


1,470
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享TensorFlow 是什么?它是一个开源的机器学习框架,由 Google Brain 团队开发。它支持各种各样的机器学习算法和技术,包括深度学习、强化学习、自然语言处理等,并提供了一种易于使用的 API,使得开发者可以方便地构建和训练模型。TensorFlow 还支持分布式训练,可以通过多个计算机节点并行处理数据,提高训练效率。 
 在开始 TensorFlow 编程之前,需要先安装 TensorFlow。推荐使用 pip 进行安装。在命令行中输入以下命令即可安装最新版本的 TensorFlow:
在开始 TensorFlow 编程之前,需要先安装 TensorFlow。推荐使用 pip 进行安装。在命令行中输入以下命令即可安装最新版本的 TensorFlow:
pip install tensorflow
如果你使用的是 GPU 版本的 TensorFlow,需要先安装对应的 CUDA 和 cuDNN 库。具体安装步骤可以参考 TensorFlow 官方文档 : 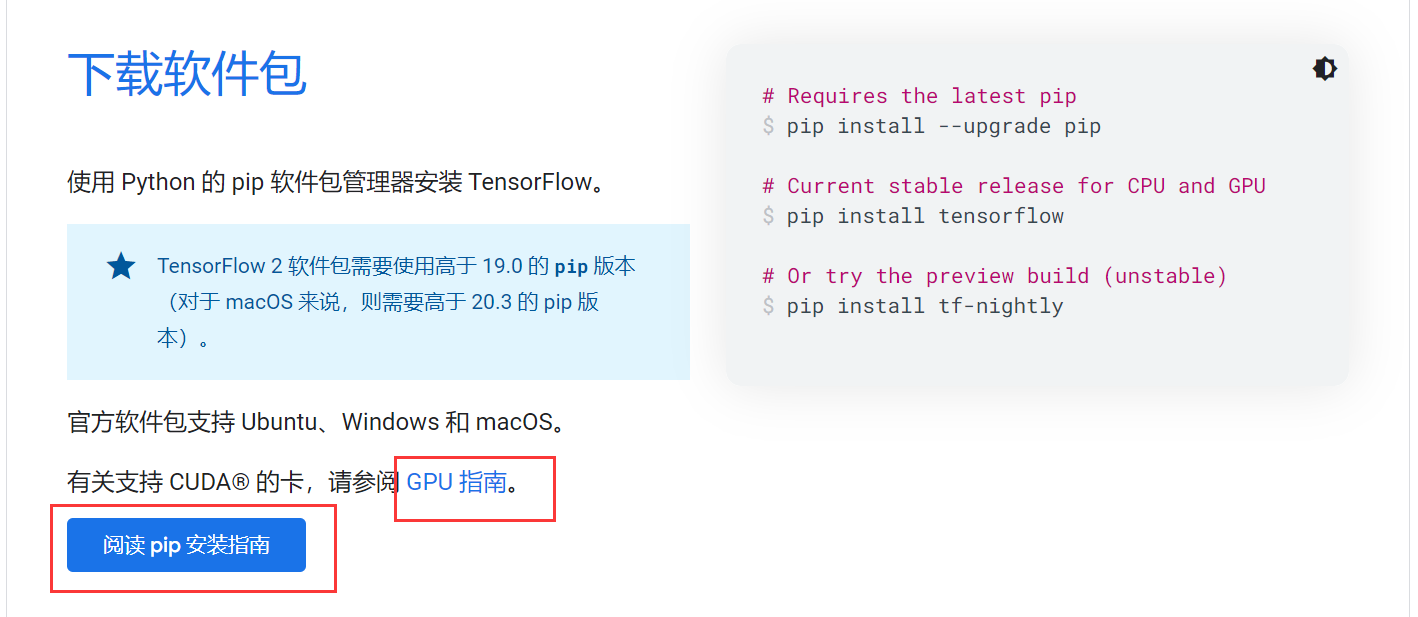
张量 TensorFlow 中的基本数据结构是张量(tensor)。张量是一种多维数组,可以表示标量、向量、矩阵等各种数据形式。在 TensorFlow 中,张量不仅用来存储数据,还用来表示计算图中的节点。张量的维度数称为秩(rank),张量的形状称为其维度(dimension)。例如,一个标量可以表示为秩为 0 的张量,一个向量可以表示为秩为 1 的张量,一个矩阵可以表示为秩为 2 的张量。
计算图 TensorFlow 中的计算图是一个有向无环图,由一系列节点和边组成。节点表示操作(operation),边表示数据(tensor)流动的方向。计算图在 TensorFlow 中的作用是描述模型的计算过程,所有的计算都在计算图中进行。在计算图中,输入数据从图的输入节点开始流动,经过一系列操作后,最终输出结果。例如,构建一个简单的计算图来计算两个数字的和:
import tensorflow as tf # 创建常量节点 a = tf.constant(2) b = tf.constant(3) # 创建加法节点 c = tf.add(a, b) # 创建 TensorFlow 会话 sess = tf.Session() # 运行计算图,并输出结果 result = sess.run(c) print(result) # 关闭 TensorFlow 会话 sess.close()
在这个例子中,常量节点 a 和 b 表示输入数据,加法节点 c 表示加法操作。在运行计算图时,输入数据从节点 a 和 b 开始,通过加法节点 c 计算出结果,最终输出。
常量和变量 在 TensorFlow 中,常量和变量都是张量,但常量的值无法改变,而变量的值可以在训练过程中不断更新。创建常量节点可以使用 tf.constant 函数,创建变量节点可以使用 tf.Variable 函数。
import tensorflow as tf # 创建常量节点 a = tf.constant(2) b = tf.constant(3) # 创建变量节点 x = tf.Variable(0, name='x') # 创建加法节点 c = tf.add(a, b) # 创建赋值节点 assign_op = tf.assign(x, c) # 创建 TensorFlow 会话 sess = tf.Session() # 初始化变量 sess.run(tf.global_variables_initializer()) # 运行计算图,并输出结果 result = sess.run(assign_op) print(result) print(sess.run(x)) # 关闭 TensorFlow 会话 sess.close()
