162
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import pandas as pd
# 定义一个Series对象
s = pd.Series([1, 2, 3, 4, 5])
# 访问Series对象中的数据
print(s[0]) # 输出第一个元素
print(s[3:5]) # 输出第4个到第5个元素
# 修改Series对象中的数据
s[0] = 10086
# 打印Series对象
print(s)
# 对Series对象进行计算
print(s.sum()) # 求和
print(s.mean()) # 求平均值

(1)定义一个DataFrame对象,包含3个列,每列分别为整数、浮点数和字符串类型;
(2)访问、修改DataFrame对象中的数据;
(3)对DataFrame对象进行计算,如求和、求平均值等。
(1)定义一个DataFrame对象,包含3个列,每列分别为整数、浮点数和字符串类型
data = {
'Integers': [1, 2, 3],
'Floats': [1.1, 2.2, 3.3],
'Strings': ['a', 'b', 'c']
}
df = pd.DataFrame(data)
(2)访问、修改DataFrame对象中的数据
value = df.iloc[0, 0]
print(value)
df.iloc[0, 0] = 4
print(df)
(3)对DataFrame对象进行计算,如求和、求平均值等。
sum = df['Integers'].sum()
print(sum)
mean = df['Integers'].mean()
print(mean)
运行结果:

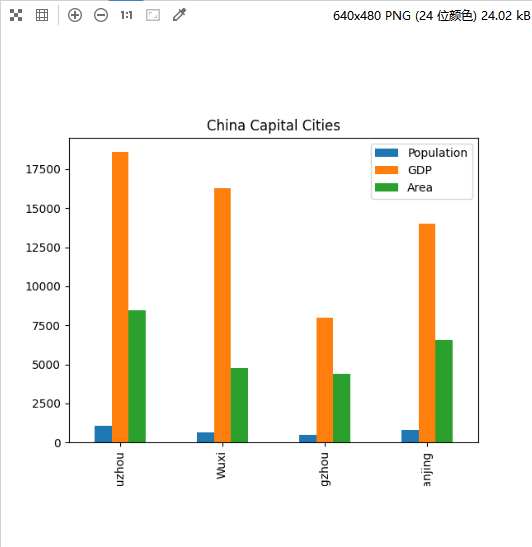
(1)定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象;
(2)计算各种排名,如人口最多的城市、GDP最高的城市等;
(3)使用Pandas绘图,可视化上述实验结果。
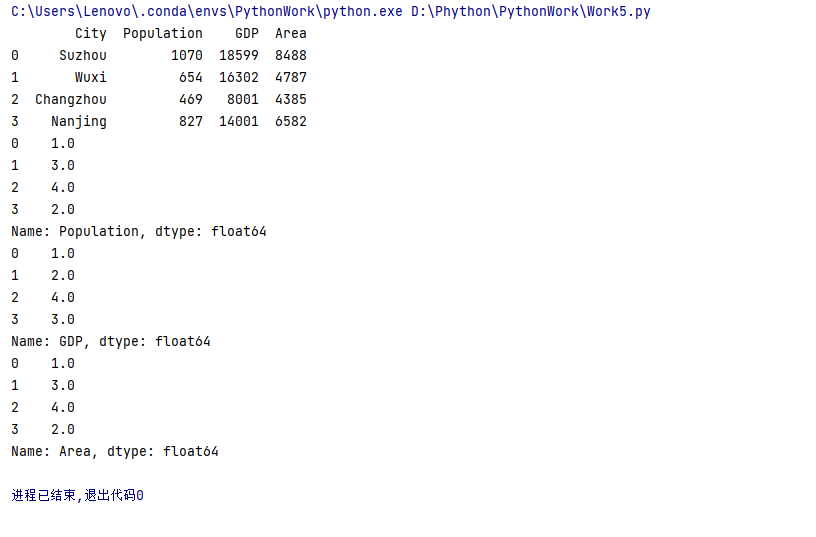
(1)定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象
data = {
'City': ['Suzhou', 'Wuxi', 'Changzhou', 'Nanjing'],
'Population': [1070, 654, 469, 827],
'GDP': [18599, 16302, 8001, 14001],
'Area': [8488, 4787, 4385, 6582]
}
df = pd.DataFrame(data)
(2)计算各种排名,如人口最多的城市、GDP最高的城市等
# 计算各种排名
pop_rank = df['Population'].rank(ascending=False)
gdp_rank = df['GDP'].rank(ascending=False)
area_rank = df['Area'].rank(ascending=False)
print(pop_rank)
print(gdp_rank)
print(area_rank)
(3)使用Pandas绘图,可视化上述实验结果。
# 使用Pandas绘图,可视化实验结果
df.plot(kind='bar', x='City', y=['Population', 'GDP', 'Area'], title='China Capital Cities')
plt.show()
运行结果: