


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享北京超算云 30 区
显卡 3090 24G
module load anaconda/2021.05
module load cuda/11.1
module load gcc/7.3
conda create --name mmpose python=3.8 -y
source activate mmpose
进入官网:Pytorch 2.0 稳定发行版
选择推荐的下载命令就好:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
这个工具可以帮助构建 openmmlab 的算法库
pip install -U openmim

mim install mmengine
mim install 'mmcv==2.0.0rc3'
mim install "mmdet>=3.0.0rc6"

pip install opencv-python pillow matplotlib seaborn tqdm pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple

git clone https://github.com/open-mmlab/mmpose.git -b tutorial2023
由于超算云中访问 github 较慢,所以换个代理加速 clone 速度
git clone https://ghproxy.com/https://github.com/open-mmlab/mmpose.git -b tutorial2023
cd mmpose/
mim install -e .

git clone https://ghproxy.com/https://github.com/open-mmlab/mmdetection.git -b 3.x
cd mmdetection/
pip install -v -e .

耳朵穴位关键点检测数据集,MS COCO格式,划分好了训练集和测试集,并写好了样例config配置文件
标注人:张子豪、田文博
google云盘下载
夸克网盘下载
百度网盘下载 提取码: 741p
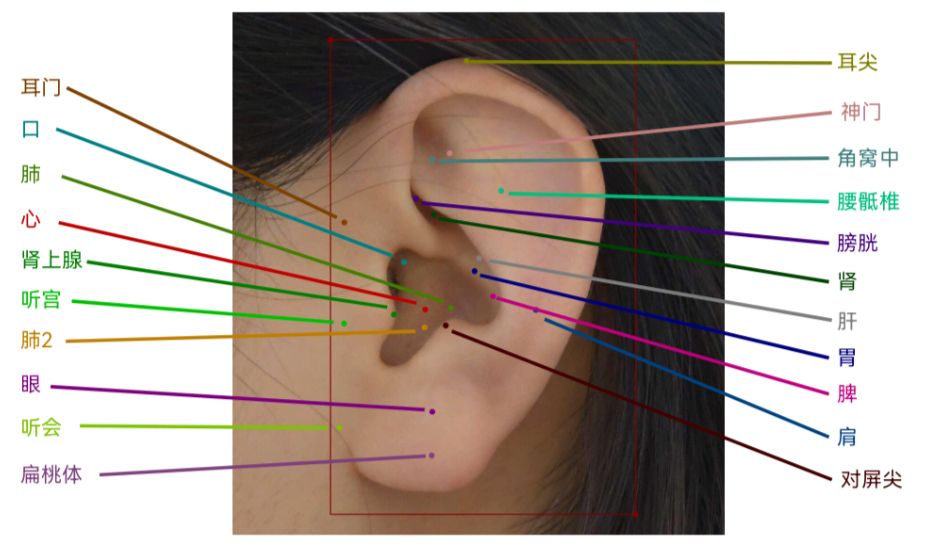
根据中医的“倒置胎儿”学说,耳朵的穴位反映了人体全身脏器的健康,耳穴按摩可以缓解失眠多梦、内分泌失调等疾病。耳朵面积较小,但穴位密集,涉及耳舟、耳轮、三角窝、耳甲艇、对耳轮等三维轮廓,普通人难以精准定位耳朵穴位。
1.Labelme标注关键点检测数据集
2.划分训练集和测试集
3.Labelme标注转MS COCO格式
4.使用MMDetection算法库,训练RTMDet耳朵目标检测算法,提交测试集评估指标
5.使用MMPose算法库,训练RTMPose耳朵关键点检测算法,提交测试集评估指标
6.用自己耳朵的图像预测,将预测结果保存
7.用自己耳朵的视频预测,将预测结果保存
实际上,本数据集已经把1、2、3完成,所以我们主要从4、5、6、7四个任务。
wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth -P checkpoint/rtmdet
wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e.pth -P checkpoint/rtmdet
# 数据集类型及路径
dataset_type = 'CocoDataset'
data_root = 'data/Ear210_Dataset_coco/'
metainfo = {'classes': ('ear',)}
NUM_CLASSES = len(metainfo['classes'])
# 预训练模型权重
load_from = 'checkpoint/rtmdet/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth'
# 训练超参数
MAX_EPOCHS = 70
TRAIN_BATCH_SIZE = 64
VAL_BATCH_SIZE = 32
stage2_num_epochs = 7
base_lr = 0.008
VAL_INTERVAL = 5 # 每隔多少轮评估保存一次模型权重
# default 设置
default_scope = 'mmdet'
default_hooks = dict(
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=1),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(type='CheckpointHook', interval=10, max_keep_ckpts=2, save_best='coco/bbox_mAP'), # auto coco/bbox_mAP_50 coco/bbox_mAP_75 coco/bbox_mAP_s
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='DetVisualizationHook'))
env_cfg = dict(
cudnn_benchmark=False,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='DetLocalVisualizer',
vis_backends=[dict(type='LocalVisBackend')],
name='visualizer')
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
log_level = 'INFO'
load_from = None
resume = False
train_cfg = dict(
type='EpochBasedTrainLoop',
max_epochs=MAX_EPOCHS,
val_interval=VAL_INTERVAL,
dynamic_intervals=[(MAX_EPOCHS - stage2_num_epochs, 1)])
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
param_scheduler = [
dict(
type='LinearLR', start_factor=1e-05, by_epoch=False, begin=0,
end=1000),
dict(
type='CosineAnnealingLR',
eta_min=0.0002,
begin=150,
end=300,
T_max=150,
by_epoch=True,
convert_to_iter_based=True)
