144
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享实验四 综合实践
课程:《Python程序设计》
班级: 2212
姓名:王澜
学号:20221211
实验教师:王志强
实验日期:2022年5月20日
必修/选修: 公选课
1.实验内容:利用爬虫,实现自动化下载网站视频、文件。
我做的是用爬虫爬取豆瓣网的图片和视频,分为主函数、文件测试、和测试代码三个主要部分
2.实验过程和结果
(一)实验代码
1.主函数
# 利用python爬虫实现自动化下载网络视频、文件等
# 开发环境:Windows 10 PyCharm 2022.2.2(Professional)
# python版本:python 3.7
# 采用bs4进行网页解析
from random import randint
import requests
import savefile
import time
from bs4 import BeautifulSoup
default_urls = [
'https://movie.douban.com/subject/3878007/',
'https://movie.douban.com/trailer/240074/#content',
'https://movie.douban.com/trailer/241197/#content'
]
header = {
'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 '
'Safari/537.36',
}
picture = 0
skip_picture = 0
video = 0
skip_video = 0
picture_failed = []
video_failed = []
def get_type(url):
"""
:param url: 目标资源的URL,一般来说,URL会携带有目标文件的格式和命名信息,并且在URL的最后 一个斜杠后
:return: 只取最后一个.后面的内容,通常代表文件格式
"""
start = url.rfind('.')
this_type = url[start:] # 切片
return this_type
def download_picture(src):
wait_time = randint(1, 2) # 随机生成等待时间,模拟真实用户操作,防止被反爬虫
for url in src:
print("尝试下载:", url)
response = requests.get(url=url)
if response.status_code == 200:
data = response.content # 获取文件二进制内容
# print(len(data))
if len(data) < 1000:
# 图片过小认为是素材,不予存储
print("下载跳过")
global skip_picture # 声明全局变量
skip_picture = skip_picture + 1
continue
img_type = get_type(url)
global picture
picture = picture + 1
name = str(picture) + img_type
savefile.save_picture(data, name) # data表示二进制内容,命名是刚刚剪切的字符串
else:
print(url, '下载失败')
picture_failed.append(url) # 存储异常信息
continue
time.sleep(wait_time)
def download_video(src):
wait_time = randint(1, 2)
for url in src:
print("尝试下载:", url)
response = requests.get(url=url)
if response.status_code == 200:
data = response.content
# print(len(data))
if len(data) < 10000:
# 体积过小认为是素材
print("下载跳过")
global skip_video
skip_video = skip_video + 1
continue
video_type = get_type(url)
global video
video = video + 1
name = str(video) + video_type
savefile.save_video(data, name)
else:
print(url, '下载失败')
video_failed.append(url)
continue
time.sleep(wait_time)
def analyze_resource_types(html_file):
with open(html_file, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
# 查找所有的链接标签<video>
video_tags = soup.find_all('video')
# 查找所有的图像标签 <img>
img_tags = soup.find_all('img')
src_list = []
src_list.clear()
savefile.clear_video() # 清空预备文件夹
for tag in video_tags:
# 根据tag内容选择bs4筛选方式
video_src = tag.source['src']
if video_src:
src_list.append(video_src)
if src_list:
download_video(src=src_list)
src_list.clear()
savefile.clear_picture() # 清空预备文件夹
for tag in img_tags:
# 根据tag内容选择bs4筛选方式
this_src = tag.get('src')
if this_src:
src_list.append(this_src)
if src_list:
download_picture(src=src_list)
print('Spider Over!')
print(picture, "pictures downloaded")
print(skip_picture, "picture skipped!")
print(len(picture_failed), "pictures failed!")
if picture_failed:
print(picture_failed)
print()
print(video, "videos downloaded")
print(skip_video, "video skipped!")
print(len(video_failed), "videos failed!")
if video_failed:
print(video_failed)
def spider(*urls):
url = urls[0]
if len(url) == 0:
# 如果没有输入采取默认地址
url = default_urls[2]
print("开始爬取:", url)
response = requests.get(url=url, headers=header)
if response.status_code != 200:
# 访问失败
print(f'Error get:{url}')
print("Maybe not enter right URL!")
