


535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享MMPretrain源自 MMClassification 和MMSelfSup,并开发了许多新功能, 是一个全新升级的预训练开源算法框架,旨在提供各种强大的预训练主干网络,并支持了不同的预训练策略。下面 是MMPreTrain的安装步骤:



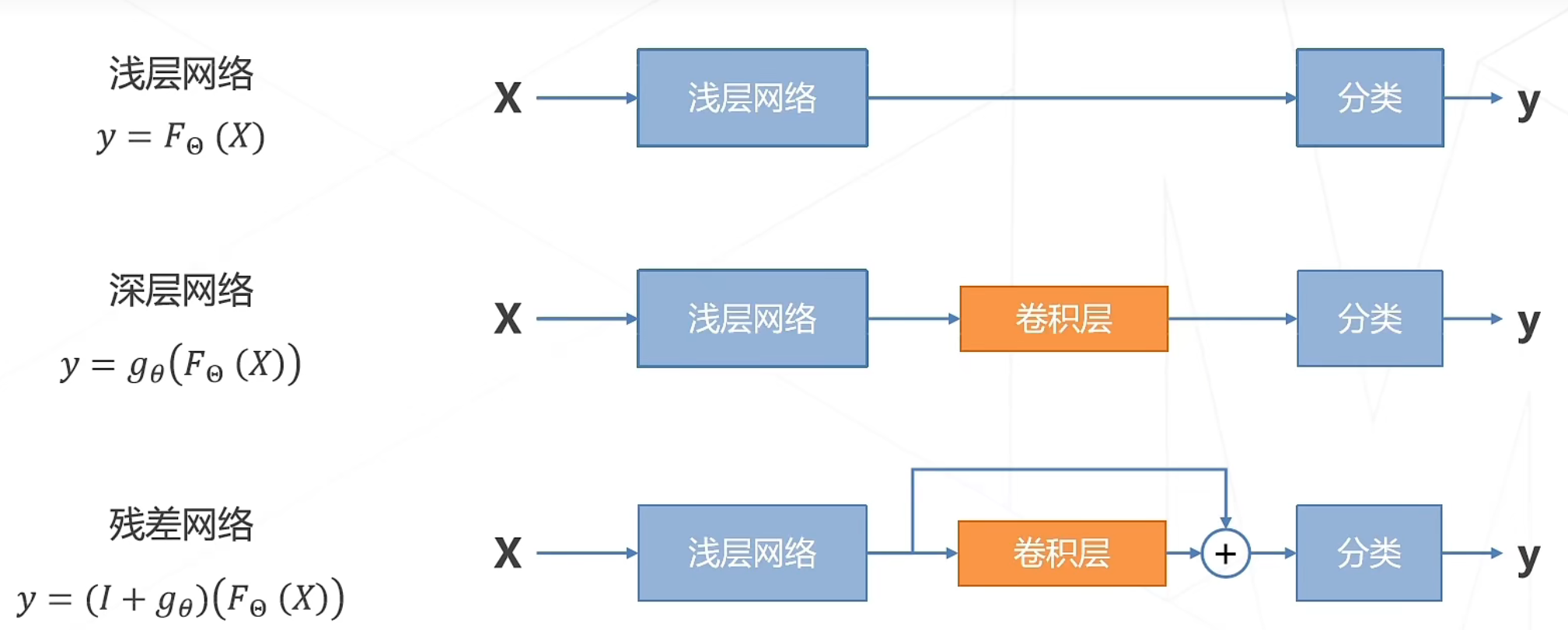