]
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
auto_scale_lr = dict(enable=False, base_batch_size=16)
# DataLoader
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='CachedMosaic',
img_scale=(640, 640),
pad_val=114.0,
max_cached_images=20,
random_pop=False),
dict(
type='RandomResize',
scale=(1280, 1280),
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=(640, 640)),
dict(type='YOLOXHSVRandomAug'),
dict(type='RandomFlip', prob=0.5),
dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
dict(
type='CachedMixUp',
img_scale=(640, 640),
ratio_range=(1.0, 1.0),
max_cached_images=10,
random_pop=False,
pad_val=(114, 114, 114),
prob=0.5),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(type='Resize', scale=(640, 640), keep_ratio=True),
dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=TRAIN_BATCH_SIZE,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=None,
dataset=dict(
type='CocoDataset',
data_root=data_root,
metainfo=metainfo,
ann_file='train_coco.json',
data_prefix=dict(img='images/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=None),
pin_memory=True)
val_dataloader = dict(
batch_size=VAL_BATCH_SIZE,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='CocoDataset',
data_root=data_root,
metainfo=metainfo,
ann_file='val_coco.json',
data_prefix=dict(img='images/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=None))
test_dataloader = val_dataloader
# Evaluater
val_evaluator = dict(
type='CocoMetric',
ann_file=data_root+'val_coco.json',
metric=['bbox'],
format_only=False,
backend_args=None,
proposal_nums=(100, 1, 10))
test_evaluator = val_evaluator
# tta
tta_model = dict(
type='DetTTAModel',
tta_cfg=dict(nms=dict(type='nms', iou_threshold=0.6), max_per_img=100))
tta_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(
type='TestTimeAug',
transforms=[[{
'type': 'Resize',
'scale': (640, 640),
'keep_ratio': True
}, {
'type': 'Resize',
'scale': (320, 320),
'keep_ratio': True
}, {
'type': 'Resize',
'scale': (960, 960),
'keep_ratio': True
}],
[{
'type': 'RandomFlip',
'prob': 1.0
}, {
'type': 'RandomFlip',
'prob': 0.0
}],
[{
'type': 'Pad',
'size': (960, 960),
'pad_val': {
'img': (114, 114, 114)
}
}],
[{
'type':
'PackDetInputs',
'meta_keys':
('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'flip', 'flip_direction')
}]])
]
# 模型 RTMDet-tiny
model = dict(
type='RTMDet',
data_preprocessor=dict(
type='DetDataPreprocessor',
mean=[103.53, 116.28, 123.675],
std=[57.375, 57.12, 58.395],
bgr_to_rgb=False,
batch_augments=None),
backbone=dict(
type='CSPNeXt',
arch='P5',
expand_ratio=0.5,
deepen_factor=0.167,
widen_factor=0.375,
channel_attention=True,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU', inplace=True),
init_cfg=dict(
type='Pretrained',
prefix='backbone.',
checkpoint=
'checkpoint/rtmdet/cspnext-tiny_imagenet_600e.pth'
)),
neck=dict(
type='CSPNeXtPAFPN',
in_channels=[96, 192, 384],
out_channels=96,
num_csp_blocks=1,
expand_ratio=0.5,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU', inplace=True)),
bbox_head=dict(
