535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享@
人体姿态估计是计算机视觉中一个基础任务,从名字的上理解就是对人姿态的估计,实际上是对人体多个关键点(如肩部、手肘、脚踝等)的位置估计。一般分为四个任务:单人姿态估计、多人姿态估计、人体姿态跟踪、3D人体姿态估计。
输入:图像
输出:所有关键点的像素坐标/3D坐标/人体模型
过程:
先检测人,再检测关键点
把一个检测问题建模成回归问题
即将图像作为输入,回归图象中人体图像的坐标
然后将人体图象作为输入,回归人体关键点坐标作为输出
优点:符合人类对人体关键点识别的认知
缺点:推理速度与图像中的人数成正比
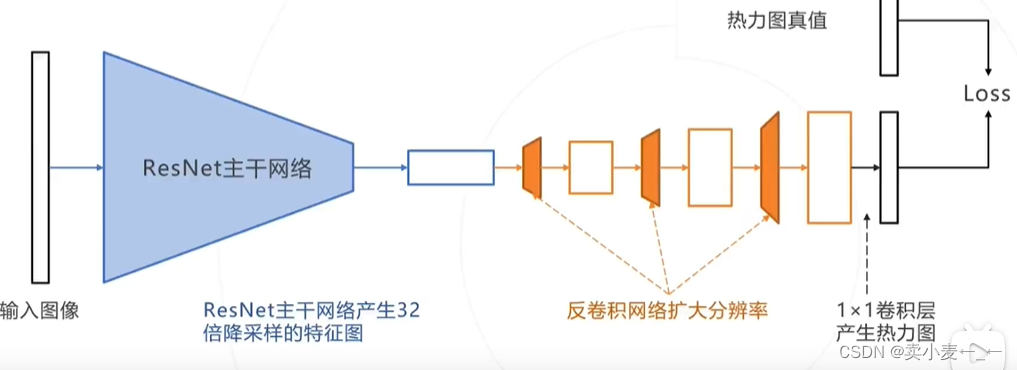
使用深度网络作为主干网络
原文使用Alexnet作为主干的分类网络,在最后加一个回归头,一次性回归所有关键点坐标
现在也可以使用resnet作为主干网络
优点:回归模型理论上可以达到无限精度,而且无需维持高分辨率
缺点:达到高精度的困难程度高于热力图
这个地方的数学公式较多,理解的比较吃力
原来模型回归关键点的坐标,RLE回归的是关键点位置的概率分布
两种降低建模分布难度的方法
1.重参数设计
2.残差似然函数
热力图是显示的是人体关键的坐标概率分布,用热力学的颜色深浅代表该关键点的图像上的概率大小分布
类似Unet的结构,将各个卷积层的输入加到输出结果上,提高对不同尺寸图像的识别精度
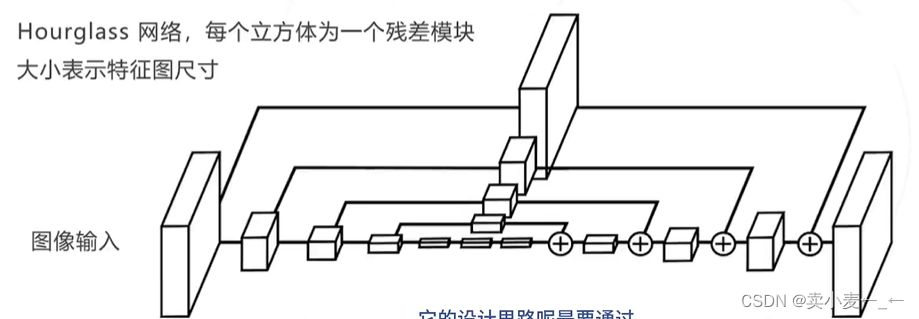
