


144
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享课程:《Python程序设计》
班级: 2223
姓名: 陈振烨
学号:20222314
实验教师:王志强
实验日期:2023年5月10日
必修/选修: 公选课
根据南理工学姐的需求,编写网络爬虫,为了让南理工学姐能尽快看到自己喜欢看的最新图片,我们选择编写一个百度动态爬虫,为了减少南理工学姐端的操作难度,这里没有使用驱动,而是使用了构造的头来伪装浏览器,从而达到反爬,访问,以及发送下载请求的效果。
先通过微信询问南理工学姐喜欢看什么
然后运行自己写好的程序
# -*- coding: UTF-8 -*-"""
import requests
import tqdm
def configs(search, page, number):
"""
:param search:
:param page:
:param number:
:return:
"""
url = 'https://image.baidu.com/search/acjson'
params = {
"tn": "resultjson_com",
"logid": "11555092689241190059",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": search,
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "0",
"hd": "",
"latest": "",
"copyright": "",
"word": search,
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": str(60 * page),
"rn": number,
"gsm": "1e",
"1617626956685": ""
}
return url, params
def loadpic(number, page):
"""
:param number:
:param page:
:return:
"""
while (True):
if number == 0:
break
url, params = configs(search, page, number)
result = requests.get(url, headers=header, params=params).json()
url_list = []
for data in result['data'][:-1]:
url_list.append(data['thumbURL'])
for i in range(len(url_list)):
getImg(url_list[i], 60 * page + i, path)
bar.update(1)
number -= 1
if number == 0:
break
page += 1
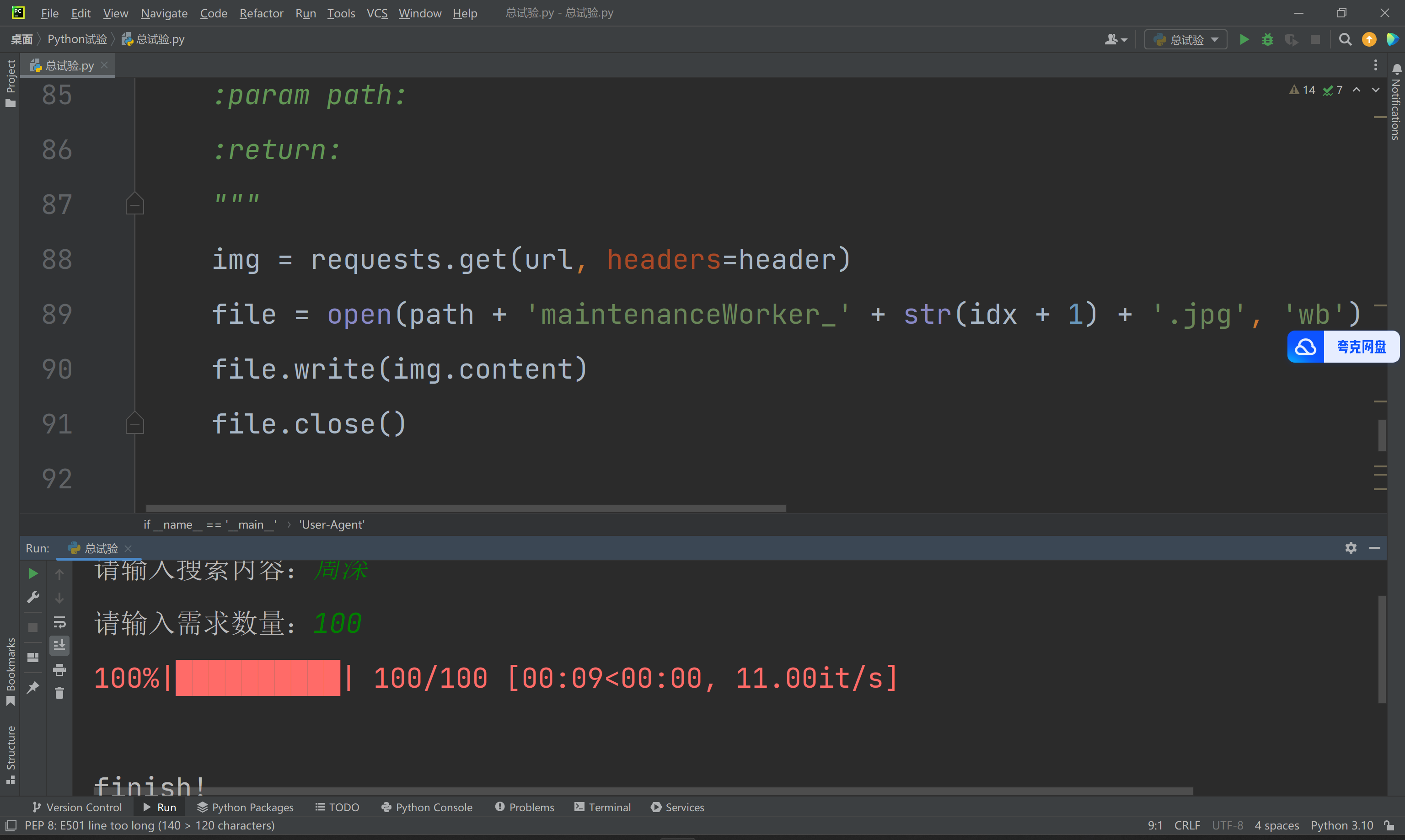
print("\nfinish!")