type='RTMDetSepBNHead',
num_classes=NUM_CLASSES,
in_channels=96,
stacked_convs=2,
feat_channels=96,
anchor_generator=dict(
type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
bbox_coder=dict(type='DistancePointBBoxCoder'),
loss_cls=dict(
type='QualityFocalLoss',
use_sigmoid=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
with_objectness=False,
exp_on_reg=False,
share_conv=True,
pred_kernel_size=1,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU', inplace=True)),
train_cfg=dict(
assigner=dict(type='DynamicSoftLabelAssigner', topk=13),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=30000,
min_bbox_size=0,
score_thr=0.001,
nms=dict(type='nms', iou_threshold=0.65),
max_per_img=300))
train_pipeline_stage2 = [
dict(type='LoadImageFromFile', backend_args=None),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='RandomResize',
scale=(640, 640),
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=(640, 640)),
dict(type='YOLOXHSVRandomAug'),
dict(type='RandomFlip', prob=0.5),
dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
dict(type='PackDetInputs')
]
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0002,
update_buffers=True,
priority=49),
dict(
type='PipelineSwitchHook',
switch_epoch=MAX_EPOCHS - stage2_num_epochs,
switch_pipeline=train_pipeline_stage2)
]
略
_base_ = ['mmpose::_base_/default_runtime.py']
# 数据集类型及路径
dataset_type = 'CocoDataset'
data_mode = 'topdown'
data_root = 'data/Ear210_Keypoint_Dataset_coco/'
# 三角板关键点检测数据集-元数据
dataset_info = {
'dataset_name':'Ear210_Keypoint_Dataset_coco',
'classes':'ear',
'paper_info':{
'author':'Tongji Zihao',
'title':'Triangle Keypoints Detection',
'container':'OpenMMLab',
'year':'2023',
'homepage':'https://space.bilibili.com/1900783'
},
'keypoint_info': {
0: {'name': '肾上腺', 'id': 0, 'color': [101, 205, 228], 'type': '', 'swap': ''},
1: {'name': '耳尖', 'id': 1, 'color': [240, 128, 128], 'type': '', 'swap': ''},
2: {'name': '胃', 'id': 2, 'color': [154, 205, 50], 'type': '', 'swap': ''},
3: {'name': '眼', 'id': 3, 'color': [34, 139, 34], 'type': '', 'swap': ''},
4: {'name': '口', 'id': 4, 'color': [139, 0, 0], 'type': '', 'swap': ''},
5: {'name': '肝', 'id': 5, 'color': [255, 165, 0], 'type': '', 'swap': ''},
6: {'name': '对屏尖', 'id': 6, 'color': [255, 0, 255], 'type': '', 'swap': ''},
7: {'name': '心', 'id': 7, 'color': [255, 255, 0], 'type': '', 'swap': ''},
8: {'name': '肺', 'id': 8, 'color': [29, 123,243], 'type': '', 'swap': ''},
9: {'name': '肺2', 'id': 9, 'color': [0, 255, 255], 'type': '', 'swap': ''},
10: {'name': '膀胱', 'id': 10, 'color': [128, 0, 128], 'type': '', 'swap': ''},
11: {'name': '脾', 'id': 11, 'color': [74, 181, 57], 'type': '', 'swap': ''},
12: {'name': '角窝中', 'id': 12, 'color': [165, 42, 42], 'type': '', 'swap': ''},
13: {'name': '神门', 'id': 13, 'color': [128, 128, 0], 'type': '', 'swap': ''},
14: {'name': '肾', 'id': 14, 'color': [255, 0, 0], 'type': '', 'swap': ''},
15: {'name': '耳门', 'id': 15, 'color': [34, 139, 34], 'type': '', 'swap': ''},
