


162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
示例代码中注解有误已修改。程序运行结果:
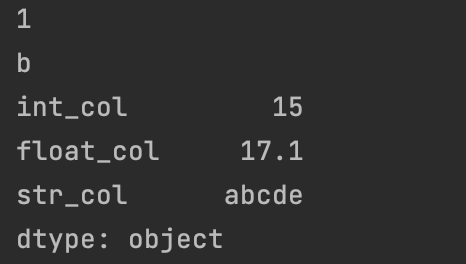
当然也有报错信息,错误信息表示在进行Pandas的均值计算时出现了数据类型错误。由于abcde不是数字,所以无法转换为浮点数,而在Pandas中计算均值前需要将数据转换为数值类型。
在Pandas中,负数索引是从尾部开始访问数据的,即-1对应的是最后一个元素、-2对应的是倒数第二个元素,以此类推。因此,可以使用s[-1]来访问Series对象中的最后一个元素。
如果在使用s[-1]时出现了报错,可能是由于索引越界导致的。例如,在一个包含5个元素的Series对象中,使用s[-6]或s[5]来访问元素时都会报错,因为它们超出了Series对象的索引范围。
另外,还需要注意的是,在一些特定情况下,若Series对象的索引不是整数类型,则可能会出现错误或者与预期不符的结果。比如,在一个标签索引为字符串的Series对象中,使用s[-1]进行访问时会出现错误。此时,可以使用s.iloc[-1](通过位置索引访问)或者s.tail(1)(获取最后一个元素)来获得最后一个元素。
于是 我将代码修改为
print(s.iloc[-1])便可以访问最后一个元素。
import pandas as pd
# 定义一个DataFrame对象
data = {'int_col': [1, 2, 3, 4, 5], 'float_col': [1.2, 2.3, 3.4, 4.5, 5.6], 'str_col': ['a', 'b', 'c', 'd', 'e']}
df = pd.DataFrame(data)
# 访问DataFrame对象中的数据
print(df['int_col'][0]) # 输出第一行第一列的数据
print(df.loc[1, 'str_col']) # 输出第三行第二列的数据
# 修改DataFrame对象中的数据
df.loc[2, 'float_col'] = 3.5
# 对DataFrame对象进行计算
print(df.sum()) # 求和
print(df.mean()) # 求平均值
解决这个问题有两种方法:
将非数字替换为NaN(not a number)
Pandas提供了一个replace()函数,可以用来将指定的值替换为另一个值。我们可以将非数字的值替换为NaN(Not a Number),然后再进行均值计算,这样就可以避免数据类型错误了。
df = df.replace('abcde', np.nan) print(df.mean()) # 求平均值
删除非数字行
我们也可以直接删除包含非数字的行,然后再进行均值计算。
df = df.dropna() print(df.mean()) # 求平均值
这两种方法都可以解决该问题,具体使用哪种方法取决于数据的实际情况。本次实验中显然采用第一种方法,将非数字的值替换为nan即可。