def getImg(url, idx, path):
"""
:param url:
:param idx:
:param path:
:return:
"""
img = requests.get(url, headers=header)
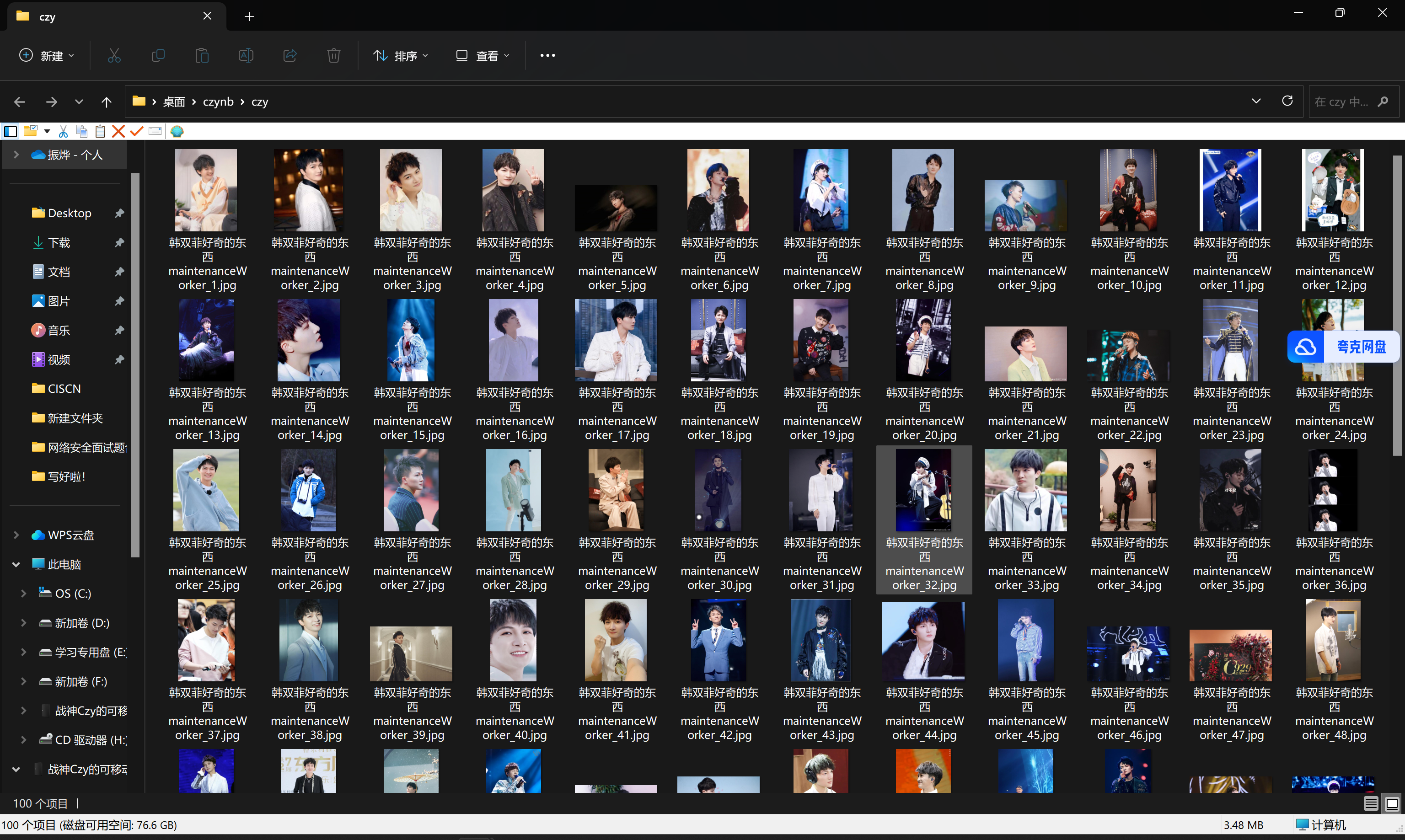
file = open(path + 'maintenanceWorker_' + str(idx + 1) + '.jpg', 'wb')
file.write(img.content)
file.close()
if __name__ == '__main__':
search = input("请输入搜索内容:")
number = int(input("请输入需求数量:"))
path = 'E:\桌面\czynb\czy\南理工学姐喜欢的东西'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
bar = tqdm.tqdm(total=number)
page = 0
loadpic(number, page)