16: {'name': '听宫', 'id': 16, 'color': [255, 129, 0], 'type': '', 'swap': ''},
17: {'name': '听会', 'id': 17, 'color': [70, 130, 180], 'type': '', 'swap': ''},
18: {'name': '肩', 'id': 18, 'color': [63, 103,165], 'type': '', 'swap': ''},
19: {'name': '扁桃体', 'id': 19, 'color': [66, 77, 229], 'type': '', 'swap': ''},
20: {'name': '腰骶椎', 'id': 20, 'color': [255, 105, 180], 'type': '', 'swap': ''}
},
'skeleton_info': {
0: {'link':('眼','扁桃体'),'id': 0,'color': [100,150,200]},
1: {'link':('耳门','听宫'),'id': 1,'color': [200,100,150]},
2: {'link':('听宫','听会'),'id': 2,'color': [150,120,100]},
3: {'link':('耳门','听会'),'id': 3,'color': [66,77,229]}
},
'joint_weights':[1.0] * 21,
'sigmas':[0.025] * 21
}
NUM_KEYPOINTS = len(dataset_info['keypoint_info'])
# 训练超参数
max_epochs = 200 # 训练 epoch 总数
val_interval = 10 # 每隔多少个 epoch 保存一次权重文件
train_cfg = {'max_epochs': max_epochs, 'val_interval': val_interval}
train_batch_size = 32
val_batch_size = 8
stage2_num_epochs = 10
base_lr = 4e-3
randomness = dict(seed=21)
# 优化器
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
# 学习率
param_scheduler = [
dict(
type='LinearLR', start_factor=1.0e-5, by_epoch=False, begin=0, end=1000),
dict(
# use cosine lr from 210 to 420 epoch
type='CosineAnnealingLR',
eta_min=base_lr * 0.05,
begin=max_epochs // 2,
end=max_epochs,
T_max=max_epochs // 2,
by_epoch=True,
convert_to_iter_based=True),
]
# automatically scaling LR based on the actual training batch size
auto_scale_lr = dict(base_batch_size=1024)
# codec settings
codec = dict(
type='SimCCLabel',
input_size=(256, 256),
sigma=(12, 12),
simcc_split_ratio=2.0,
normalize=False,
use_dark=False)
# 不同输入图像尺寸的参数搭配
# input_size=(256, 256),
# sigma=(12, 12)
# in_featuremap_size=(8, 8)
# input_size可以换成 256、384、512、1024,三个参数等比例缩放
# sigma 表示关键点一维高斯分布的标准差,越大越容易学习,但精度上限会降低,越小越严格,对于人体、人脸等高精度场景,可以调小,RTMPose 原始论文中为 5.66
# 不同模型的 config: https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/rtmpose/body_2d_keypoint
# 模型:RTMPose-S
model = dict(
type='TopdownPoseEstimator',
data_preprocessor=dict(
type='PoseDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True),
backbone=dict(
_scope_='mmdet',
type='CSPNeXt',
arch='P5',
expand_ratio=0.5,
deepen_factor=0.33,
widen_factor=0.5,
out_indices=(4, ),
channel_attention=True,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU'),
init_cfg=dict(
type='Pretrained',
prefix='backbone.',
checkpoint='checkpoint/cspnext-s_imagenet_600e-ea671761.pth'
)),
head=dict(
type='RTMCCHead',
in_channels=512,
out_channels=NUM_KEYPOINTS,
input_size=codec['input_size'],
in_featuremap_size=(8, 8),
simcc_split_ratio=codec['simcc_split_ratio'],
final_layer_kernel_size=7,
gau_cfg=dict(
hidden_dims=256,
s=128,
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type='KLDiscretLoss',
use_target_weight=True,
beta=10.,
label_softmax=True),
decoder=codec),
test_cfg=dict(flip_test=True))
