


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享MMPreTrain-预训练算法库:MMPreTrain是一个全新升级的预训练开源算法框架,旨在提供各种强大的预训练主干网络,并支持了不同的预训练策略。MMPreTrain是对MMClassification和MMSelfSup合并升级的新版本,并提供了许多新功能和预训练模型,旨在成为一个易于使用和用户友好的代码库,并简化学术研究活动和工程任务。
预训练阶段对视觉识别很重要,凭借丰富而强大的预训练模型,人们可以改进各种下游视觉任务。MMPreTrain提供丰富的模型,如主干网络VGG、ResNet、ViT等,也提供了自监督学习和多模态学习的主要模型。目前算法库支持开箱即用的推理API和模型,主要支持图像分类、图像描述、视觉问答、视觉定位、检索等任务。

MMPreTrain-安装

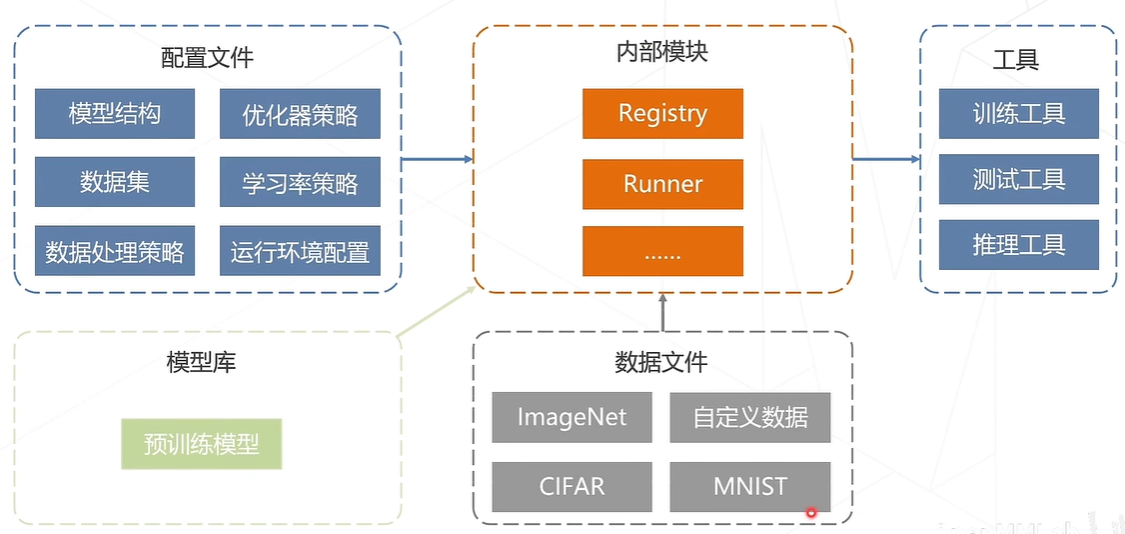
