162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Numpy 和 Pillow在图像处理中的应用
1) 掌握Numpy的基本应用
2)掌握 Pillow的简单用法
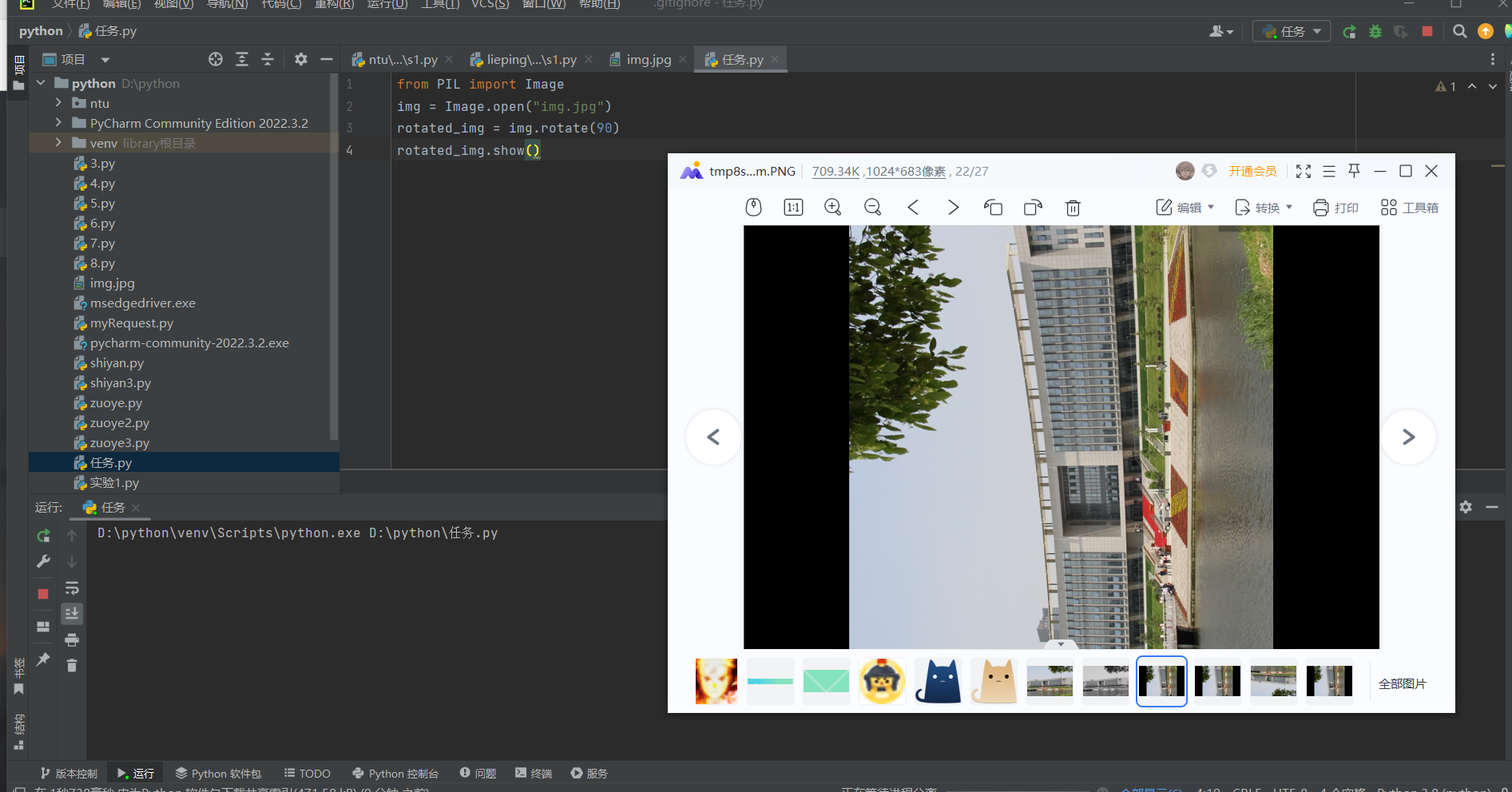
任务 1)从以下网站:南通大学[学校掠影](https://www.ntu.edu.cn/77/list