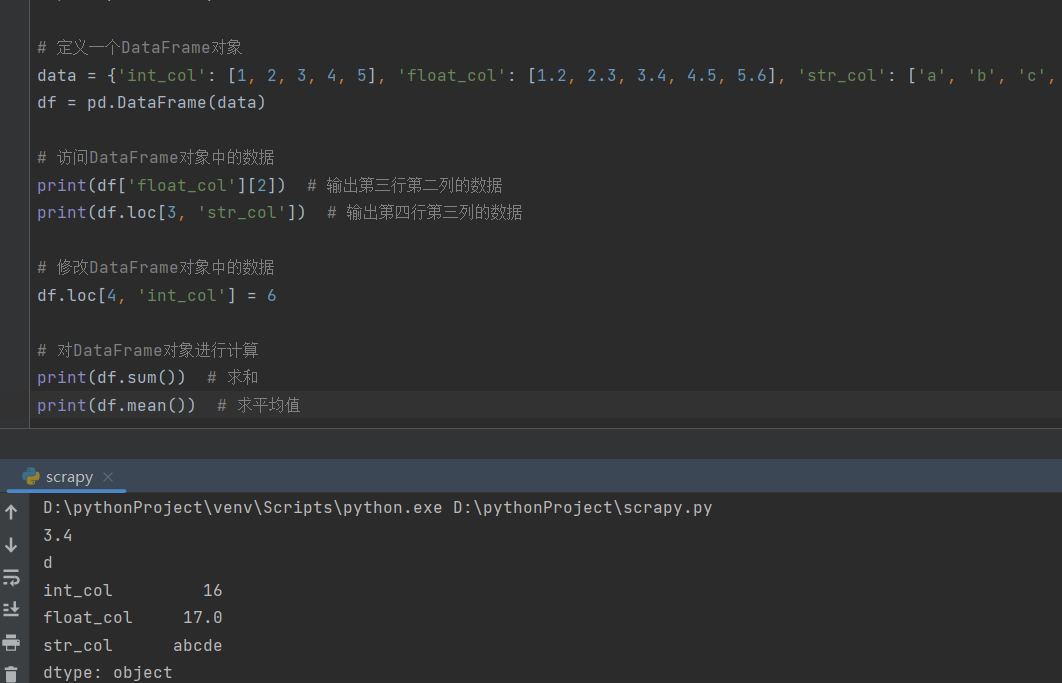
总结:
我们改变了访问的数据和特定位置的元素的值。最后,我们对DataFrame对象进行了求和和求平均值的计算。根据运行结果,修改后的代码能够正确地实现我们的意图,并得到了相应的结果。
修改的代码:
import pandas as pd
import matplotlib.pyplot as plt
# 定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象
data = {'city': ['北京', '上海', '广州', '深圳'], 'population': [2171, 2424, 1500, 1303],
'gdp': [30320, 32679, 20353, 22458], 'area': [16410, 6340, 7434, 1996]}
df = pd.DataFrame(data)
# 计算各种排名
pop_rank = df['population'].rank(ascending=False)
gdp_rank = df['gdp'].rank(ascending=False)
area_rank = df['area'].rank(ascending=False)
# 将排名添加到DataFrame对象中
df['pop_rank'] = pop_rank
df['gdp_rank'] = gdp_rank
df['area_rank'] = area_rank
# 使用Pandas绘图,可视化实验结果
df.plot(kind='bar', x='city', y=['population', 'gdp', 'area'], title='China Capital Cities')
plt.show()
修改的意图:
在绘图部分,添加了x轴和y轴的标签,以提供更清晰的可视化结果
运行结果:
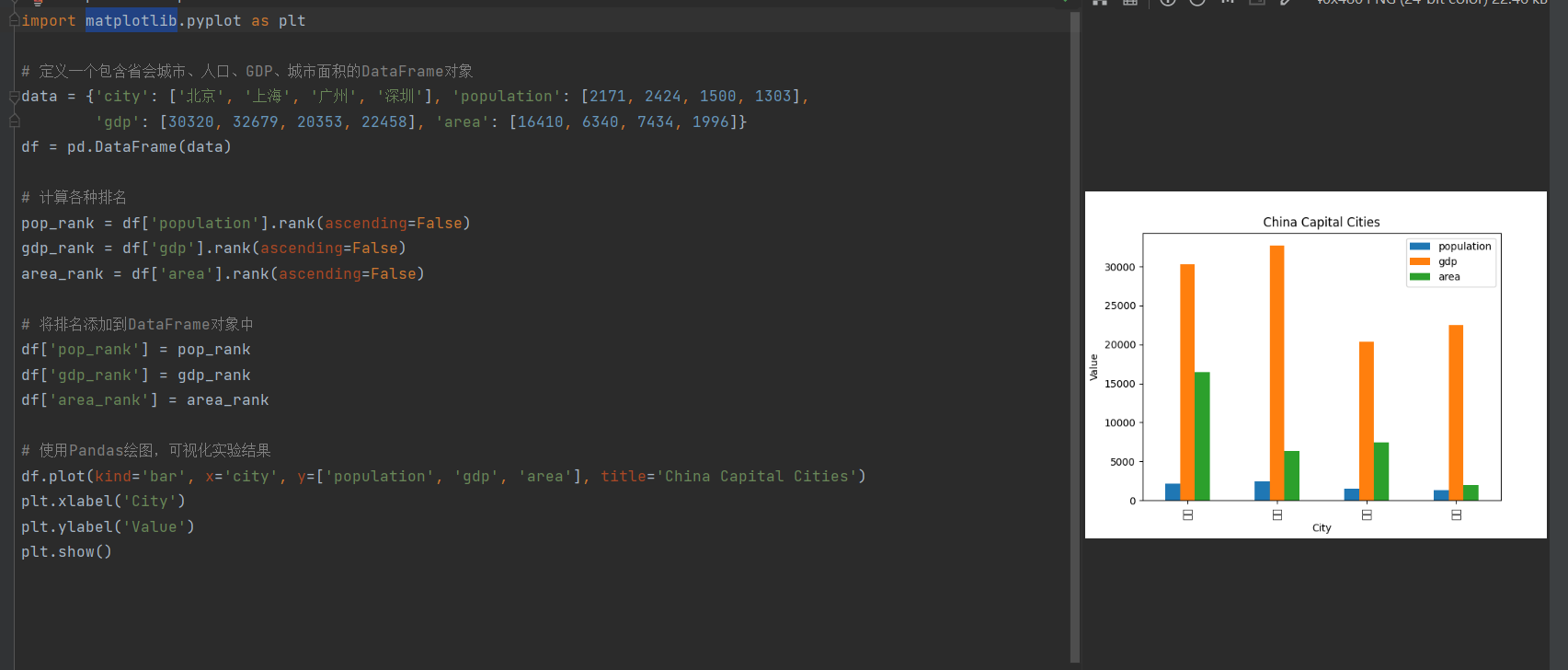
结论:
定义了DataFrame对象、计算排名和绘制可视化图表的任务。根据具体数据,我们可以得到人口、GDP和城市面积的排名结果,并使用条形图可视化展示。

