


144
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级:2221
姓名: 夏永烨
学号:20222119
实验教师:王志强
实验日期:2023年5月21日
必修/选修: 公选课
1.实验内容**
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
本次结课大作业选择了编写爬虫的方向,用python程序实现从豆瓣电影网上爬取电影排行前100电影,这次是用了网络上的代码并且结合自己的更改来进行一个程序的爬取。
** 2. 实验过程及结果**
(1)首先是实验的准备工作

这是我爬虫过程中需要用到的一些库,我这个爬虫程序的书写必须需要这些库的支撑。
(2)正则表达式的书写
为什么要书写正则表达式?答:正则表达式,是用来我们筛选信息的。
下面是书写的所有正则表达式:

正则表达式的书写要结合网站本身,具体操作如下图:
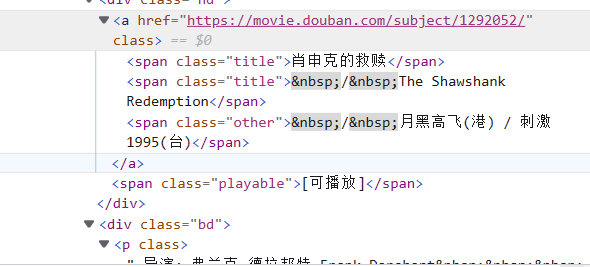


以上是在检查过程中网页的元素,其中第一个图中有电影详情链接,有电影标题,第三张图中有图片链接,我们可以通过这样的方式找到内容对应的元素,然后据此书写正则表达式筛选出我们需要的信息。其他我们需要的信息我们也可以通过同样的方法去寻找到,那么我们怎么才能找到信息对应的元素呢。
第二张图这是我找寻元素的过程,这个元素你通过鼠标的滑动你可以找到元素对应的信息,即信息与元素之间是有一个一一对应的关系的,我通过右侧的检查就可以找到我想要的元素了,这样我们就可以找到我们书写正则表达式需要的元素了。
(3)建立存储方式

这里是我的爬取网页的函数,baserul是我爬取网页的链接,我通过这个链接来爬取我想要的,下面获取信息,新建XLS的这些操作都是通过我数据库中的函数实现的,我只需要调用即可。
(4)向网页发起请求

这个askURL就是用来向网页发送请求用的,head在这里起到的作用就是伪装,我在这里装成一个浏览器,如果我要是不写的话,访问网站的时候会被认出来爬虫,显示错误,错误代码。
html=response那一行就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
(5)逐一解析数据
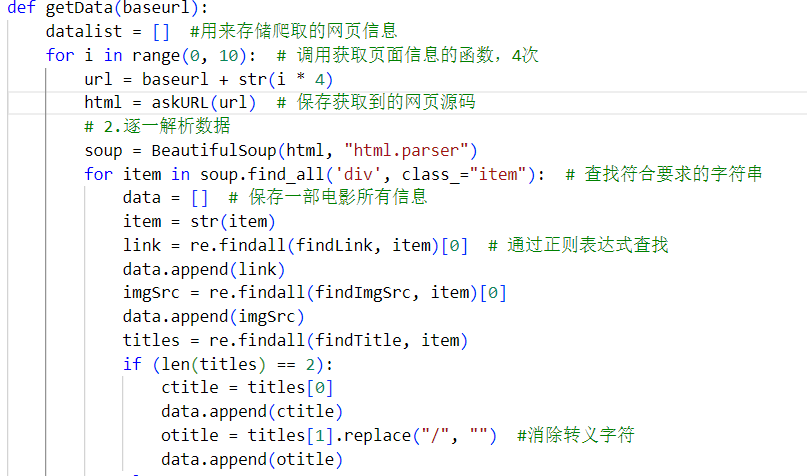
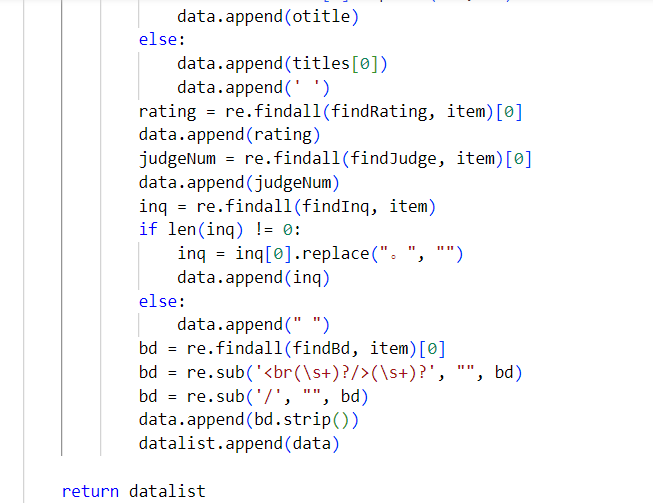
解析数据这里我们用到了 BeautifulSoup这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的正则表达式去匹配,正则表达式怎么匹配,如何去匹配我已经在上面讲过了,这里我就不再赘叙了。
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
(6)保存数据

保存数据可以选择保存到 xls 表, 需要(xlwt库支持)也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
保存到 xls 的主体方法是 saveData (上面的saveData方法是保存到sqlite数据库):