.htm)任选一副图片下载,用Python程序显示原始图片。
代码:
from PIL import Image
img = Image.open('img.jpg')
img.show()
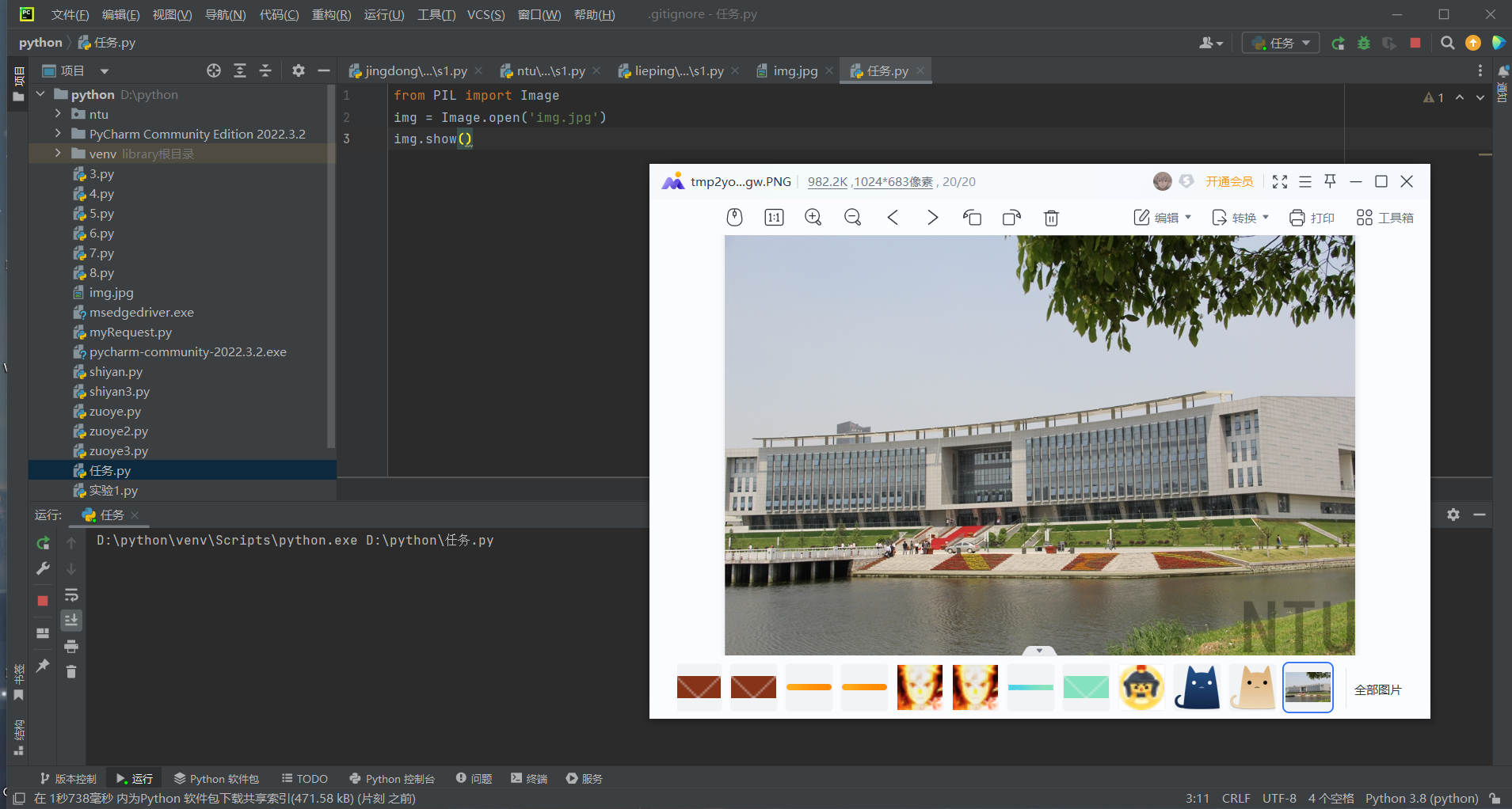
任务 2)将图片变成黑白图片,并用Python程序显示。
代码:
from PIL import Image