exit(0)
html = response.content.decode('utf-8')
savefile.savefile_text(html, 'index.html')
analyze_resource_types('index.html')
def main():
# url = input("请输入要爬取的网址")
url = ''
spider(url)
# 主程序
if __name__ == '__main__':
main()
2.文件测试的代码
import os
import shutil
video_folder = "Video"
picture_folder = "Picture"
def clear_folder(path):
"""清空文件夹函数
:param path: 需要清空文件夹的路径
:return:
"""
try:
shutil.rmtree(path)
except FileNotFoundError:
print("建立文件夹")
finally:
os.mkdir(path)
def savefile_text(content,path):
"""将二进制文件存储为目标名称的视频文件文件(名字里面需要包含文件格式)
:param path: 文件路径
:param content: 文件的字符串内容
:return: 是否成功存储
"""
try:
file = open(path, "w", encoding='utf-8') # 打开文件以进行写入
bytes_written = file.write(content) # 写入数据并获取写入的字节数
file.close() # 关闭文件
if bytes_written == len(content):
print(path, "写入成功")
return True
else:
print(path, "写入失败")
return False
except IOError:
print("写入文件时发生错误")
return False
def savefile_binary(content, path):
"""将二进制文件存储为目标名称的视频文件文件(名字里面需要包含文件格式)
:param path: 文件路径
:param content: 文件的二进制内容
:return: 是否成功存储
"""
try:
file = open(path, "wb") # 打开文件以进行写入
bytes_written = file.write(content) # 写入数据并获取写入的字节数