MMPreTrain预置了各类配置文件,人们可以在此基础上修改从而配置自己的模型。深度学习模型的训练主要涉及:
目前的整体代码框架如图

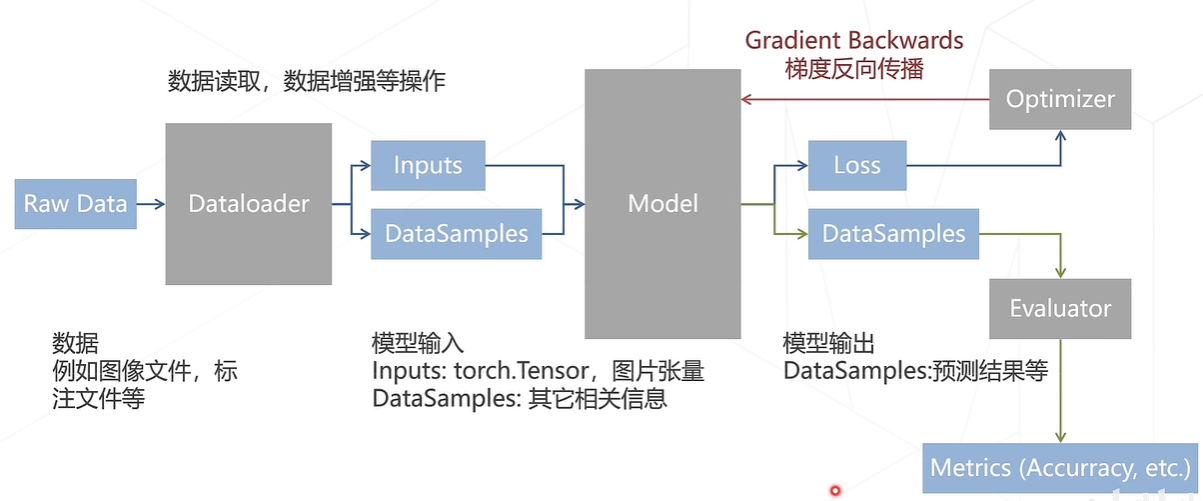
整体数据流(训练流程)
配置文件的运作方式
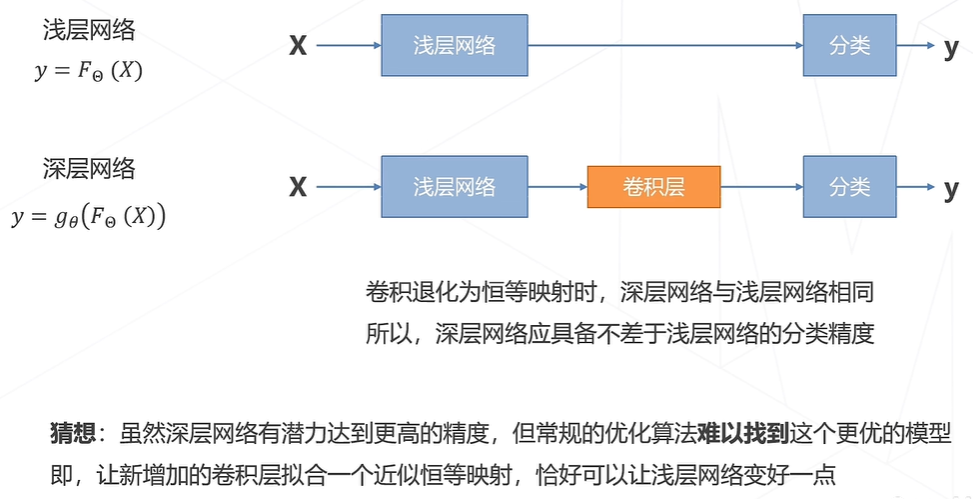
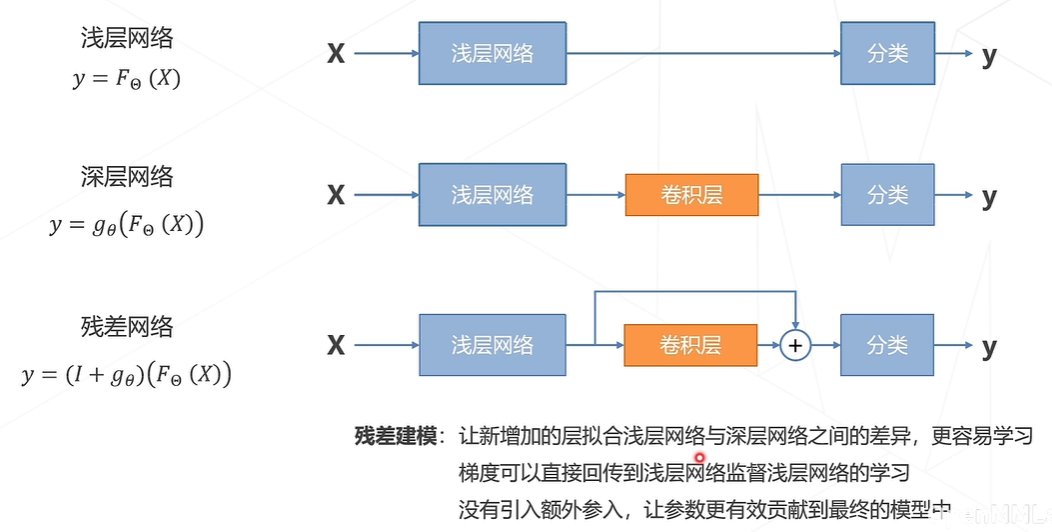