img = Image.open("img.jpg")
gray_img = img.convert('L')
gray_img.show()
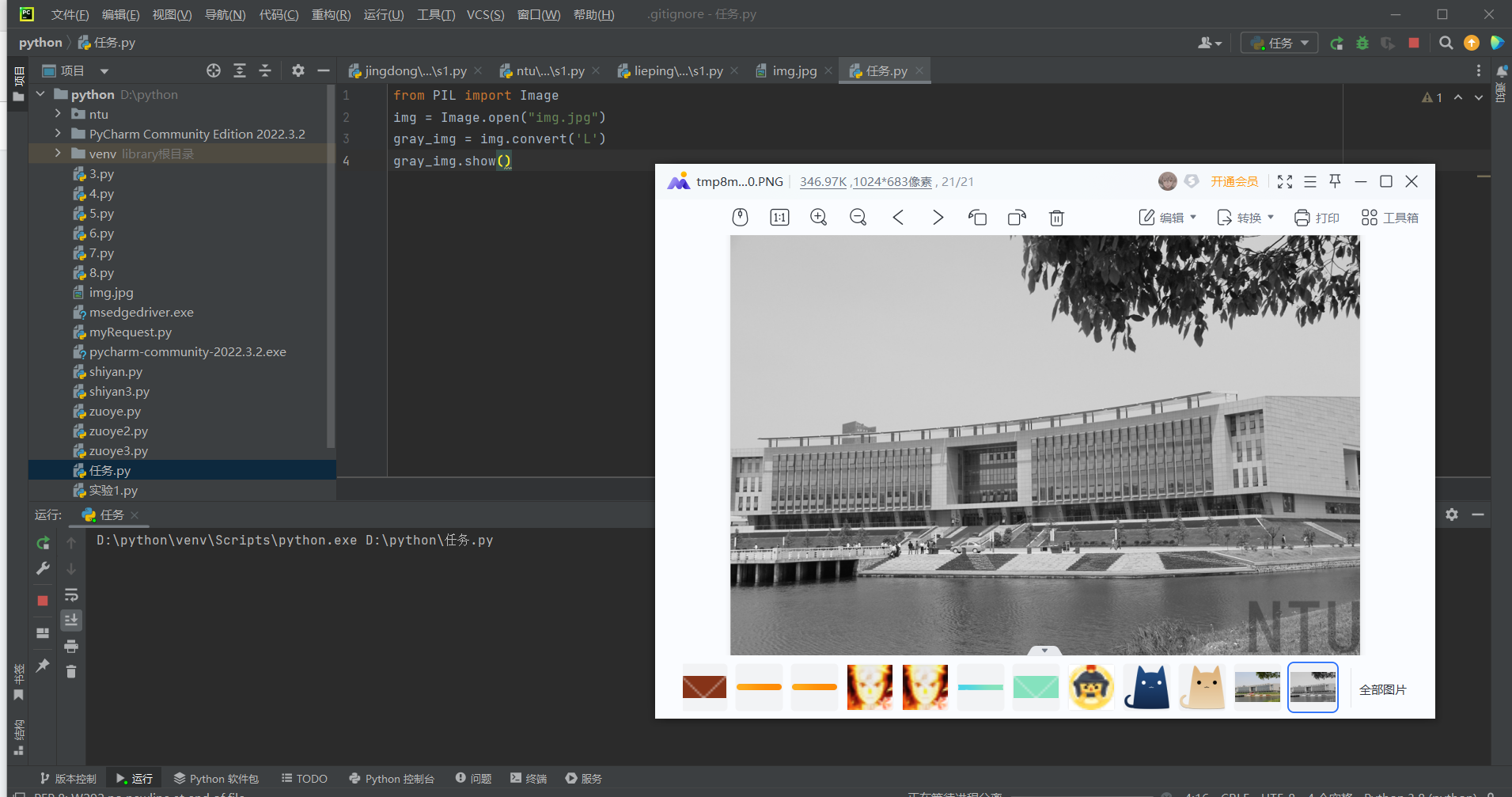
任务3)将图片左右翻转,并用Python程序显示。
代码:
from PIL import Image
img = Image.open("img.jpg")
img_lr = img.transpose(Image.FLIP_LEFT_RIGHT)
