





1,470
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
北京时间5月11日凌晨,谷歌GoogleI/O 2023在加利福尼亚州山海岸线圆形剧场如期举办。整场大会,大会3个小时左右,无论是最开始的智能邮件写作,还是后面介绍的沉浸式地图、Magic Compose (魔法撰写)、Cinematic Wallpapers(电影壁纸)和Generative AI Wallpapers(生成式AI壁纸)等等。都和AI相关,各种各样的产品新功能都搭上了机器学习的影子。谷歌这次因ChatGpt4.0的推出可能真的“焦虑”了,整场发布会都离不开AI的字眼,处处弥漫着AI应用的氛围,总的来说,这次大会的市场反馈效果非常不错,因此谷歌的股价也迎来了意料之中的大涨!因此无论是企业或个人,都必须去了解AI了,每个开发者都应该去熟悉和AI相关的底层框架。
下面我们一起来聊聊,这些AI产品的源头网红框架TensorFlow。正如本次大会所说“Making AI helpful for everyone”

TensorFlow是一个人人都触手可及的完全开源的人工智能框架!
TensorFlow 是一个大规模机器学习的开源框架,提供了多种深度神经网络的支持。
不仅 Google 在自己的产品线使用 TensorFlow,包括联想、小米、新浪网、京东、360、网易等众多知名企业也都将 TensorFlow 用于其产品和研发,为其用户带来更智能和便捷的体验。TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。最初由Google大脑小组的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究。总的来说TensorFlow主要用来数值计算,如ChatGPT就是大数据模型,后面就离不开大规模的数据计算,因此你如果想自己去玩下ChatGpt或者本次谷歌大会提到的PaLM 2大模型,必须去深入了解下TensorFlow。

在本次大会中,提到谷歌研发人员通过使用大量数学和科学数据集对PaLM 2进行训练。相比去年的PaLM模型,PaLM 2在多语言处理、推理以及逻辑等能力上有了很大程度的提升。在此外在算法的优化下,PaLM 2在体积上较前代要小且计算效率也更高。其中支持PaLM 2大量数学和科学数据集训练的底层框架,正是TensorFlow。用于支持谷歌的25项功能和产品包括今年谷歌刚推出不久的聊天机器人Bard,以及用于工作生产力的谷歌文档、幻灯片和工作表等。在PaLM 2的加持下,谷歌的Bard聊天机器人实现了显著的进化,答案生成的内容也更加地多元化。
比如在询问Bard后,其除了会提供文字答案之外,还能提供包括图片、视频、外部链接等多元化的信息,根据第一次提问返回的信息,你还可以进一步进行交互查询更多的信息,知道你得到最需要的答案。甚至你也可以将这些问题答案一键导出到Gmail、谷歌文档、表格之中,Bard还可以自动帮你给图片、文档等做加标注,切实回归到AI应用初心,进一步帮助提高人类工作的效率。
如果,你没有用过谷歌的相关产品,你相信你一定用过TensorFlow功能,比如抖音的AI绘画、AI修图、AI游戏、AI作曲等。
对于AI的热爱者、研究者来说,可通过TensorFlow可视化工具tensorboard来接入。具体安装在这不再阐述,我们可以通过看几个简单的案例来了解TensorFlow怎么的应用,如编写一个模型用于 TensorBoard callback 的快速示例。
使用 TensorFlow 创建一个简单的模型,并在 MNIST 数据集上对其进行训练。
import tensorflow as tf
# Load and normalize MNIST data
mnist_data = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist_data.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
# Define the model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
编译模型,创建一个回调并在调用 fit 方法时使用。
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")
在模型上调用 fit 方法时将回调作为参数传入。 会看到在工作目录中创建了 logs 文件夹,并将其作为参数传递给 log_dir。 然后调用 fit 并将其作为回调传入。
model.fit(X_train, y_train, epochs=5, callbacks=[tf_callback])
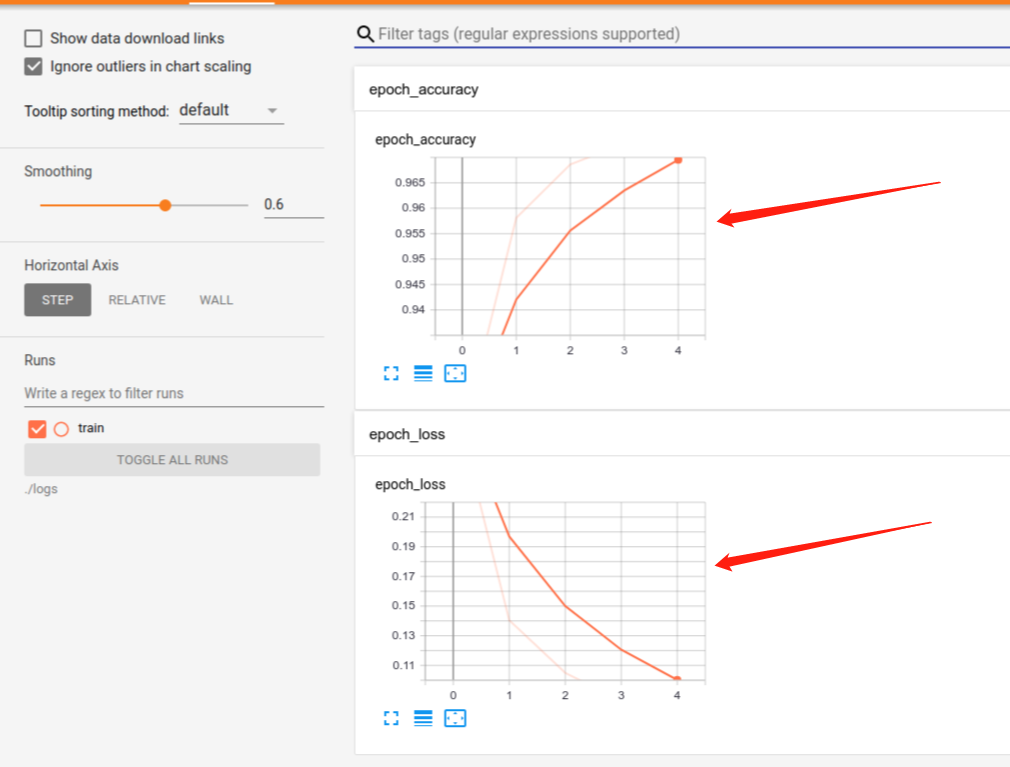
然后我们就可以查看对应效果了, 如下图所示我们看到了一个两个不同的图表。 第一个显示了模型在每个epoch的准确性。 第二个显示的损失。
当然TensorFlow也提供了很多封装好的API接口,如Keras、Estimator等。
AI的浪潮已经漫过了我们的膝盖,在这场AI浪潮中,我们每个人都会在生活或者工作中受到冲击。与其我们担心,AI会抢走我们的工作,还不如多花点时间去了解AI究竟是个什么东西,到底是天使还是恶魔,我们都能一窥究竟。AI的迅猛发展,离不开机器学习和深度学习的发展,机器学习和深度学习发展离不开TensorFlow的发展和贡献,正如谷歌I/O所说的“Making AI helpful for everyone”。我们也应当去拥抱AI,拥抱AI背后的力量,在你不知道怎么去了解AI时,我们不妨从学习TensorFlow开始!