残差建模:让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习梯度可以直接回传到浅层网络监督浅层网络的学习没有引入额外参入,让参数更有效贡献到最终的模型中。
ResNet中的两种残差模块:
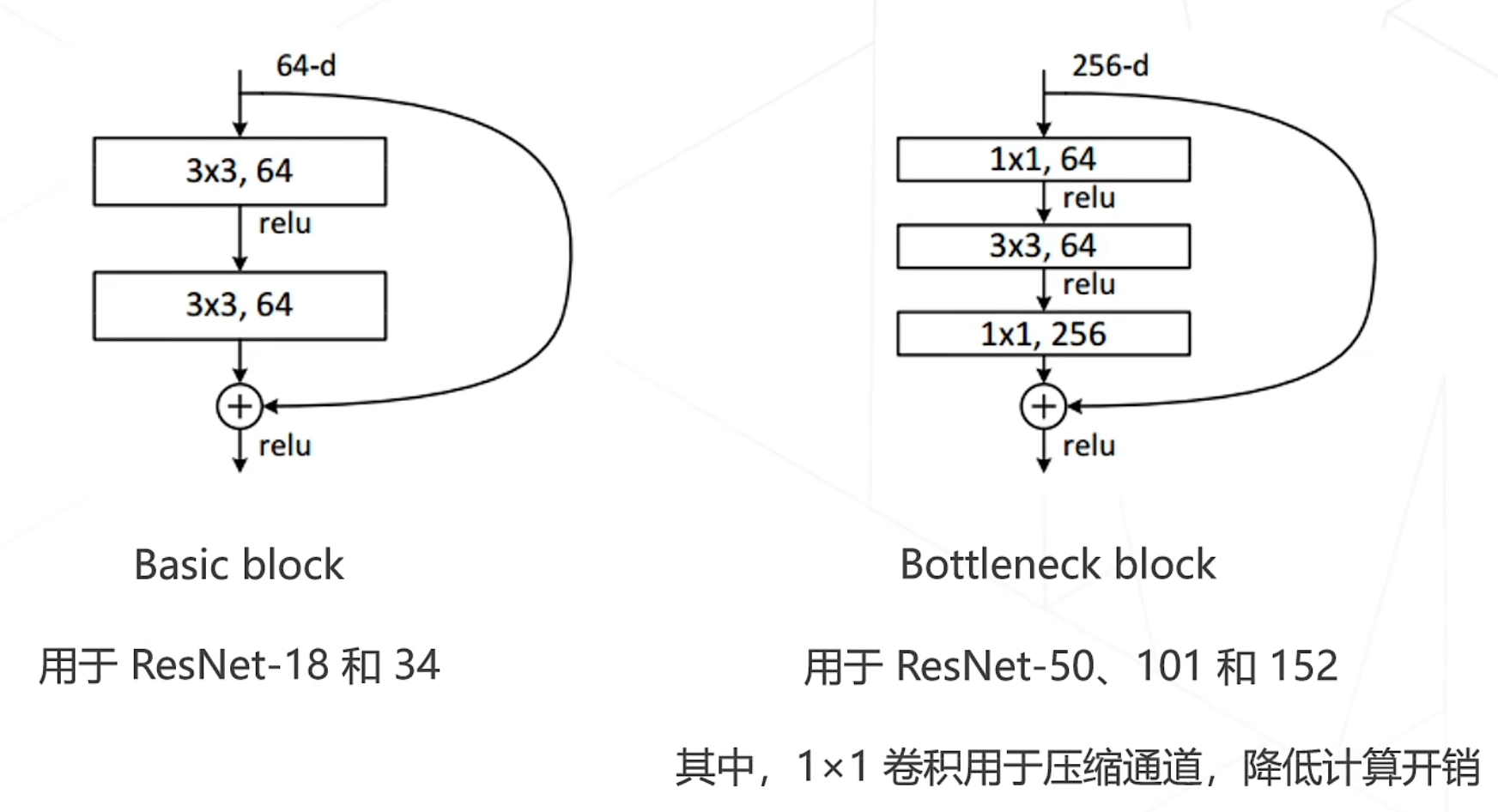
ResNet-34:34层ImageNet Top-5准确率:94.4%
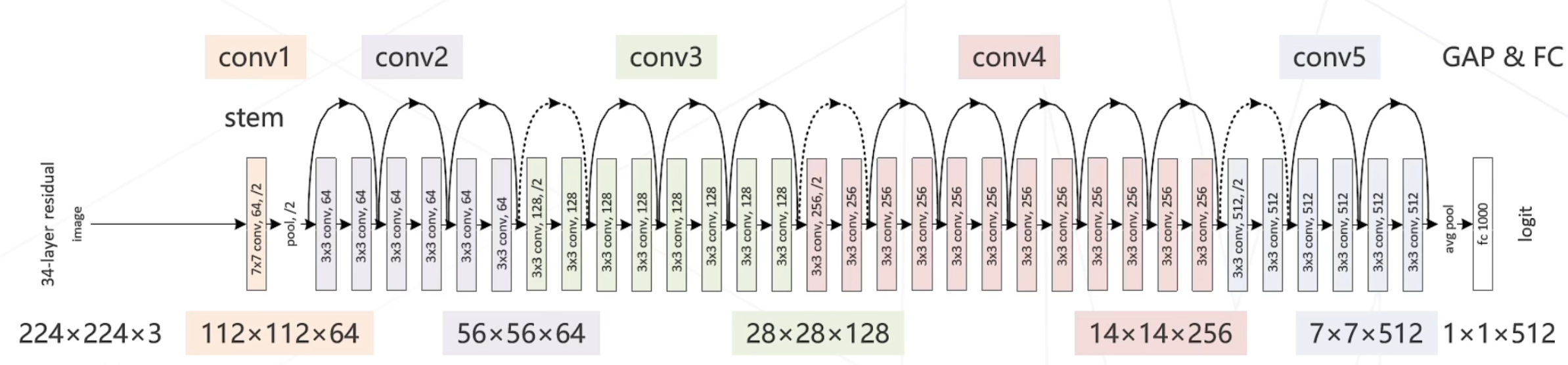
