


42
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计入门》
班级: 2242
姓名: AWL
学号:20224204
实验教师:WZQ
实验日期:2023年5月25日
必修/选修: 专选课
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
1.实验分析
互联网时代下,数据的重要性与日俱增。爬虫技术常应用于搜索引擎、数据采集、广告过滤、大数据分析等领域,可以及时获取海量数据,提高工作效率。例如在党政机关中也可利用爬虫技术,广泛集中民意,了解民生所需,更好做出宏观决策。在这里设计实验,通过爬取哔哩哔哩网页视频弹幕,并制作词云,了解观众的核心观点与想法,利于视频制作者进一步优化视频内容,调整制作方向,提高视频质量。
2.设计
1)这里使用到的有之前学过的:爬虫技术,发送网页请求,正则表达式,jiaba分词等。
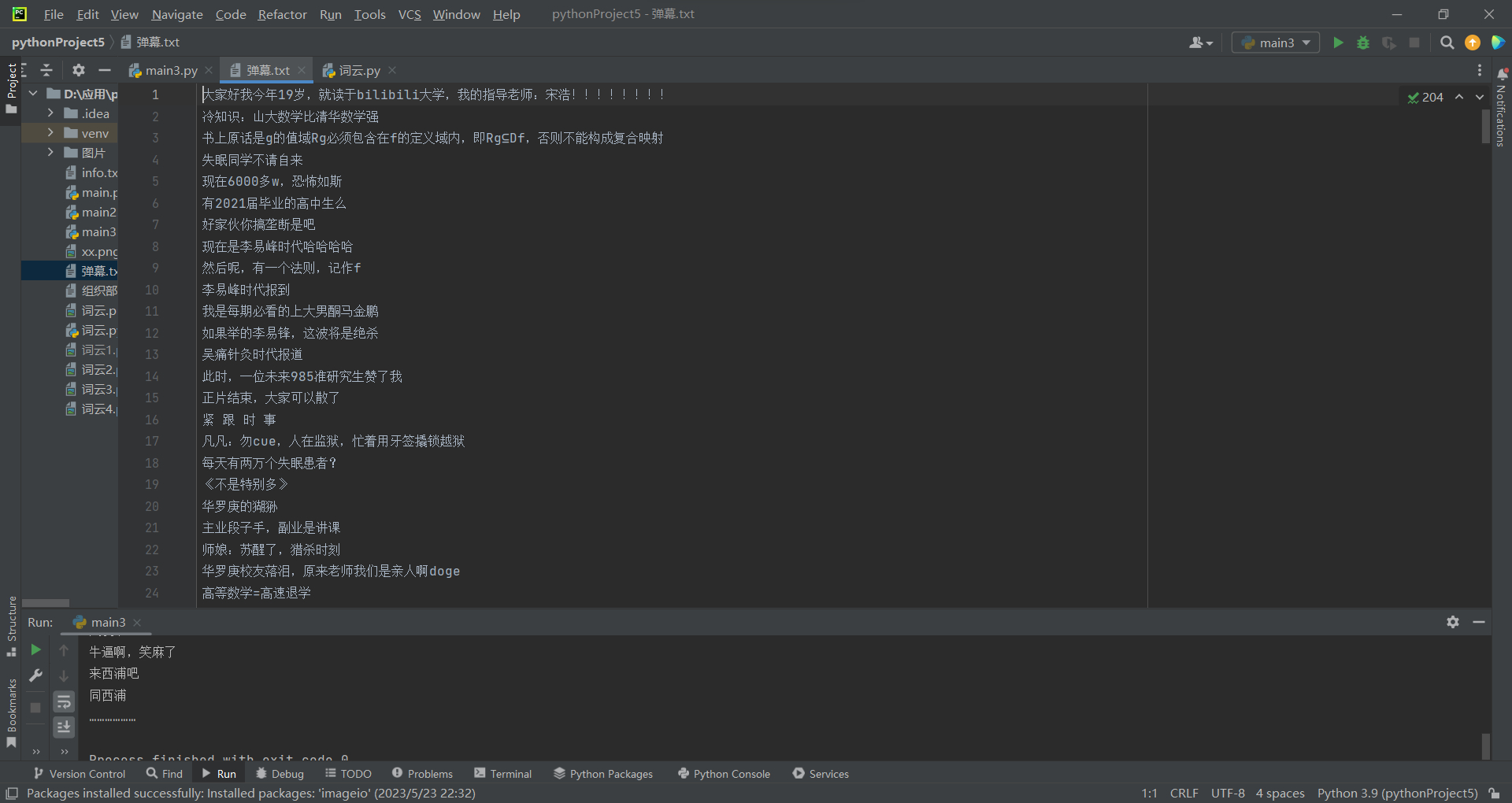
2)先利用爬虫技术,对网页发送请求,获取弹幕数据,保存为“弹幕.txt”文本;后读取文本,使用jieba分词,将文本由列表转换为字符串,利用词云库最终生成词云图。
3.实现过程
因为对相关编码的不熟悉,本次实验在哔哩哔哩平台上寻找教学视频后,自学编写完成的。
1)爬虫环节:安装requests库,输入浏览器url网址与headers请求头,发送请求并接受弹幕数据后储存数据。


4.结果
1)爬虫结果:

3)运行视频
CSDN上传视频失败,故将第四次实验报告程序运行视频上传至B站,经由链接查看。
https://www.bilibili.com/video/BV1oh4y1x76V/?vd_source=4e6d401bdb8a49480c57fab57c53b2f5
4)源代码
1)爬取数据
import requests
import re
url='https://api.bilibili.com/x/v1/dm/list.so?oid=55869377'
#浏览器基本身份标识
#headers 请求头 字典数据类型
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
response=requests.get(url=url,headers=headers)#发送请求,并接收数据
response.encoding=response.apparent_encoding
print(response.text)
data_list=re.findall('<d p=".*?">(.*?)</d>',response.text)#.*?是正则表达式的元字符 可以匹配任意字符(除\n之外)
for index in data_list:
with open('弹幕.txt',mode='a',encoding='utf-8')as f:#mode保存方式,encoding编码
f.write(index)
f.write('\n')#换行
print(index)
2)制作词云图
import jieba
import wordcloud
import imageio#读取本地图片,修改词云图形
from imageio import imread
img = imageio.imread("xx.png")
#1.读取弹幕数据
f = open('弹幕.txt',encoding='utf-8')
text = f.read()
#2.分词
text_list = jieba.lcut(text)
print(text_list)
#列表转成字符串
text_str=''.join(text_list)
print(text_str)
#词云图配置
wc=wordcloud.WordCloud(
width=500,
height=500,
background_color='white',
mask=img,
font_path='msyh.ttc'#字体文件
)
wc.generate(text_str)
wc.to_file('词云4.png')

