


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
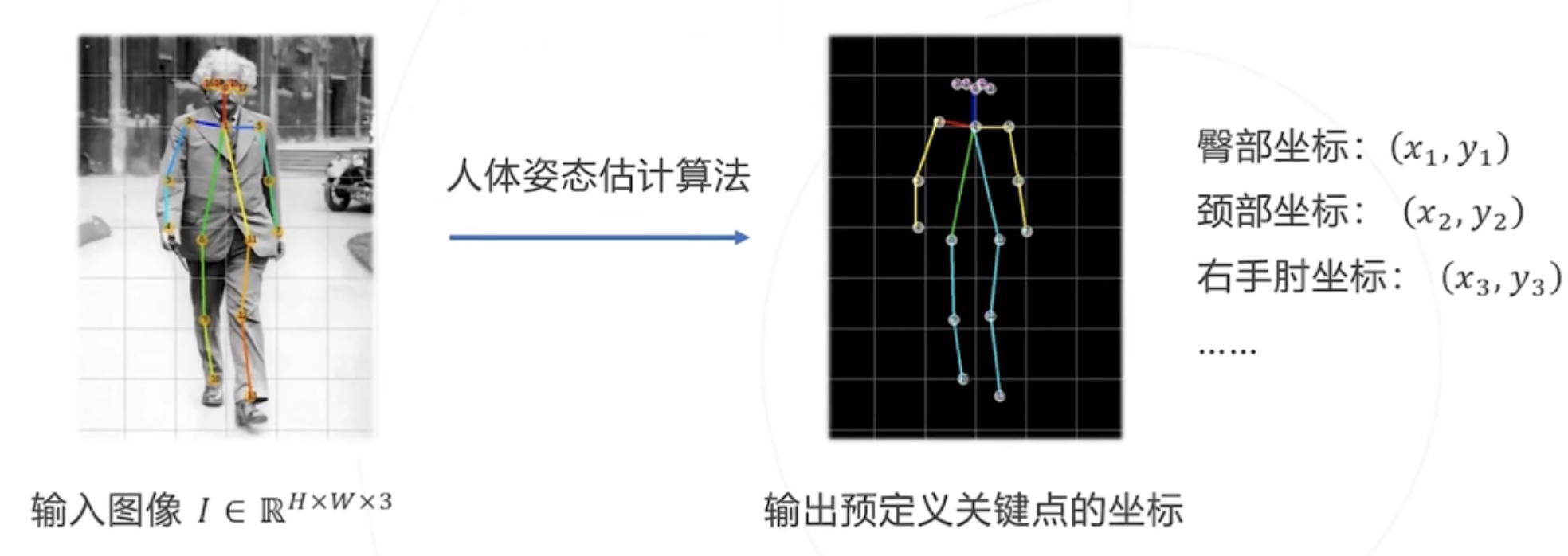
分享从给定的图像中识别人脸, 手部,身体等关键点.
Input: 图像I
Output: 所有关键点的像素坐标 (x1,y1)..(x_J,y_J) , J 为关键点的总数, 取决于具体的关键点模型
关键点常是变化的
下游任务:
行为识别
CG,动画
人机交互
动物行为分析
1. 基于回归
将关键点检测问题建模为一个回归问题, 让模型直接回归关键点的坐标, 即 (x1,y1,..,x_J,y_J)=f(I)
例: 使用CNNs, 输入图像, 最后一层通过线性回归预测关键点坐标
问题: 深度模型直接回归坐标有困难, 精度并非最优.(历史经验.