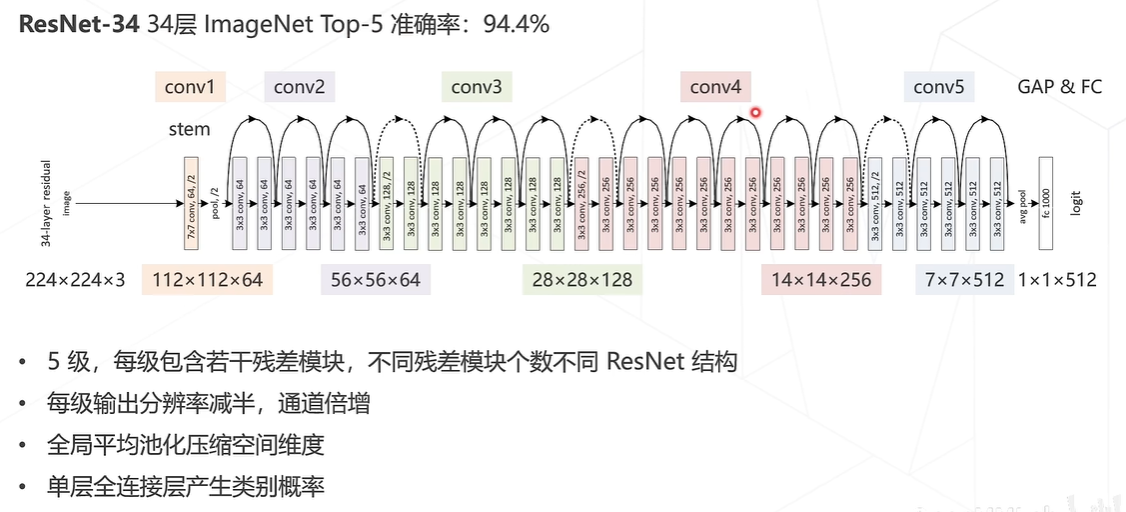
经典主干网络如AlexNet、VGG、ResNet等。早期的网络层数都比较浅,堆叠网络层数(即可学习的参数层)可以获得更好的结果。后面研究发现模型层数增加到一定程度后,分类正确率不增反降。
ResNet-34的网络结构图
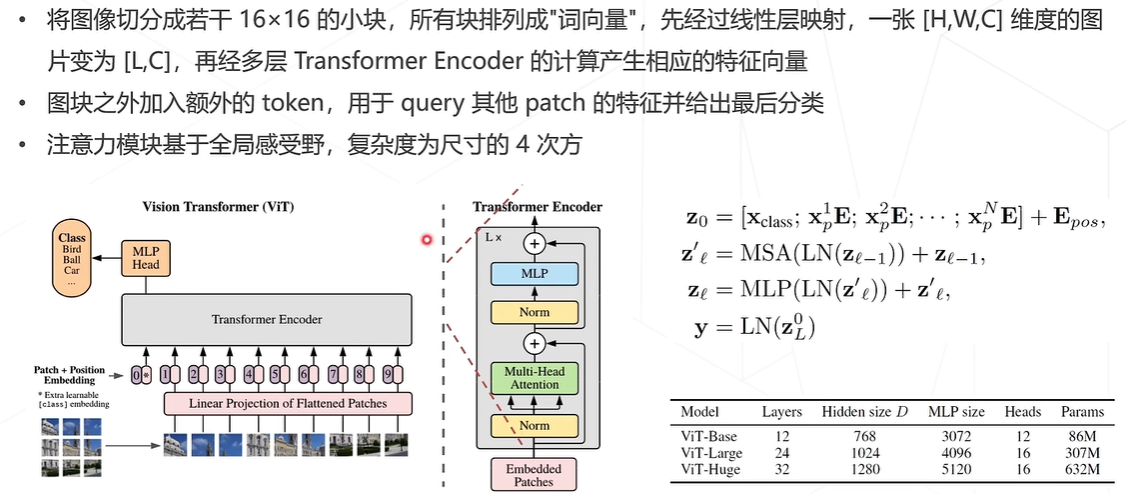