5级,每级包含若干残差模块,不同残差模块个数不同 ResNet 结构
每级输出分辨率减半,通道倍增
全局平均池化压缩空间维度
单层全连接层产生类别概率
模型示意图:
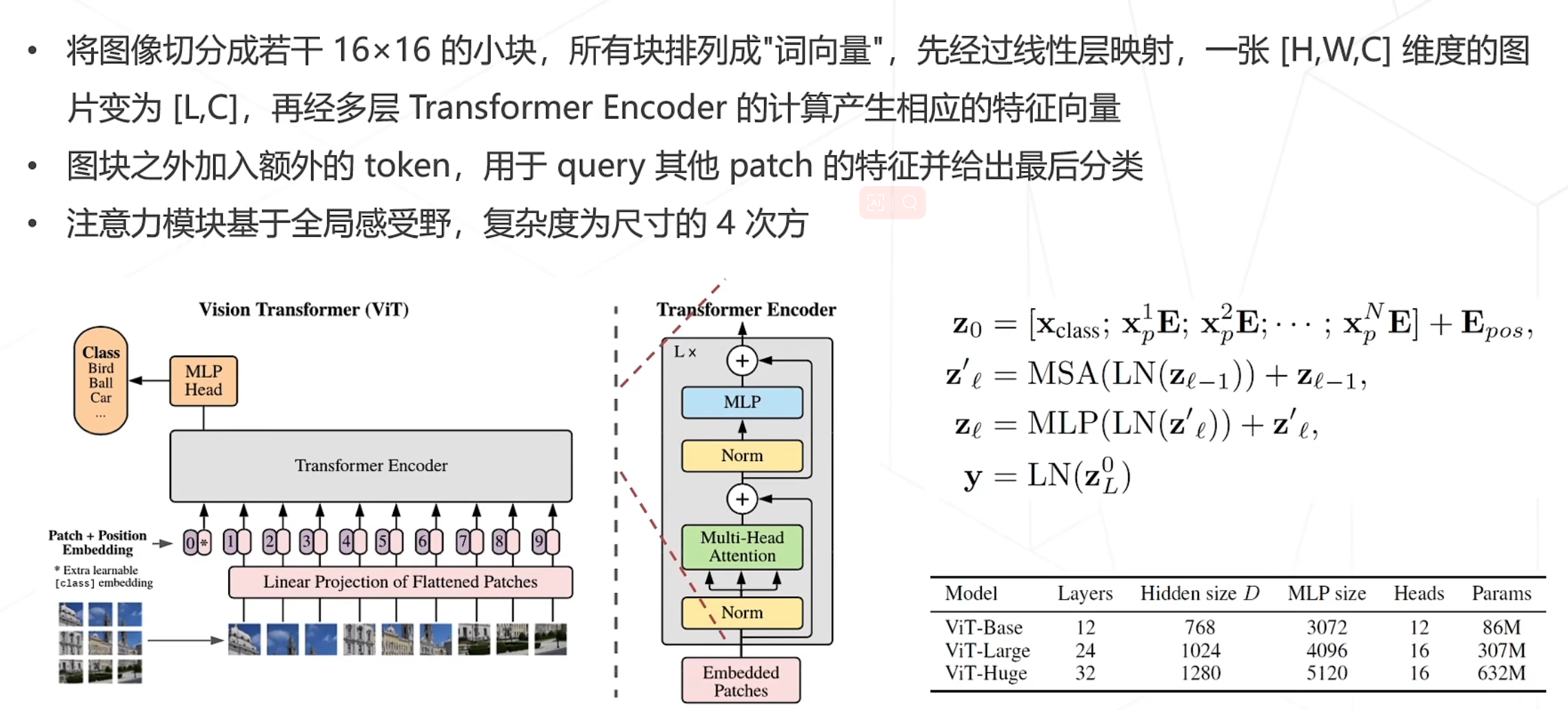
其中注意力机制是重要部分: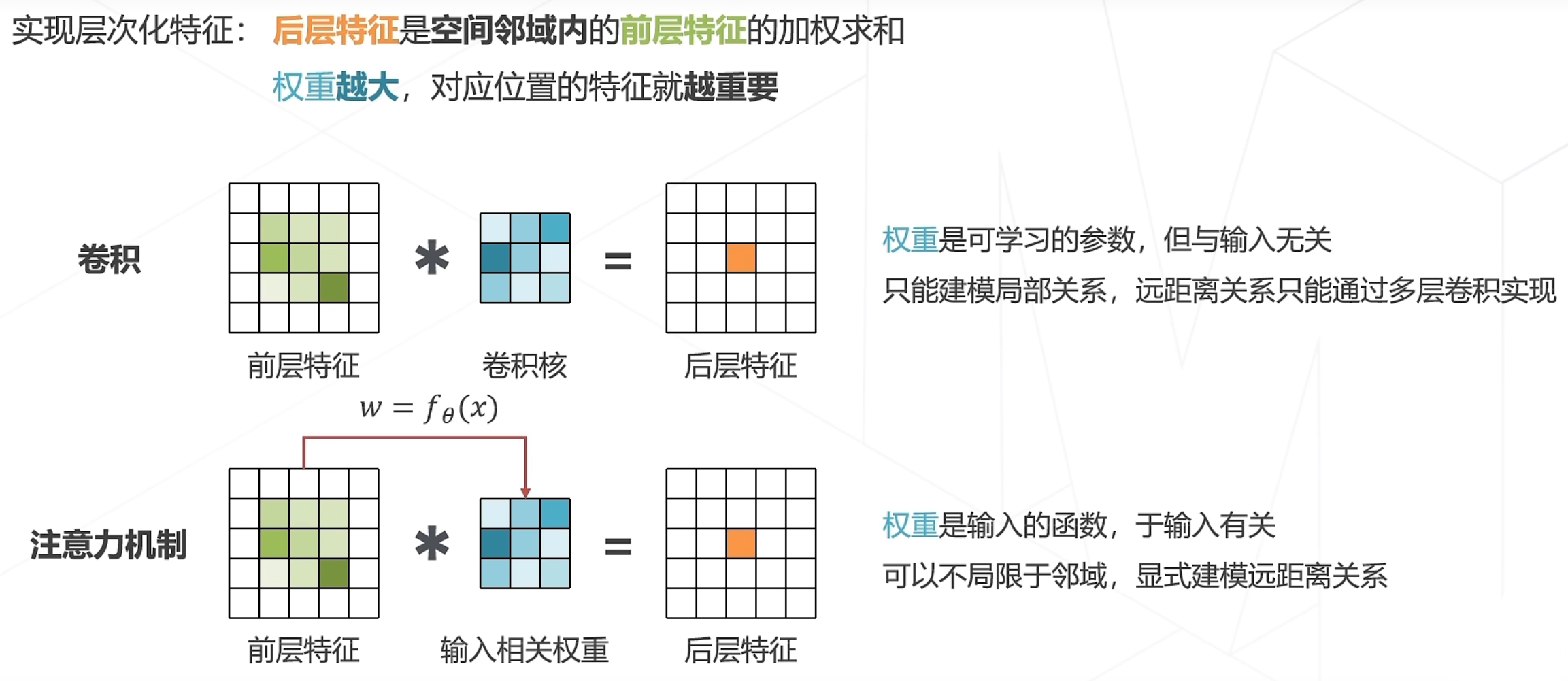
自监督学习的常见类型:基于各种代理任务、基于对比学习、基于掩码学习
基本假设:如果模型能很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,提取出来的特征都应该极为相似。