2. 基于热力图(Heatmap based)
并不直接回归关键点的坐标,而是**预测关键点位于每个位置的概率**, 即 H_1..J = f(I)
H_j(x_j,y_j)=1 表示关键点 j 位于 (x_j,y_j) 的概率为1
H: 热力图, 尺寸与原图I 相同or 按比例缩小
H_j 的制作, 使用高斯核
从第j个关键点的热力图H_j(x,y)中还原关键点(x_j,y_j)的位置: 取数学期望, 高斯重心, 可以端到端求导
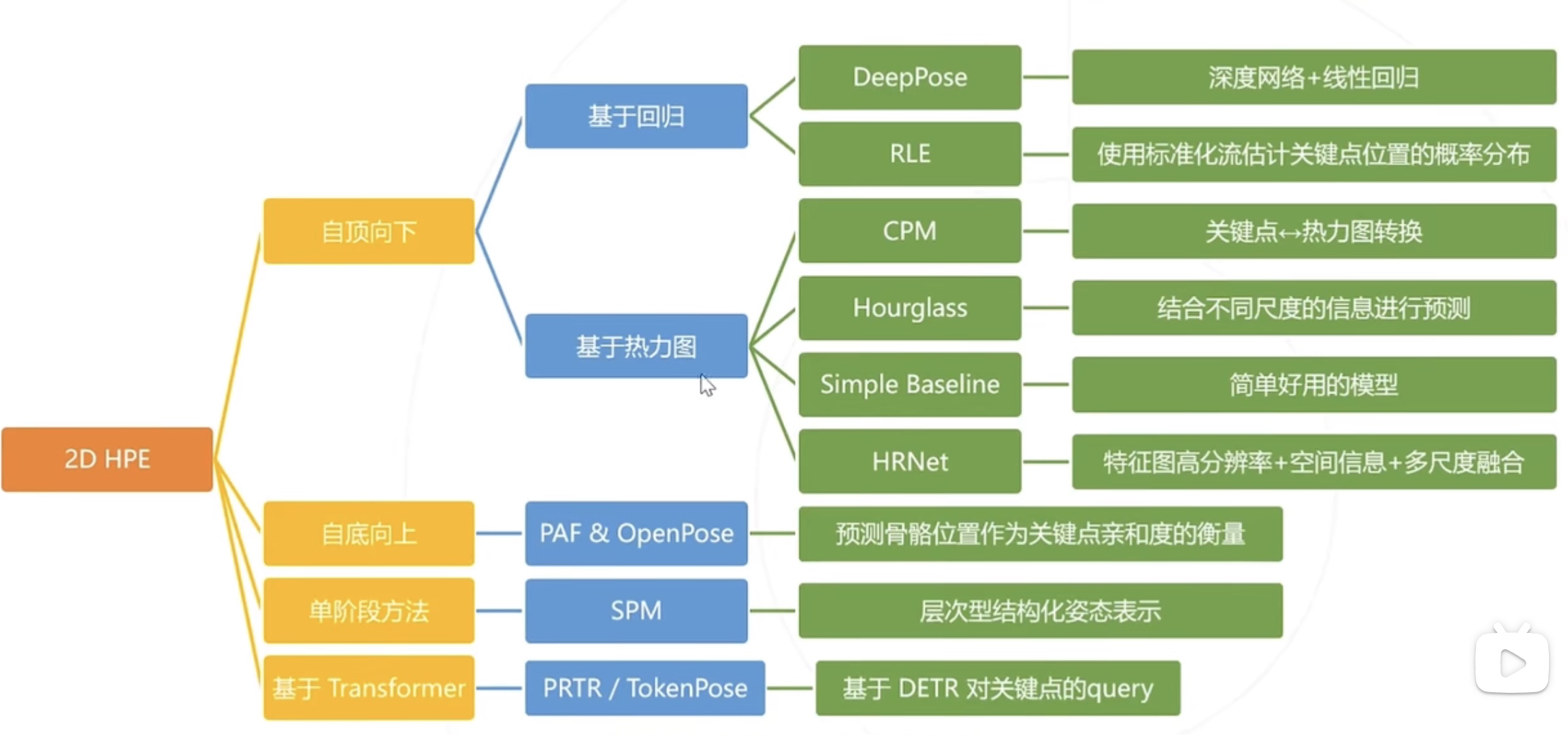
1. 基于回归 AlexNet backbone, 多级级联
- 优势: 理论上无限精度, Heatmap 受限于特征图空间分辨率; 无需维持高分辨率特征图, 计算和存储成本低
- 劣势: Img-keypoint map 高度非线性 精度有待..