Vision Transformer(ViT)
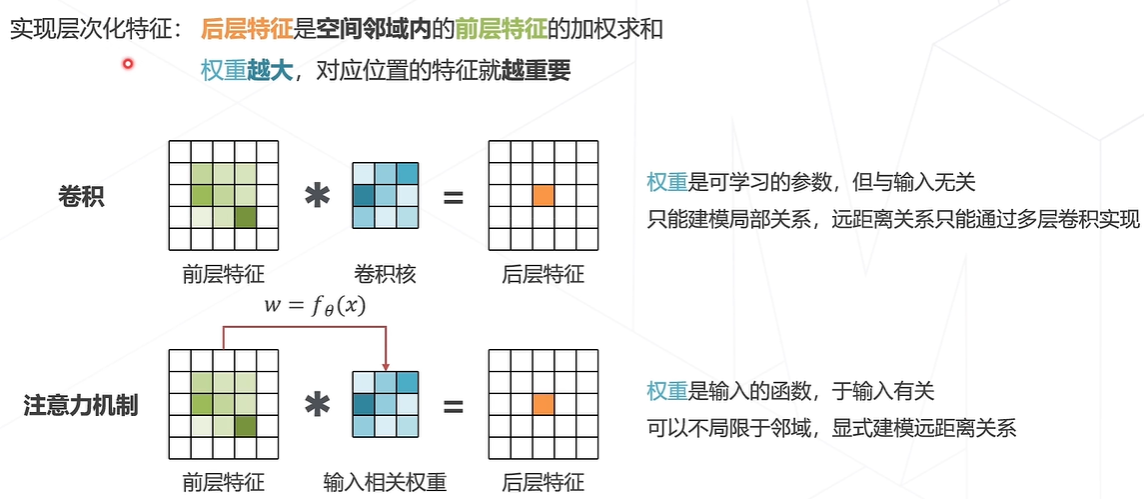
注意力机制(Attention Mechanism)
Attention for 1D data
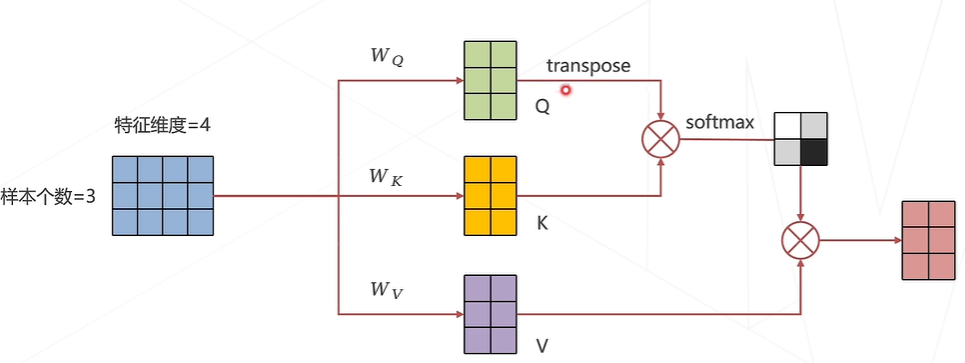
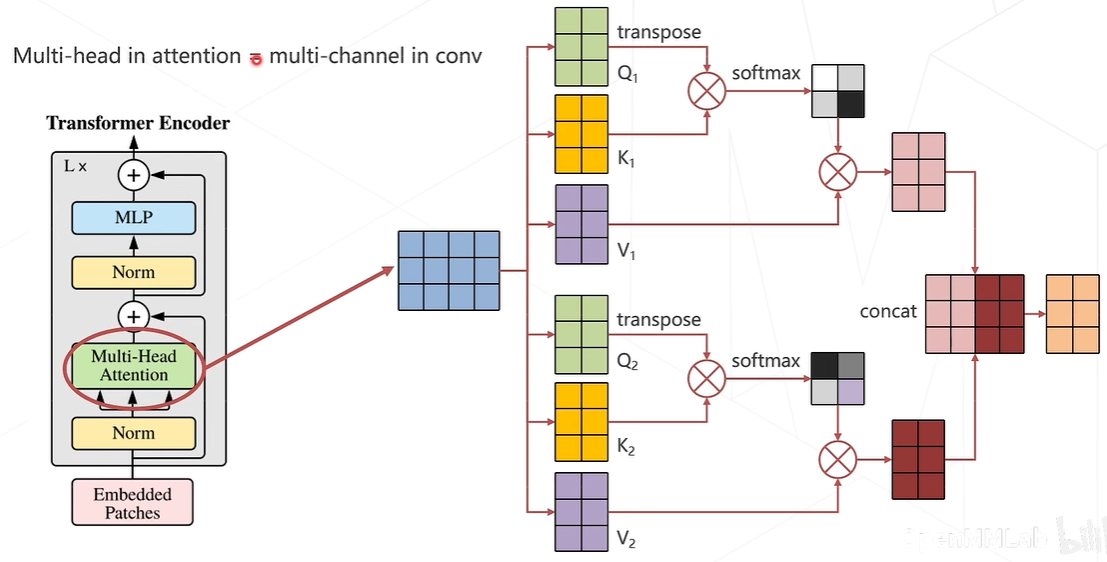
Multi-head(多头注意力机制)
自监督学习