即:对于某种图片x,对它进行两次数据增强,得到x1和x2,x1和x2互为正样本,其他图片的增强结果都是x,和x的负样本
基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容
即:将输入图片划分成规则不重叠的图像块,随机掩盖掉一部分图像块,将没有遮蔽的图像块按顺序送入 Transformer Encoder中,获得特征向量,将遮蔽的图像块(只包含位置信息)按原来的位置插入特征向量中,最后放入Decoder里,生成原始图片。
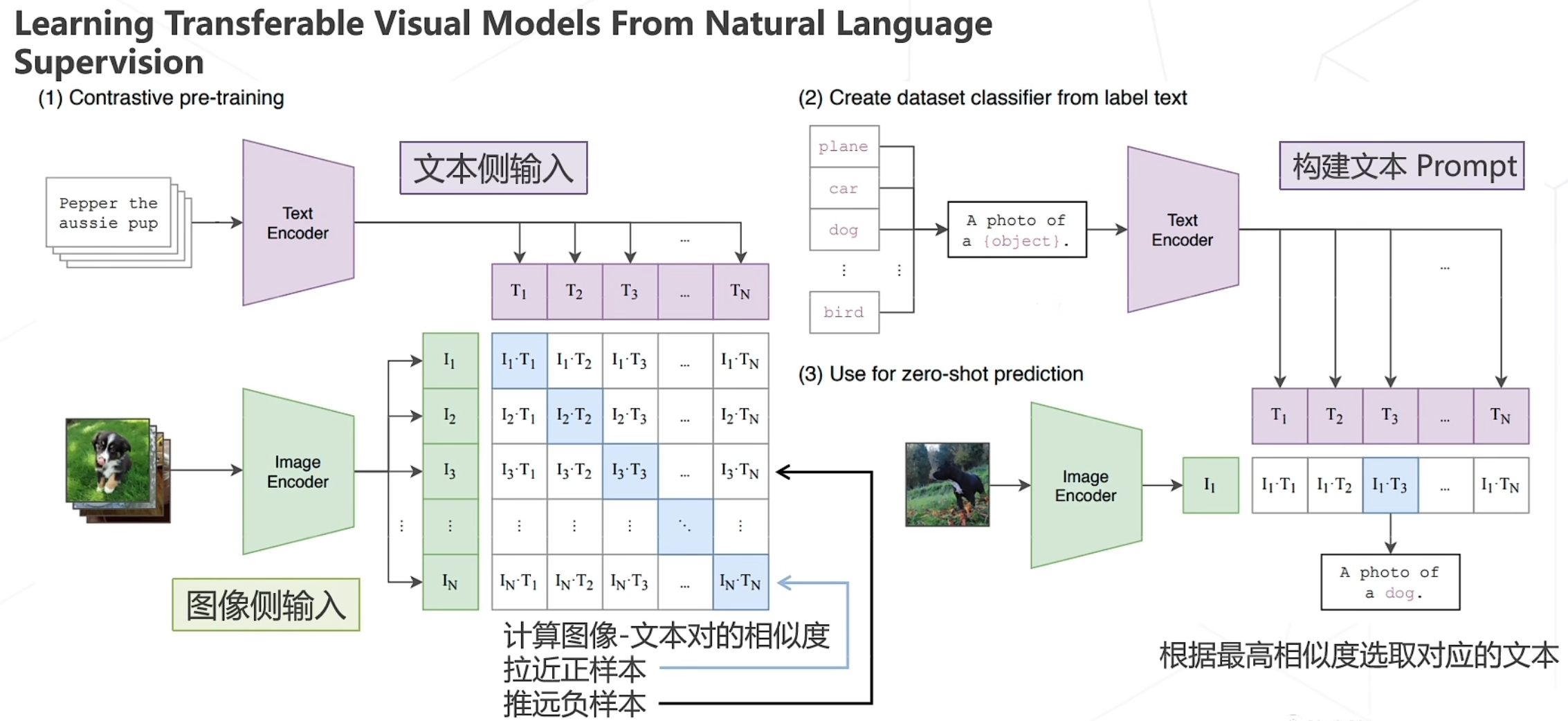
在大规模数据集上使用NLP监督预训练图像分类器,证明了简单的预训练任务,即预测图像和文本描述是否相匹配是一种有效的、可扩展的方法
用4亿对来自网络的图文数据对,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图像对应的文本描述,就可以进行 zero-shot transfer,并取得可观的结果