- Residual Log-likelihood Estimation
2. 基于热力图的自顶向下
- 例子: Hourglass短模块级联(2016), HRNet(2018)
Part Affinity Fields & OpenPose (2016)
基本思路: 基于图像同时预测关节位置和四肢走向, 利用肢体走向辅助关键点的聚类, 即如果某两个关键点由某段肢体相连, 则这两个关键点属于同一人
类似Convolutional Pose Machine的级联结构, 同时预测所有人的所有关键点位置和肢体方向
基于亲和度匹配关键点 K部图最优匹配 聚类 拆分开
SPM (2019) 首次实现单阶段姿态估计, 速度优势, 且2D和3D
为了统一人体实例和身体关节的位置信息, SPR 引入一个辅助关节, 即根关节表示人员实例位置, 它是唯一标识关节;
弊端是出现较大姿势变形时, 可能涉及身体关节和根关节之间的远位置位移, 给从图像表示映射到矢量域的位移估计带来困难
Hierarchical SPR
根据自由度和变形程度将根关节和身体关节划分四个层次:
1. 第一级根关节
2. 第二级颈肩臀
3. 第三级头肘膝
4. 第四级手腕 脚踝
以级联的Hourglass backbone, 利于置信回归分支来回归根关节的热力图, 并额外延伸一个位移回归分支用来估计身体关节位移图
Loss 分为两部分, 根关节置信度L1 loss, 位移图的L2 loss
人体姿态估计与物体检测有一定相似性, 都涉及对图像内容的定位
在 DETR 中 query 通过注意力机制组件聚焦到特定物体上, 姿态估计可以模仿 DETR: 让query逐渐聚焦到特定人体关键点上
PRTR
2021 Pose recognition with cascade transforms
PRTR 两阶段算法:
人体检测阶段: 使用 DETR 检测出图中的不同的人
关键点检测阶段: 同样使用 DETR 结构, 不同的是query 学习关键点信息, 最终回归到关键点位置
PRTR 单阶段算法:
人体检测和关键点检测 共用一个图像特征网络
设计了 Spatial Transformer Network(STN) 模块, 从完整特征图中裁剪出单人对应的图像特征, 用于后续关键点检测
TokenPose:
2021
将视觉 token 和关键点 token 一起送入Encoder 可以同时从图像中学习外观视觉表现和关键点间的约束关系
分类模型 ViT 也使用类似方法, 将一个分类 token 和visual token 一起做自注意力
通过给定给的图像预测人体关键点在三维空间中的坐标, 可以在三维空间中还原人体姿态
相对坐标: 关键点相对于骨盆点(pelvis)的坐标
难点:
3D 人体姿态估计要求从 2D 图像(或视频)恢复 3D 信息
3D信息从何而来?
Coarse-to-Fine Volumetric Prediction
2017
Volumetric 三维热力图
模型为Hourglass 级联, 每级直接预测关键点的3D热力图
对于每个关节点, 预测目标为 64x64xd 的3d 热力图, d 取值为深度方向的分辨率, 逐级增加, 每级取值为 {1,2,4,8,16,32,64}
获得更多的帧间信息辅助推断
VideoPose3D
2018
基于单帧图像预测2D关键点, 再基于多帧 2D 关键点结果预测 3D关键点
利用多视角拍摄的图片
来预测和还原3D信息
VoxelPose
2020
1. Percentage of Correct Part(PCP) 肢体的检出率
2. Percentage of Detected Joints(PDJ) 关节点的位置精度
3. Percentage of Correct Key-points(PCK) 关键点的检测精度
4. Object Keypoint Similarity (OKS) based mAP 关键点相似度
将人体表面分为24个部分, 并将每部分参数化至同样大小(256x256)的UV平面, 标注个身体部分的区域后, 在每个部分等距采样至多14个点, 并对应到3D人体上, 用于训练
网络结构
基本结构: Mask-RNN + DenseReg = DensePose-RCNN
先进行前景与背景预测, 再对人体每一部分精确回归
改进设计
与辅助任务(关键点, Mask)的交叉级联
身体表面网格 Body Mesh
由多边形(通常为三角形or四边形) 网格组成构建的人体表面模型, 通常由具有3D位置表表的顶点(Vertices)来定义
混合蒙皮技术 Blend Skinning
SMPL
形态参数
姿态参数
混合线性蒙皮
SMPLify 算法
人体姿态约束
人体形态约束
HMR算法