file.close() # 关闭文件
if bytes_written == len(content):
print(path, "写入成功")
return True
else:
print(path, "写入失败")
return False
except IOError:
print("写入文件时发生错误")
return False
def clear_video():
clear_folder(path=video_folder)
def save_video(content, name):
"""保存视频的函数,本质上是调用了savefile_binary,封装了文件夹
:param content: 二进制内容
:param name: 存储名称
:return:
"""
path = video_folder + '/' + name
return savefile_binary(content, path)
def clear_picture():
clear_folder(path=picture_folder)
def save_picture(content, name):
path = picture_folder + '/' + name
return savefile_binary(content, path)
3.测试代码
from bs4 import BeautifulSoup
html = '''
<video class="video-js vjs-douban" id="player-html5-240074">
<source src="https://vt1.doubanio.com/202305202059/7670e86d6a346fd63191b99b767d0115/view/movie/M/402400074.mp4" title="" type="video/mp4"/>
</video>
'''
html_file = "index.html"
file = open(html_file, 'r', encoding='utf-8')
soup = BeautifulSoup(file, 'html.parser')
video_tag = soup.find_all('video')
tag = video_tag[0]
src_attribute = tag.source['src']
file.close()
print(tag)
print(src_attribute)
(二)运行结果
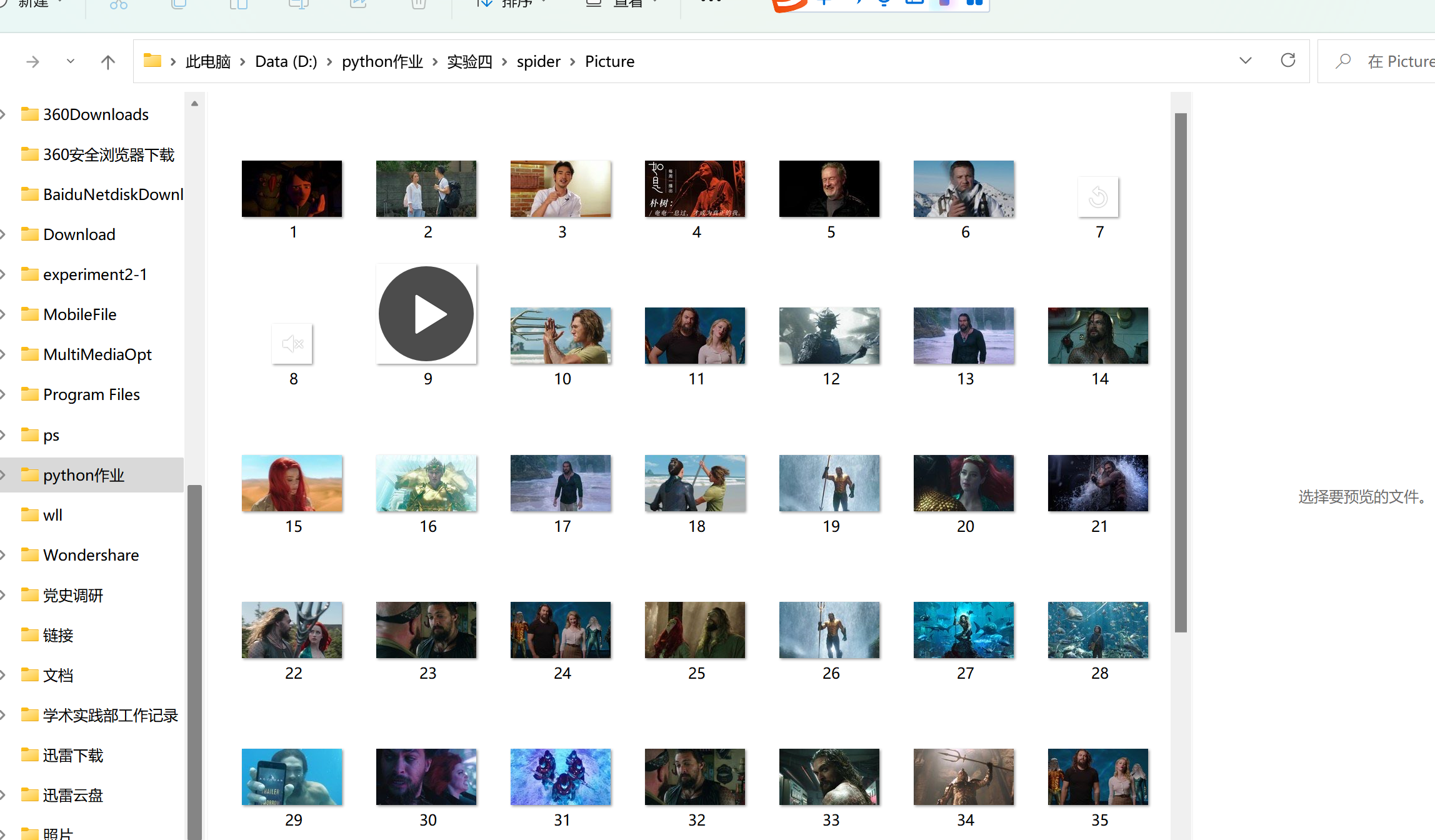