有标注的数据成本太高,高质量的数据量少,为了利用未标注的海量数据而不依赖人工标注,让深度神经网络能够从数据本身学到对应的特征表达。最早基于各种理任务、基于对比学习、基于掩码学习。
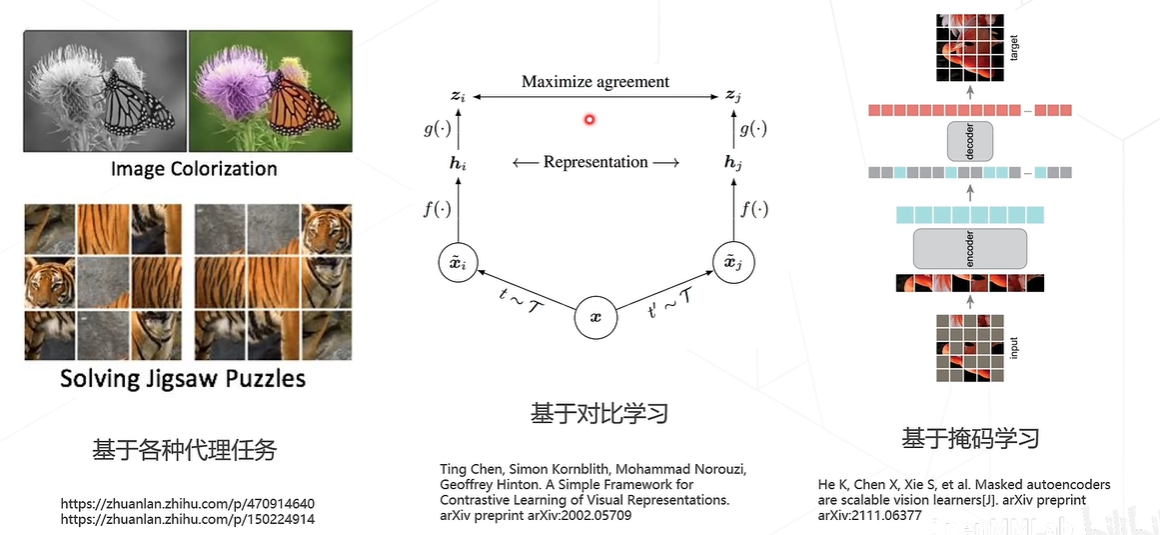
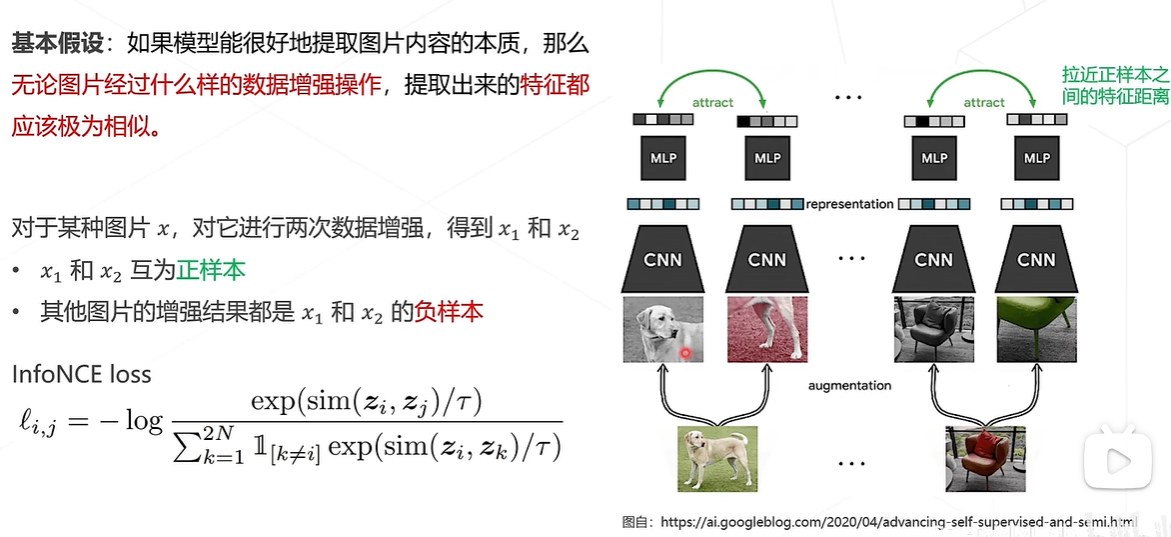
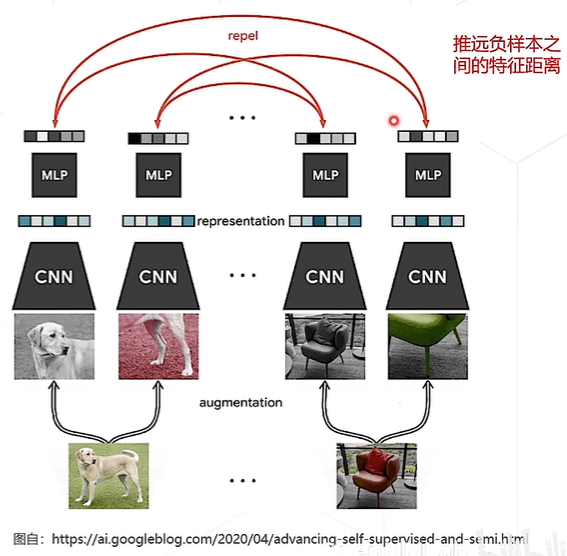
SimCLR-对比学习算法