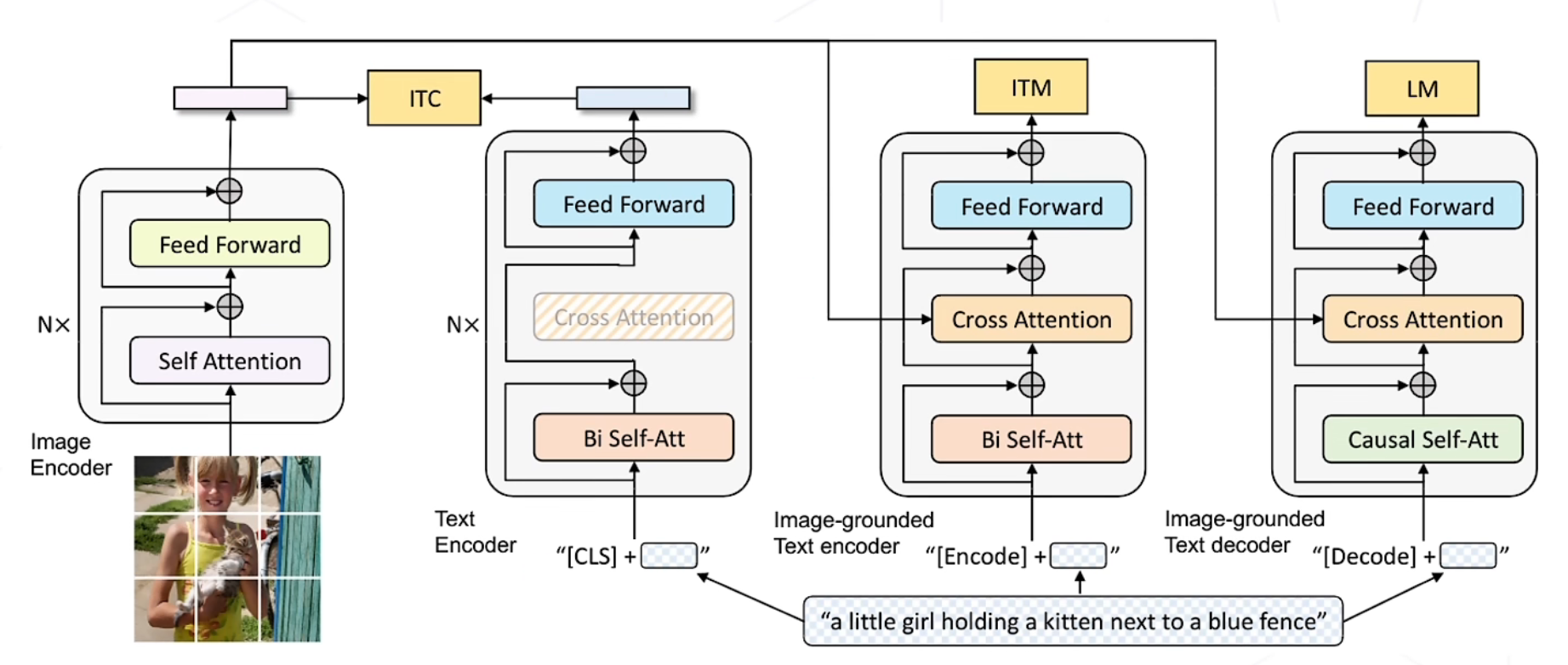
该模型有3个loss:ITC、ITM、LM,由Image Encoder分别于Text Encoder、Image-grouded Text encoder、Image-grounded Text decoder进行计算损失
ITC:对文本与图像进行特征匹配、特征区分,计算相似度loss
ITM:对文本与图像是否相匹配进行计算loss,二分类问题
LM:对文字生成的loss计算