encoder-decoder的结构,使用resnet作为主要encoder网络主干
输入一个高分辨率图像,对图像进行多尺寸的卷积,最后在对不同的卷积结果进行特征融合,最后根据不同的任务选择不同的任务头
1、只取第一层作为人体姿态估计
2、将四层输出做上采样再做合并,用于语义分割
3、将四层输出做上采样再做合并,然后进行多分辨率下采样,用于物体检测
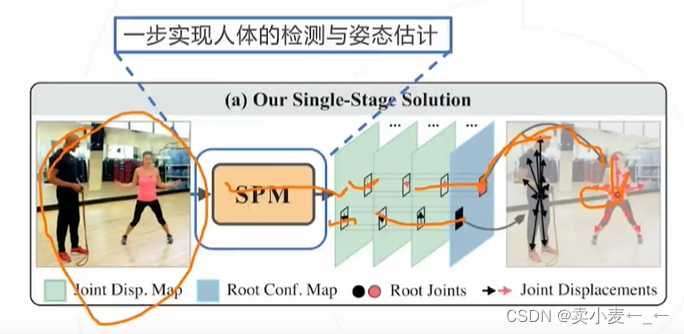
同时预测关键点和肢体方向,然后利用辅助信息,四肢走向和关键点位置聚类,最后将输入同一人的关键点组合
输入图像,输出以人体为中心的,各关键点的向量图
优点:在计算去的速度优势,而且检测精度不逊色于二阶段方法
人体姿态与物体检测有相似的地方,那么将注意力机制的q放到关键点上,便可通过注意力机制的query去学习关键点的信息,最后回归到关键点坐标上
二阶段方法:先在图像上裁剪出单人的图像,在回归关键点坐标
单阶段方法:直接在网络中裁剪出单人特征(通过下采样得到不同尺寸的特征图,在进行特征合并得到单人特征),然后回归到关键点坐标
为每个关键点设置一个可学习的token,然后把视觉token和关键点的token拼接在一起送入transformer的网络中,最后得到各个关键点的热力图
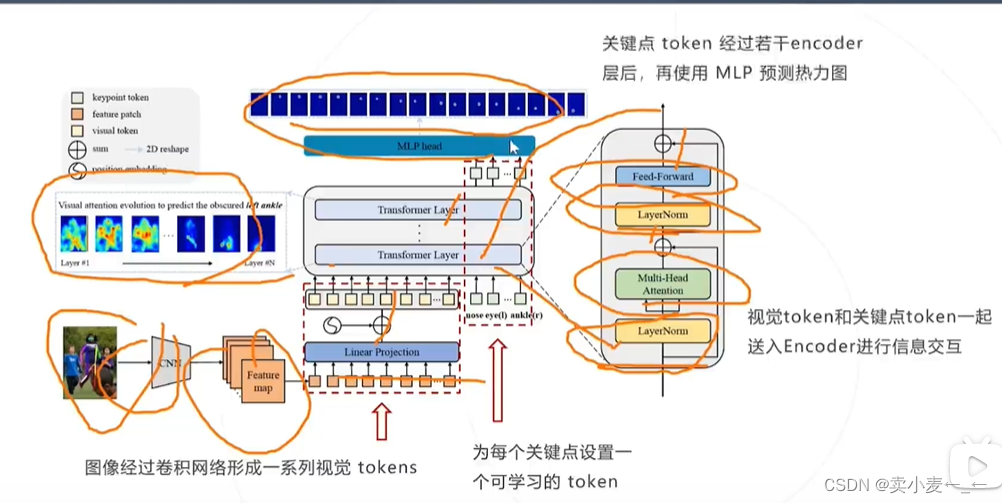
通过给定的图像得到人体关键点在三维空间的坐标,在三维空间中还原人体的姿态
模型为hourglass级联,每级预测关键点的3D热力图