## 模型:RTMPose-M
# model = dict(
# type='TopdownPoseEstimator',
# data_preprocessor=dict(
# type='PoseDataPreprocessor',
# mean=[123.675, 116.28, 103.53],
# std=[58.395, 57.12, 57.375],
# bgr_to_rgb=True),
# backbone=dict(
# _scope_='mmdet',
# type='CSPNeXt',
# arch='P5',
# expand_ratio=0.5,
# deepen_factor=0.67,
# widen_factor=0.75,
# out_indices=(4, ),
# channel_attention=True,
# norm_cfg=dict(type='SyncBN'),
# act_cfg=dict(type='SiLU'),
# init_cfg=dict(
# type='Pretrained',
# prefix='backbone.',
# checkpoint='checkpoint/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth'
# )),
# head=dict(
# type='RTMCCHead',
# in_channels=768,
# out_channels=NUM_KEYPOINTS,
# input_size=codec['input_size'],
# in_featuremap_size=(8, 8),
# simcc_split_ratio=codec['simcc_split_ratio'],
# final_layer_kernel_size=7,
# gau_cfg=dict(
# hidden_dims=256,
# s=128,
# expansion_factor=2,
# dropout_rate=0.,
# drop_path=0.,
# act_fn='SiLU',
# use_rel_bias=False,
# pos_enc=False),
# loss=dict(
# type='KLDiscretLoss',
# use_target_weight=True,
# beta=10.,
# label_softmax=True),
# decoder=codec),
# test_cfg=dict(flip_test=True))
## 模型:RTMPose-L
# model = dict(
# type='TopdownPoseEstimator',
# data_preprocessor=dict(
# type='PoseDataPreprocessor',
# mean=[123.675, 116.28, 103.53],
# std=[58.395, 57.12, 57.375],
# bgr_to_rgb=True),
# backbone=dict(
# _scope_='mmdet',
# type='CSPNeXt',
# arch='P5',
# expand_ratio=0.5,
# deepen_factor=1.,
# widen_factor=1.,
# out_indices=(4, ),
# channel_attention=True,
# norm_cfg=dict(type='SyncBN'),
# act_cfg=dict(type='SiLU'),
# init_cfg=dict(
# type='Pretrained',
# prefix='backbone.',
# checkpoint='https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth'
# )),
# head=dict(
# type='RTMCCHead',
# in_channels=1024,
# out_channels=NUM_KEYPOINTS,
# input_size=codec['input_size'],
# in_featuremap_size=(8, 8),
# simcc_split_ratio=codec['simcc_split_ratio'],
# final_layer_kernel_size=7,
# gau_cfg=dict(
# hidden_dims=256,
# s=128,
# expansion_factor=2,
# dropout_rate=0.,
# drop_path=0.,
# act_fn='SiLU',
# use_rel_bias=False,
# pos_enc=False),
# loss=dict(
# type='KLDiscretLoss',
# use_target_weight=True,
# beta=10.,
# label_softmax=True),
# decoder=codec),
# test_cfg=dict(flip_test=True))
# # 模型:RTMPose-X
# model = dict(
# type='TopdownPoseEstimator',
# data_preprocessor=dict(
# type='PoseDataPreprocessor',
# mean=[123.675, 116.28, 103.53],
# std=[58.395, 57.12, 57.375],
# bgr_to_rgb=True),
# backbone=dict(
# _scope_='mmdet',
# type='CSPNeXt',
# arch='P5',
# expand_ratio=0.5,
# deepen_factor=1.33,
# widen_factor=1.25,
# out_indices=(4, ),
# channel_attention=True,
# norm_cfg=dict(type='SyncBN'),
# act_cfg=dict(type='SiLU'),
# init_cfg=dict(
# type='Pretrained',
# prefix='backbone.',
# checkpoint='https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth'
# )),
# head=dict(
# type='RTMCCHead',
# in_channels=1280,
# out_channels=NUM_KEYPOINTS,
# input_size=codec['input_size'],
# in_featuremap_size=(32, 32),
# simcc_split_ratio=codec['simcc_split_ratio'],
# final_layer_kernel_size=7,
# gau_cfg=dict(
# hidden_dims=256,
# s=128,
# expansion_factor=2,
# dropout_rate=0.,
# drop_path=0.,
# act_fn='SiLU',
# use_rel_bias=False,
# pos_enc=False),
# loss=dict(
# type='KLDiscretLoss',
# use_target_weight=True,
# beta=10.,
# label_softmax=True),
# decoder=codec),
# test_cfg=dict(flip_test=True))
backend_args = dict(backend='local')