在这个例子中,变量节点 x 初始值为 0,在运行计算图时,将加法节点 c 的结果赋值给变量节点 x。注意,在修改变量值之前,需要先初始化所有变量。
占位符 占位符(placeholder)用于表示输入数据,在模型训练过程中,通过填充不同的数据来进行训练。占位符可以看作是一种空白模板,在运行计算图时,需要将占位符填充上具体的数值。创建占位符节点可以使用 tf.placeholder 函数。
import tensorflow as tf
# 创建占位符节点
x = tf.placeholder(tf.float32, [None, 2])
y = tf.placeholder(tf.float32, [None, 1])
# 创建变量节点
w = tf.Variable(tf.zeros([2, 1]))
b = tf.Variable(tf.zeros([1]))
# 创建线性模型
y_pred = tf.matmul(x, w) + b
# 创建损失函数节点
loss = tf.reduce_mean(tf.square(y_pred - y))
# 创建训练操作节点
train_op = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss)
# 生成数据集
import numpy as np
x_train = np.random.rand(100, 2)
y_train = np.sum(x_train, axis=1, keepdims=True)
# 创建 TensorFlow 会话
sess = tf.Session()
# 初始化变量
sess.run(tf.global_variables_initializer())
# 训练模型
for i in range(1000):
_, loss_val = sess.run([train_op, loss], feed_dict={x: x_train, y: y_train})
if i % 100 == 0:
print('step {}: loss={}'.format(i, loss_val))
# 关闭 TensorFlow 会话
sess.close()
在这个例子中,占位符节点 x 和 y 分别表示输入数据和标签,在训练过程中,需要将输入数据和标签填充上具体的数值。在每次训练时,通过 feed_dict 参数将数据填充到占位符中。
Keras API Keras 是一个高阶的深度学习 API,可以为 TensorFlow 提供易于使用的抽象层,使得开发者可以更加方便地构建和训练深度学习模型。Keras 实现了几乎所有常见的深度学习算法和技术,例如卷积神经网络、循环神经网络、自动编码器等。
import tensorflow as tf
from tensorflow import keras
# 创建数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 构建模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
# 编译模型
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)
在这个例子中,使用 Keras 构建了一个简单的神经网络模型,用于对手写数字进行识别。模型包括一个输入层(28x28),一个隐藏层(128 个神经元)和一个输出层(10 个神经元)。通过调用 compile 函数来编译模型,并指定优化器、损失函数和评估指标。然后通过调用 fit 函数来训练模型,指定训练集和训练轮数。最后通过调用 evaluate 函数来评估模型性能。
TensorFlow 提供了丰富的 API 和工具,使得开发者可以方便地构建和训练机器学习模型。本教程介绍了 TensorFlow 的基础概念和常用 API,包括常量和变量、占位符和 Keras API 等。这些知识是使用 TensorFlow 进行机器学习和深度学习研究的必备基础。