Masked Autoencoders(MAE)-基于掩码学习算法
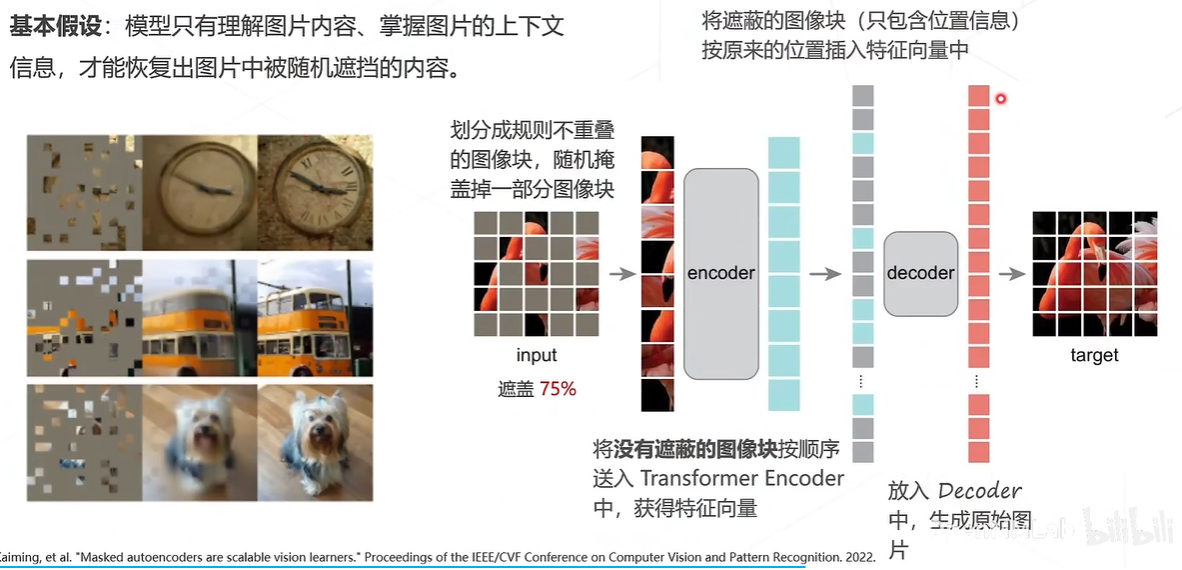
对比学习和掩码学习结合的方法如iBOT、DINOv2模型等。
多模态算法
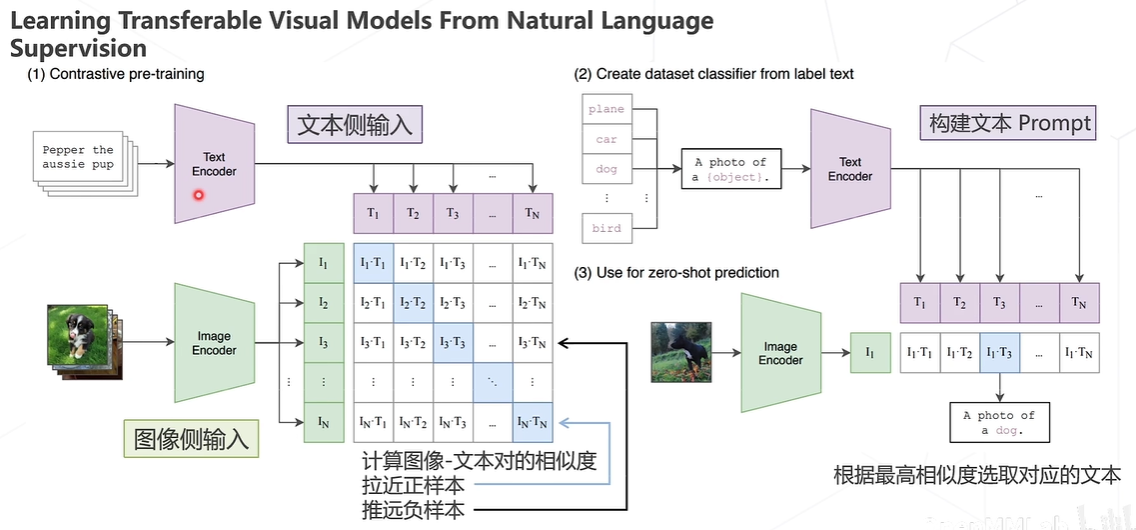
CLIP算法
BLIP算法
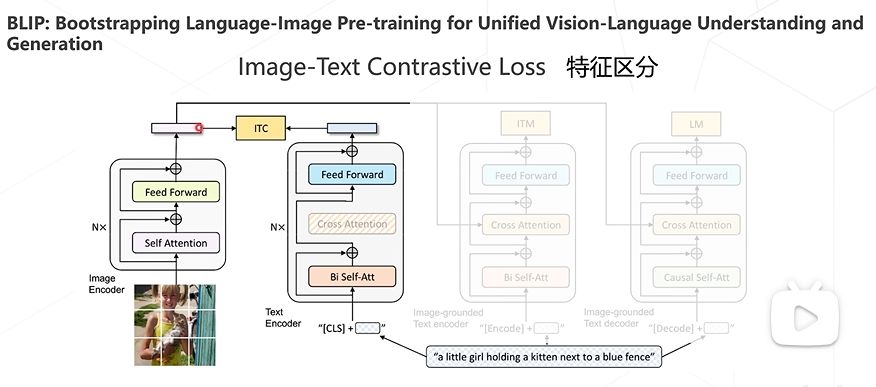