img_lr.show()
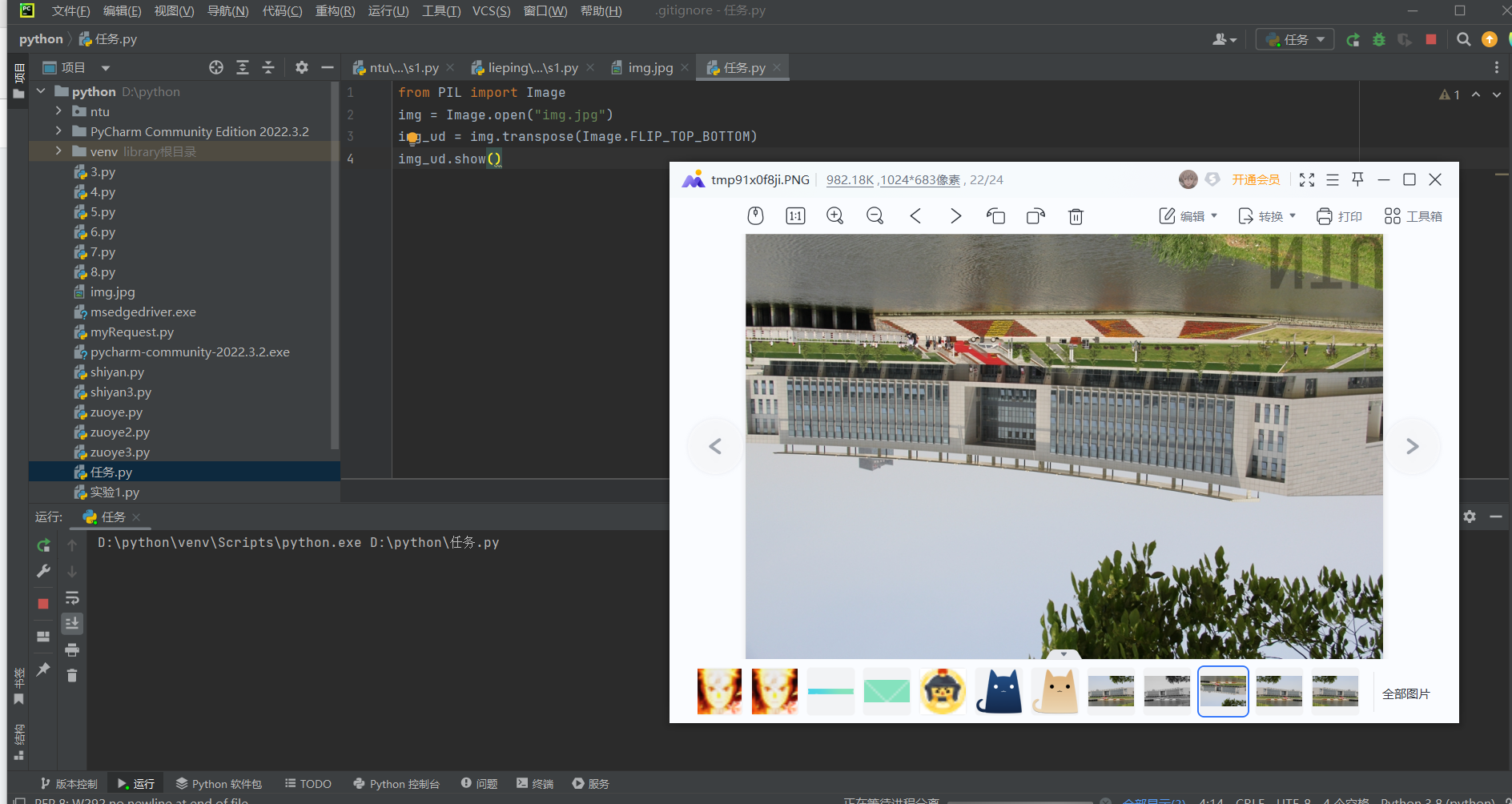
任务4)将图片上下翻转,并用Python程序显示。
代码:
from PIL import Image
img = Image.open("img.jpg")
img_ud = img.transpose(Image.FLIP_TOP_BOTTOM)