# pipelines
train_pipeline = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
# dict(type='RandomHalfBody'),
dict(
type='RandomBBoxTransform', scale_factor=[0.8, 1.2], rotate_factor=30),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='mmdet.YOLOXHSVRandomAug'),
dict(
type='Albumentation',
transforms=[
dict(type='ChannelShuffle', p=0.5),
dict(type='CLAHE', p=0.5),
# dict(type='Downscale', scale_min=0.7, scale_max=0.9, p=0.2),
dict(type='ColorJitter', p=0.5),
dict(
type='CoarseDropout',
max_holes=4,
max_height=0.3,
max_width=0.3,
min_holes=1,
min_height=0.2,
min_width=0.2,
p=0.5),
]),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
val_pipeline = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
]
train_pipeline_stage2 = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
dict(type='RandomHalfBody'),
dict(
type='RandomBBoxTransform',
shift_factor=0.,
scale_factor=[0.75, 1.25],
rotate_factor=60),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='mmdet.YOLOXHSVRandomAug'),
dict(
type='Albumentation',
transforms=[
dict(type='Blur', p=0.1),
dict(type='MedianBlur', p=0.1),
dict(
type='CoarseDropout',
max_holes=1,
max_height=0.4,
max_width=0.4,
min_holes=1,
min_height=0.2,
min_width=0.2,
p=0.5),
]),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
# data loaders
train_dataloader = dict(
batch_size=train_batch_size,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo=dataset_info,
data_mode=data_mode,
ann_file='train_coco.json',
data_prefix=dict(img='images/'),
pipeline=train_pipeline,
))
val_dataloader = dict(
batch_size=val_batch_size,
num_workers=4,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo=dataset_info,
data_mode=data_mode,
ann_file='val_coco.json',
data_prefix=dict(img='images/'),
pipeline=val_pipeline,
))
test_dataloader = val_dataloader
default_hooks = {
'checkpoint': {'save_best': 'PCK','rule': 'greater','max_keep_ckpts': 2},
'logger': {'interval': 1}
}
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0002,
update_buffers=True,
priority=49),
dict(
type='mmdet.PipelineSwitchHook',
switch_epoch=max_epochs - stage2_num_epochs,
switch_pipeline=train_pipeline_stage2)
]
# evaluators
val_evaluator = [
dict(type='CocoMetric', ann_file=data_root + 'val_coco.json'),
dict(type='PCKAccuracy'),
dict(type='AUC'),
dict(type='NME', norm_mode='keypoint_distance', keypoint_indices=[1, 2])
]
test_evaluator = val_evaluator
python demo/topdown_demo_with_mmdet.py ../mmdetection/my_configs/xx/rtmdet_tiny_ear.py ../mmdetection/work_dirs/rtmdet_tiny_ear/best_coco_bbox_mAP_epoch_50.pth my_configs/rtmpose-s-ear.py work_dirs/rtmpose-s-ear/best_PCK_epoch_200.pth --input ../homework-1/data/ear.jpg --output-root ../homework-1/outputs/ --device cpu --bbox-thr 0.5 --kpt-thr 0.5 --nms-thr 0.3 --radius 12 --thickness 30 --draw-bbox --draw-heatmap --show-kpt-idx