在定义dataframe对象之后添加一行代码
# 将非数字数据替换为NaN df = df.apply(pd.to_numeric, errors='coerce')即可
程序运行结果如下:
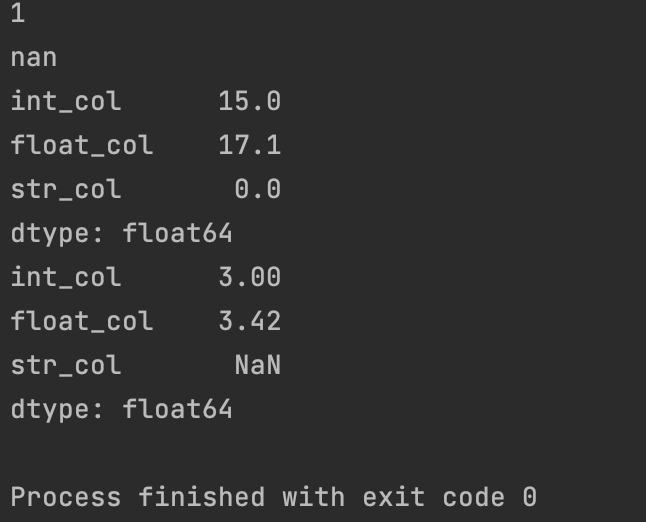
定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象; 计算各种排名,如人口最多的城市、GDP最高的城市等; 使用Pandas绘图,可视化上述实验结果。
import pandas as pd
import matplotlib.pyplot as plt
# 定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象
data = {'city': ['北京', '上海', '广州', '深圳'], 'population': [2171, 2424, 1500, 1303],
'gdp': [30320, 32679, 20353, 22458], 'area': [16410, 6340, 7434, 1996]}
df = pd.DataFrame(data)
# 计算各种排名
pop_rank = df['population'].rank(ascending=False)
gdp_rank = df['gdp'].rank(ascending=False)
area_rank = df['area'].rank(ascending=False)
# 将排名添加到DataFrame对象中
df['pop_rank'] = pop_rank
df['gdp_rank'] = gdp_rank
df['area_rank'] = area_rank
# 使用Pandas绘图,可视化实验结果
df.plot(kind='bar', x='city', y=['population', 'gdp', 'area'], title='China Capital Cities')
plt.show()
得到的结果如下:
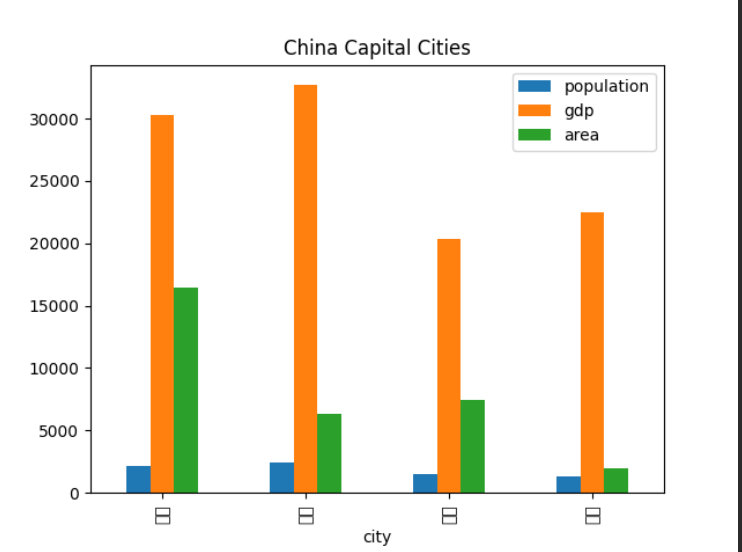
显然这张图并不是我们想要的,因为其中缺乏所需汉字,那我们就需要将其添加进去,根据报错信息得知:这是一个警告信息,因为绘图时使用的字体中缺少某些汉字。
这个报错信息是在使用matplotlib绘图时,出现了某些字形缺失的警告。具体原因是matplotlib默认字体中不包含你想显示的一些汉字,建议你更换字体或者安装相应的字体库来解决这个问题。
你可以尝试在代码中添加下面这句话:
plt.rcParams['font.family'] = 'Arial Unicode MS'
这样就可以通过指定Arial Unicode MS字体来显示中文了。如果你的电脑上没有安装该字体,需要先下载安装。
程序运行结果图如下:
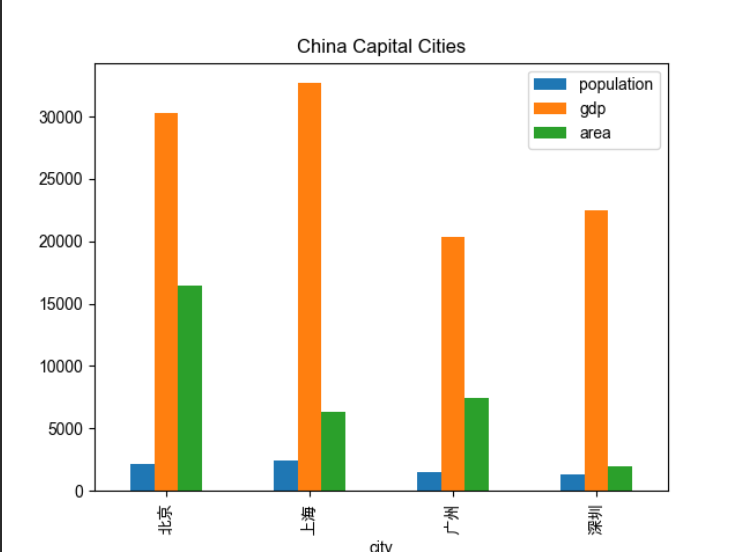
这样我们通过看图就可得知对应城市的人口,经济和占地面积。

