


19,464
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
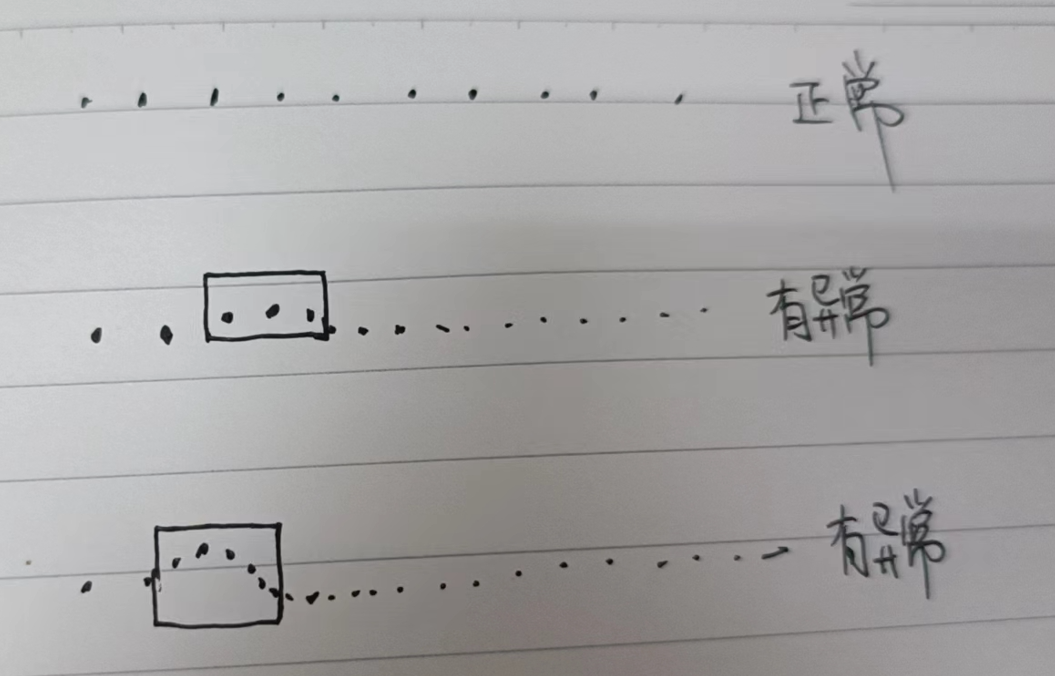
首先,观察这排点,看看哪些点明显与其他点不同,比如距离、坐标、大小等方面。这些点可能是异常点。
然后,可以使用一些统计方法来识别异常点。比如,可以使用箱线图(Box Plot)来可视化数据的分布情况。箱线图可以显示数据的五数概括,即最小值、第一四分位数、中位数、第三四分位数和最大值。如果某个点明显偏离了中位数,那么它可能是一个异常点。
另外,还可以使用一些聚类算法来识别异常点。比如,可以使用K-means聚类算法将这排点分成K个簇。然后,根据每个簇中的点与其他点的距离来识别异常点。如果某个点距离它的簇中心很远,或者它不在任何簇中,那么它可能是一个异常点。