直接用关键点的2D坐标输入到simple baseline来预测关键点的3D坐标
二阶段方法:(1)基于单帧图像预测关键点坐标,在把多帧2D关键点拼在一起作为输入预测3D关键点坐标
使用HRNet产生不同视觉的特征图,根据相机参数将特征图整合到一个整体中,再将其作为输入到3D卷积网络中,预测每个人关键点的3D坐标
将人体表面分成24个部分,并将每个部分参数化至256x256的uv平面
网络结构:
MaskRCNN+densereg=densepose-rcnn
先通过maskrcnn预测前景和背景
再在前景和背景上进行精确的关键点预测
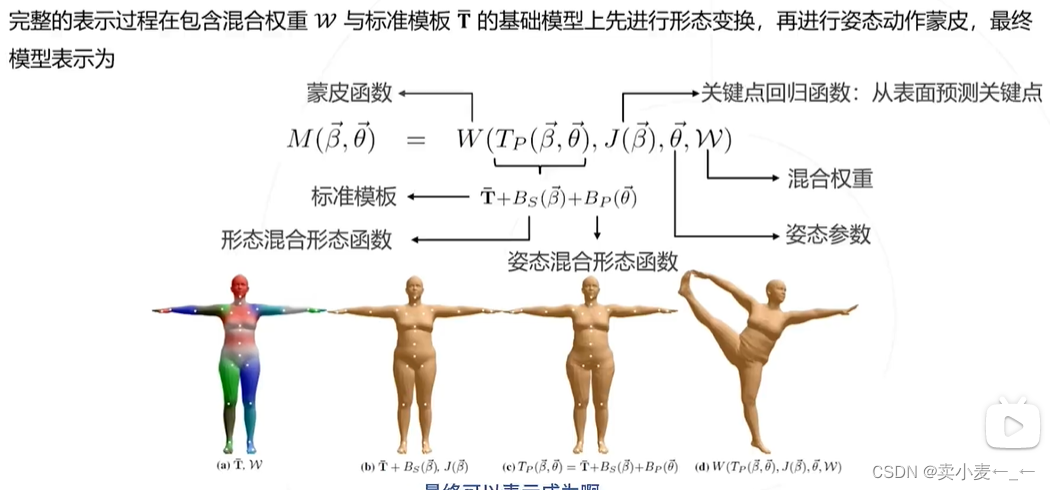
smpl是针对人体结构参数化模型,将人体建模成n=6890个订点和23个关键节点的表面网格,并设计了形态参数和姿态参数来控制人体的变化
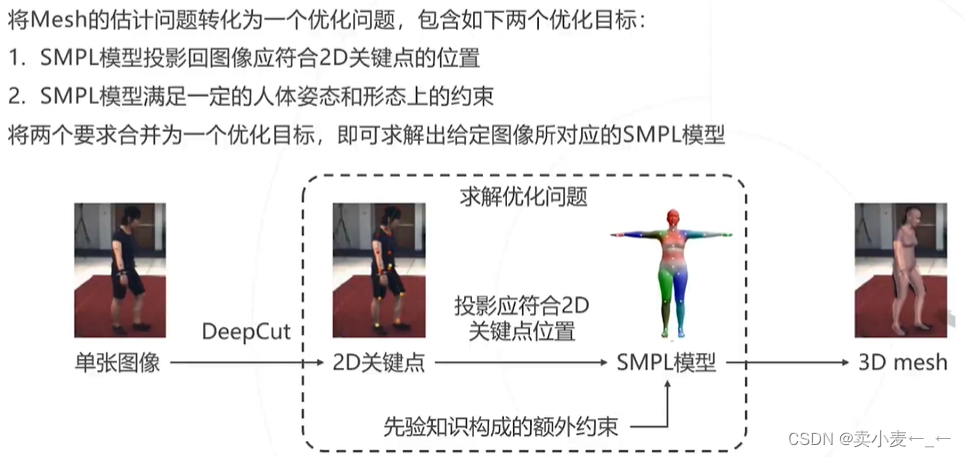
对2D图像预测关键点信息,将关键点信息输入到smpl模型中,并且模型满足人体姿态约束和形态约束,然后求解优化得出2D图像的3D mesh
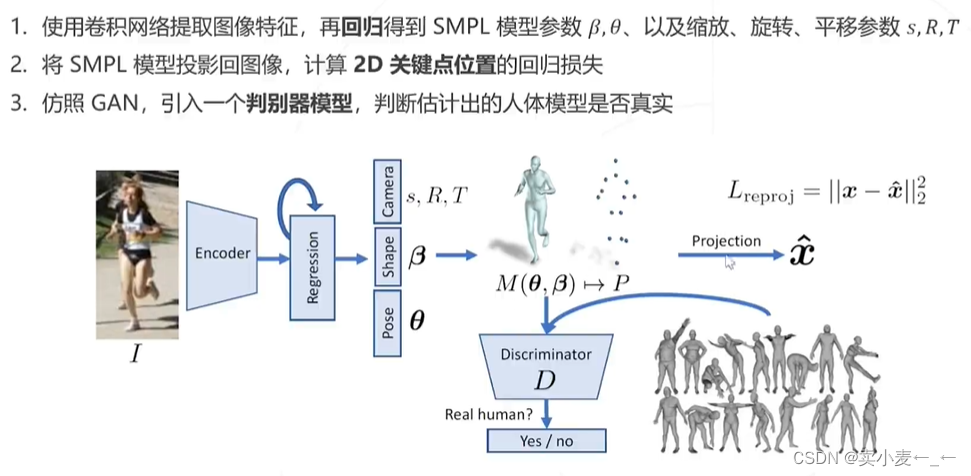
基于深度学习,直接从2D图像去估计SMPL模型的参数,从而生成3D mesh
这个方法的训练只能使用2D图像的标注
算法:使用卷积网络去提取图像特征,在回归到smpl模型参数,将模型参数投影到图像,计算2d图像的关键点回归坐标的损失,然后像gan那样引入一个判别器,去判断smpl模型的人体是否真实(即判断smpl模型是否符合形态约束和姿态约束)