我通过此程序爬取了豆瓣网的一个视频和50张图片储存在电脑中。
下面是实验结果
爬取的照片
爬取的视频
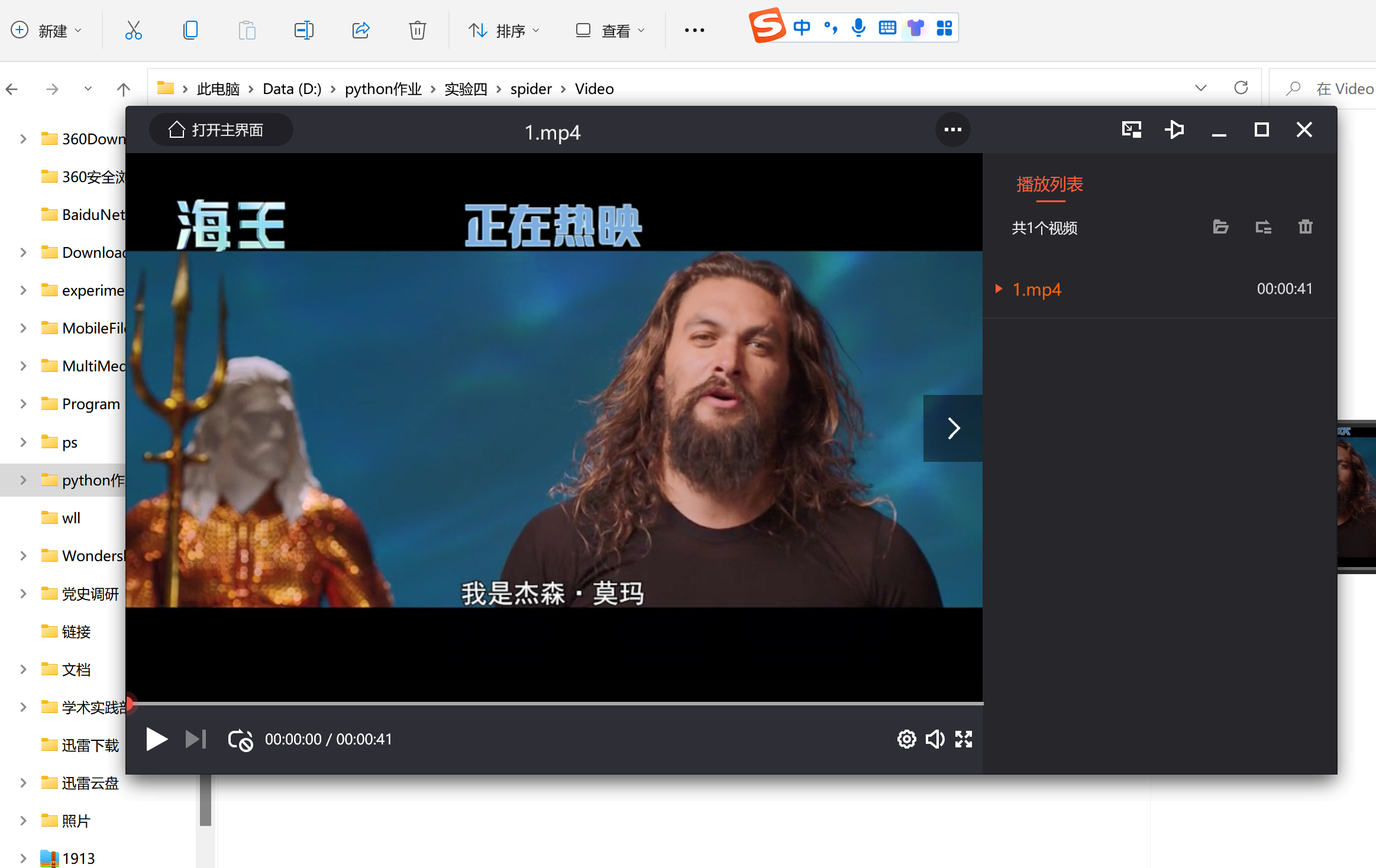
演示视频放在压缩包里了,老师可以看压缩包里的视频。
选择爬取这个豆瓣是因为豆瓣的cp组比较好,我寒假时一直在豆瓣磕一对cp,就想能不能直接爬取豆瓣来保存他们的照片,最后在自己的编写下和朋友的帮助下最终完成了这个小程序,说实话,我并没有完全掌握这个代码,在多次求助下,运用大致框架,在结合所学的一些知识写完了小程序。最终写出来相对完整的代码,最让我头疼的是在哪里去储存这些图片,不能最后什么也找不到,找不到最后存哪里,还有就是怎么去爬取,利用的这个网址能不能是客户自己输入的,可是还是能力有限,只能自己在源代码里修改爬取的网址,不能做到像一个小程序和APP一样,可以由用户自己决定爬取的内容,还是存在一定的局限性,所以我想以后可以自己做一个可以在手机端或者电脑端能使用的小程序。
从
“人生苦短,我用python”
开始
到
“进程已结束,退出代码0”
终止
这学期的晚课,可以说,python从一开始的折磨我,到后来的渐渐和解,到最后一起合作,完成一个又一个实验报告,我得到的收获不仅仅局限于计算机的一行行代码中,这背后所包含的道理和经验是我永远拥有的,我知道了csdn这个强大的平台,什么都有,我还收到了王老师赠予的csdn的小奖章,还有知道了遇到自己从未接触的领域时自己原来是可以放轻松,不用那么紧绷,如临大敌一般怕python,就平常心去踏踏实实学习就好,跟着志强老师一步步学习就够了,不懂的就在csdn上找能解决的方法,是在不行再去求助同学。总之,ddl的最后一秒,总能看到我的身影,但是我还是也走过来了。
对于课程的建议,我想的是老师可以将课上的讲义发给我们,课上提问的时候,可以多多抽取下一学期的朋友哦,多多益善,越多越好,这学期倒是真的每次抽人的时候,我都有点忐忑,嗯,这方面没做好,以后有机会,尽量不怕老师提问hh
有一个问题是,在实验二和实验三之间感觉难度跨度太大,我当时有点懵了,完全不知道怎么写这个新的实验报告,就好像是从十楼突然登上探月飞船,完全崩溃了,啥也不懂,怎么突然就加密解密,客户端、服务端了,有点希望就是王卡西老师可以针对以后的基础比较薄弱的同学可以有一个帮助小组,让有一些编程基础的同学当组长,组长可以加分,让组长带带像我的这种小白们。
还希望王老师,以后,可以,多布置点实验,不怕少的。
最大的感悟就是python比C语言简单多了,我真怵C语言,没选错课(*^▽^*),以后看见王老师的课还选。