img_ud.show()
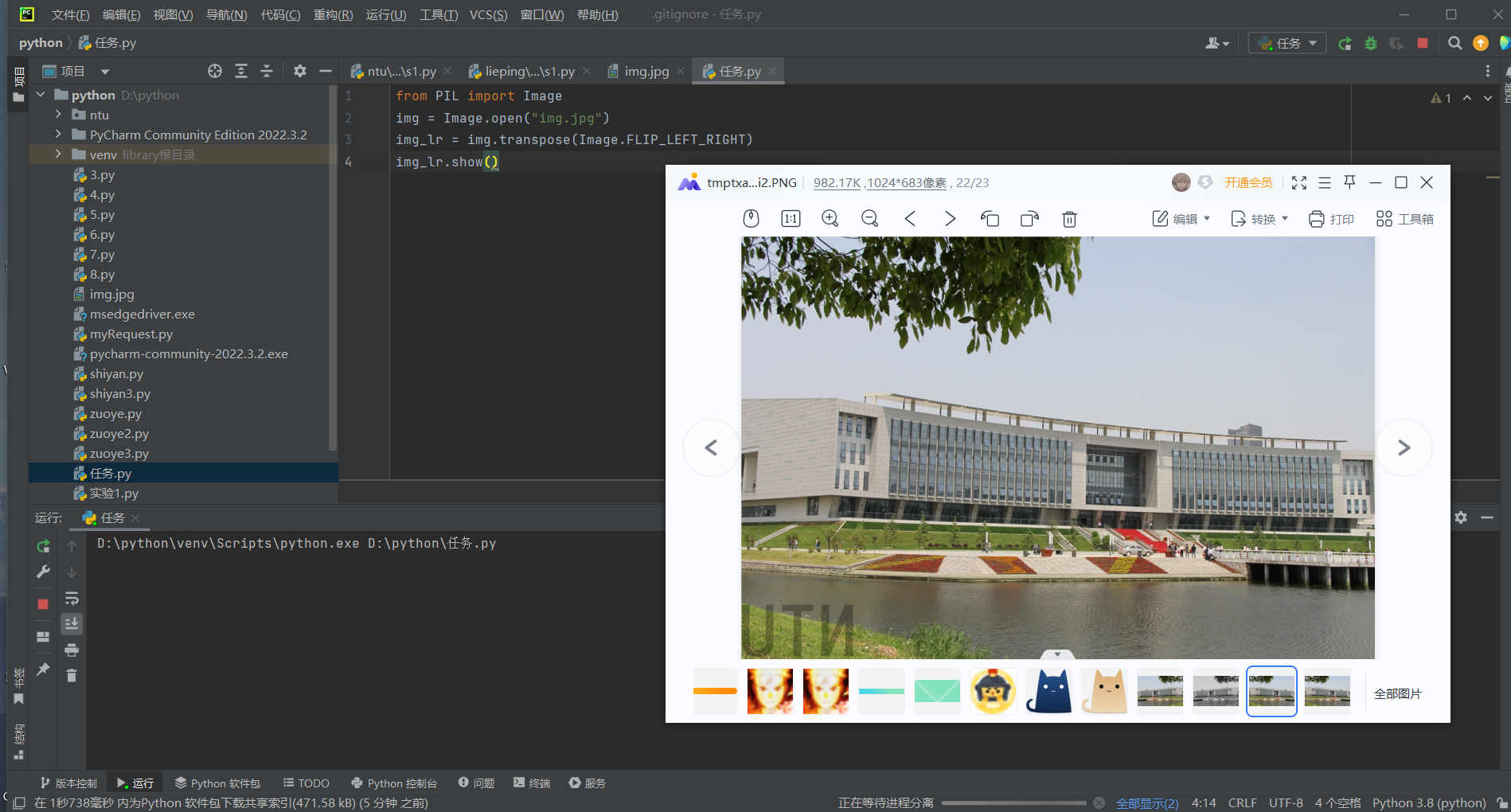
任务5)自己设想一种图片处理任务,描述清楚,并给出实现代码和程序显示图片结果。
将图片旋转90度。
代码:
from PIL import Image
img = Image.open("img.jpg")
rotated_img = img.rotate(90)
rotated_img.show()