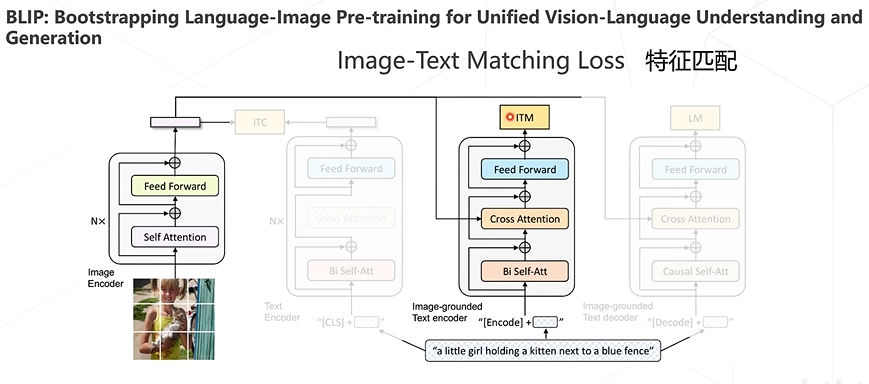
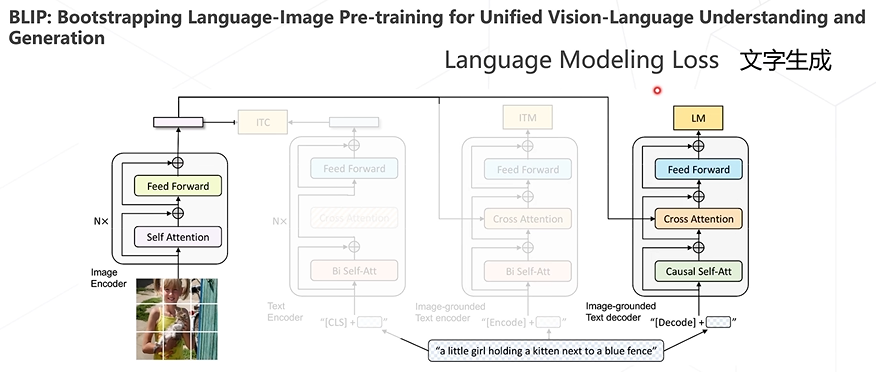
BLIP对三种loss进行了结合,以此构建了新的Vision Language Pre-training框架,并且可以完成各类下游任务,如图文检索、图像描述生成、视觉问答等。还有其他多种多模态算法,如BLIP-2、Flamingo、Kosmos-1、LLaVA等等。