创建工作表,创列(会在当前目录下创建)然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件
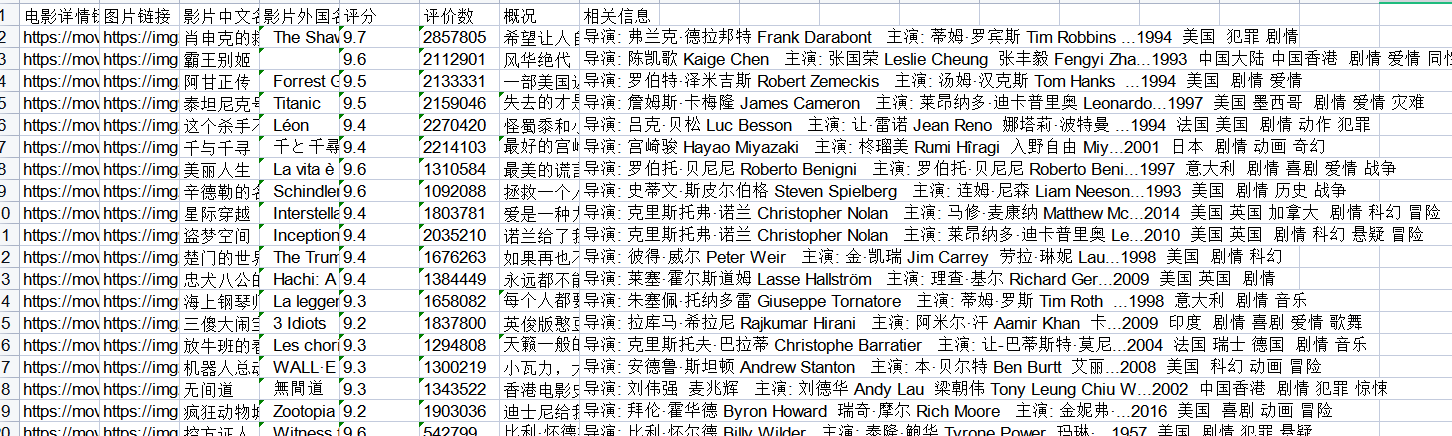

表格的开头和结尾就如图所示,这样我的一个爬虫就成功了。
将代码提交到gitee
** 3. 实验过程中遇到的问题和解决过程**
4.全课总结
Python选修课自一开始的学习思路与c语言便有所不同,c语言是面向过程的语言,而python这门语言这是一个面向对象的语言。Python给我的感觉有种不切实际的简单,简单是因为python不用书写许多程序的过程,用起来特别简单,而为什么不切实际呢,这是因为python接触的很多都是高大上的,就算你能直接用函数库,其书写也并不比c简单多少,甚至在书写方面上会更复杂,如果打个比喻,python程序书写有一个高屋建瓴的感觉。我们在一开始简单熟悉了循环语句、条件语句等语言基础,还有学会了debug和后,又接触到了处理列表、元组、集合和字典这些较新的概念,学习了正则表达式的书写,还有python中函数及参数传递的方法。面向对象的三大基本特征分别是封装、继承、多态,在其中我们学会了如何去创建类和属性;我们还学习了如何导入模块,怎样进行异常处理和文件操作,通过实验三还初步掌握了socket通讯的技能。总而言之,python的学习十分紧凑,内容丰富,但很显然这并不是python学习的尽头,python还有许多需要去学习的,这就需要我们在接下来的学习中继续努力。
5.结课感想与建议
Python其实是我一直向往学习的一门语言。进入大学后就一直听说python这门语言,而且很多最前沿的东西都是用python写的,所以当大一下学期可以选python的时候,我就不假思索地选择了python这门课,开始了我正统地学习python。
这学期的课程其实正如王老师所讲的那样,只是初步地将我们领进了门,之后的造化还得靠我们自己。Python它实现的多元性注定让我有着很多很多的地方可以更加深入的学习,这门课我相信也应该会成为我学习Python的启蒙课,这学期的时间让我对这门语言越来越感兴趣,在课余时间,我还通过我自己的学习学习了一些有关深度学习的内容,深入了解了一下卷积层和卷积运算,更深入的了解了一些python的前沿东西,我还学长一起通过网上的代码完成了一个暴力检测的小制作,那次制作让我更深的认识了python的应用扩展,原来python的技术可以这么强大,这更加激发了我对python课程的兴趣,所以我在暑假中打算自己自学更多的python内容。还是那句话,师傅领进门,修行在个人,python的学习还是要我们自己更多的努力。
王老师讲课真的很有意思!!!以兴趣为导向的Python课我也真的好喜欢!!以后其实可以考虑更多讲一些python的趣味应用,我觉得应该更能激发大家的兴趣的!!不过就是课程内容安排有时有点太紧,比如那个数据库,一次晚课就讲完了,真的太快了。还有就是python课程安排我认为是不太得当的,一周一次,如果中间没有自己的复习,很容易导致课程的遗忘,如果python可以一周上两次课就好了,这样学习python就可以更加深刻了!还有,python课程还是需要布置作业,作业能够有效帮我们复习知识,我们自己肯定是不想做作业的,但是不得不承认,作业确实对我们学习大有裨益,希望老师能够下届学生布置一些作业。
希望以后还能有机会选到王老师的课~
代码及视频
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")

