535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享人体姿态估计的介绍与应用
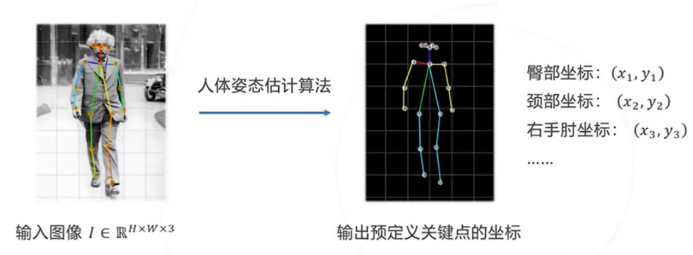
人体姿态估计是指从给定的图像中识别人脸、手部、身体等关键点,输入图像I,输出所有关键点的像素坐标(x1,y1),(x2,y2),(xj,yj),其中j为关键点的总数,j取决于具体的关键点模型,人脸有68个关键点,手势是21个关键点,人体是18个关键点。而姿势形态的多变性,关键点的坐标也会有各种不同的组合,这也是人体姿态估计模式识别的难点所在。
3D姿态估计,预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态,更进一步,我们可以构造人体参数化模型从图像或者视频中恢复出运动的3D人体模型;对于下游任务,姿态估计也有着广泛的应用,可以用于研究行为理解、PoseC3D基于人体姿态识别行为动作、应用于CG动画、进行手势人机交互、动物行为识别分析……
2D姿态估计
2D人体姿态估计指在图像上定位人体关键点(通常是关节)的坐标。而关键点的检测有两种基本思想:基于回归和基于热力图。
基于回归
对关键点的检测可以建模成一个回归问题,即输入图片后让模型直接回归关键点坐标,即(x1,y1,…,xj,yj)= fθ(I)例如使用卷积神经网络,以图象作为输入,最后一层通过线性回归预测关键点的坐标,同时也存在问题,深度模型直接回归坐标的精度不高。
基于热力图
并不直接回归关键点的坐标。而是预测关键点位于每个位置的概率,即H1…j=fθ(I),Hj(xj,yj)=1表示关键点j位于((xj,yj)的概率为1,H称为热力图,尺寸与原图I相同或按比例缩小
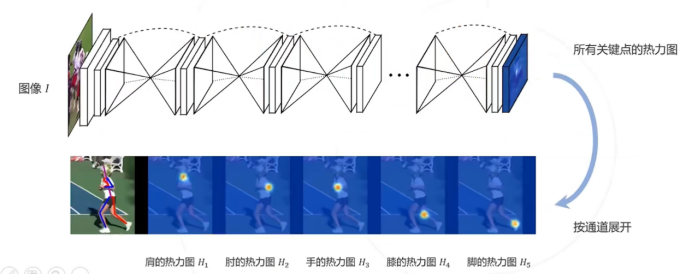
模型预测热力图比直接回归坐标相对容易,因为它更符合神经网络的结构,而且模型精度相对更高,因此主流算法更多基于热力图,但预测热力图的计算消耗大于直接回归,因为它在后端需要维护一个相对比较大的数据。
到这里,主讲人讲到如何从数据标注生成热力图,每一个关键点对应着一个2D热力图,是根据关键点的坐标,通过高斯概率函数计算(高斯过程),得到关键点对应热力图的高斯核,得到的热力图就相当于一个概率图(这个步骤我并没有十分理解,还得继续学习)。然后将原图预测出来的热力图与关键点标注得到的真值热力图进行逐点比对计算损失,便可使用热力图训练模型。
而如何从热力图中还原出关键点的位置,这里也介绍了两种方法,一种是朴素方法:求热力图最大值位置,此方法要思考两个问题如果同时面对两个点时,取最大值是否是一个鲁棒的方法?取最大值方法得到的结果是否是高斯的?除了取最大值,还有一个方法是取数学期望,相当于取了高斯的一个重心点,使得结果更具鲁棒性。课程中提到这个过程是可以端到端去优化的,热力图可以变成坐标,而坐标可以直接求导的,它便可以guide热力图(不懂555)。
自顶向下的方法,我们先给定一张图片,然后使用目标检测算法检测每个人体,再在此基础上做单肢体估计,基于单人图像估计每个人的姿态。

但自顶向下的方法面临着几个问题,首先,因为要先要目标检测出每个个体,所以姿态估计整体精度受限于检测器的精度;再者,此方法的速度和计算量与人数成正比。
自底向上方法,先使用关键点模型检测出所有人体的关键点,再基于位置关系或其它辅助信息将关键点聚类组合成不同的人。此方法的优点是推理速度与人数无关。

基于回归的自顶向下方法
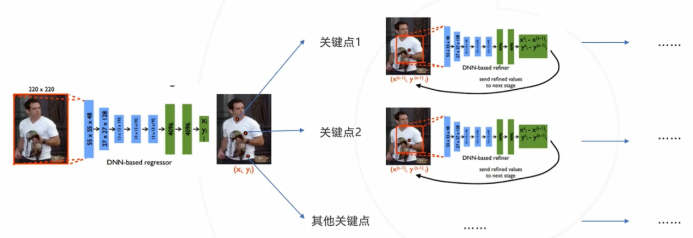
DeepPose(2014)
以分类网络为基础,将最后一层分类改为回归,一次性预测所有 j 个关键点的坐标,通过最小化平方误差训练优化网络。原论文使用了AlexNet主干+回归头,第一级以全身图像为输入,预测所有关键点坐标,位置精度较低,得到关键点后,接着以每个预测点为中心,裁剪局部图像送入第二级网络,再次回归该店坐标,提升精度;整个过程可以通过多级级联提高精度。
回归方法的优势:
劣势:
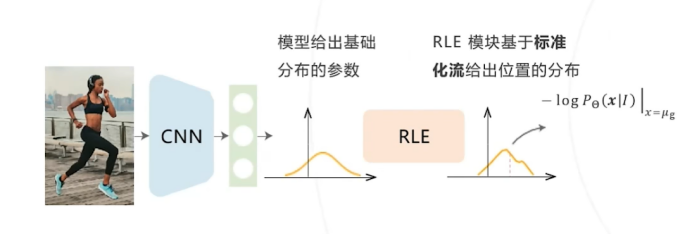
Residual Log-likelihood Estimation(RLE)(2021)
核心思路:对关键点的位置进行更准确的概率建模,从而提高位置预测的精度.模型给出基础分布的参数,RLE模块基于标准化流给出位置的分布
经典回归范式:模型预测关键点位置,与真值计算误差作为损失,实质隐含了高斯分布的假设,但不一定符合数据的实际分布,如手肘等特殊部位的分布值
RLE的范式:模型给出关键点的概率分布,真值带入该分布计算出似然,通过最大似然拟合最优的分布
(背景知识:基于二范数误差的回归和基于高斯似然的最大似估计是等价的,(此处略过我不理解的一些公式转换5555),RLE的思路就是将简单的高斯分布替换为一个可学习的、表达能力更强的、更好拟合关键点位置的实际分布。
标准化流Normalizig Flow,是一种生成建模方法,通过一系列可学习的可逆的映射,将标准分布的随机变量映射成复杂分布的随机变量,可用于建模复杂的概率分布)
RLE的目标是建模关键点位置的概率分布,即给定图像I,给出每个关键点x的位置分布Pθ(x|I)
可以基于标准化流构建该分布,但RLE算法还引入了两个技巧以降低模型拟合真实分布的难度:一是重参数化;二是残差似然函数