运行截图如下:
试验感悟:
虽然难写,但是值得【doge】,回归正题,本次爬虫的主要难点在于header的构造,与传统的静态网页爬虫不同的地方在于我们成功地绕过了翻页以及开启浏览器两个让人头疼的环节,因为谷歌驱动会随着版本更新(这也是为什么我的微博爬虫没有成功的原因,因为我没有找到我当前谷歌浏览器对应版本的母驱动)。
从自身出发,个人认为工程量还是不够大,所以我又给自己加了个任务:写出一个简易版的植物大战僵尸,不做更多的描述,主要是寒假就开始做了,但是一直没有做出来,这学期也是学会了逆向以后经过各种手段偷到了贴图,music和原版的部分核心代码(本身开源但是我没找到,所以只能对exe下手了
ps:我其实不想说这个程序的,因为有一部分条件判断我实在不会实现,并且动态判定我做的不好,抄了原游戏一部分,但是我试验一直忘发了,我只是想让老师知道czy平时真的用python干了很多事情,所以求求老师原谅我吧不要挂我呜呜呜
源码就不全放了,放几张截图好了:
几乎3个截图才能放下一个双发射手的类,还是不放太多了,留着给南理工学姐用
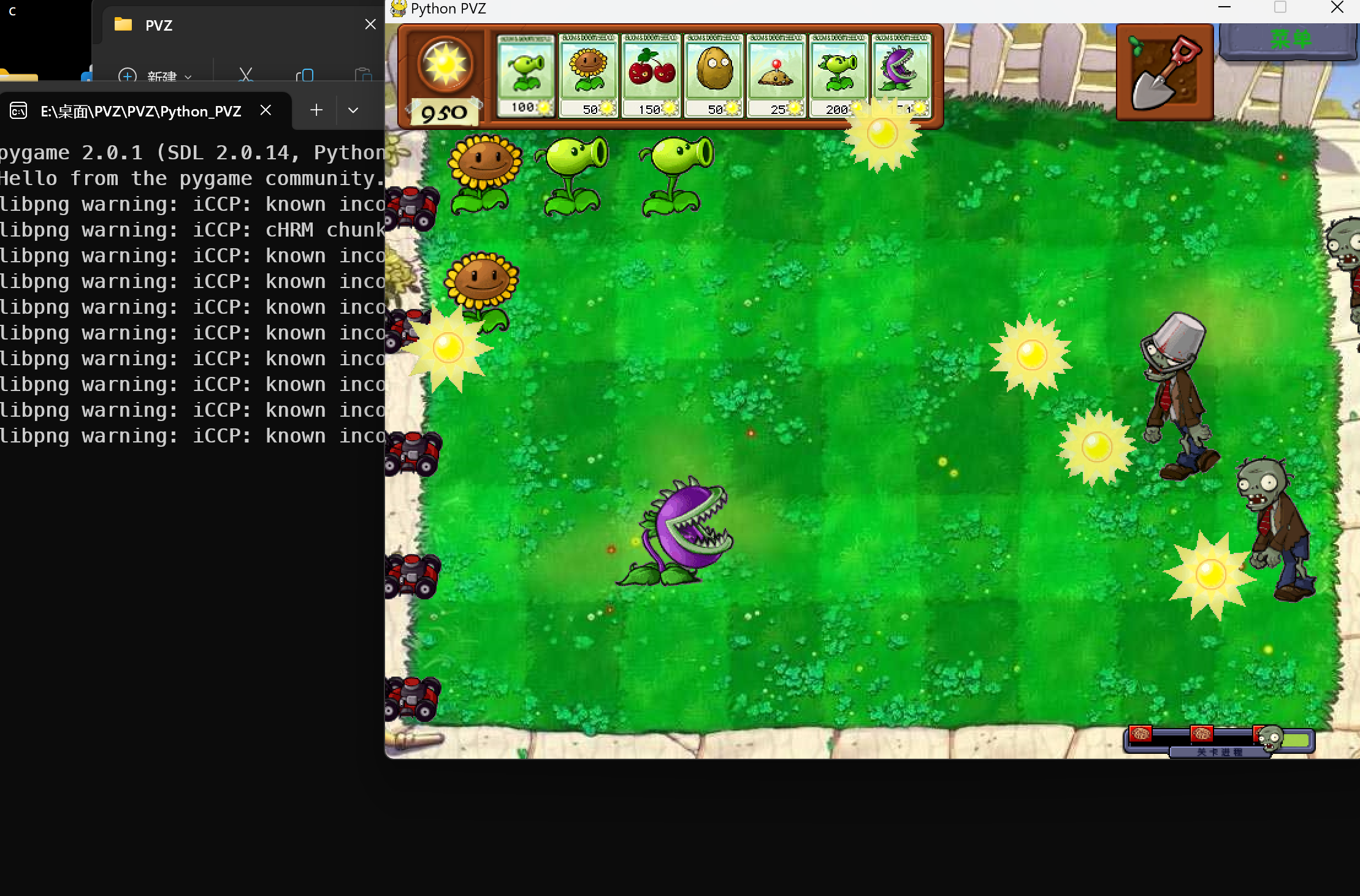
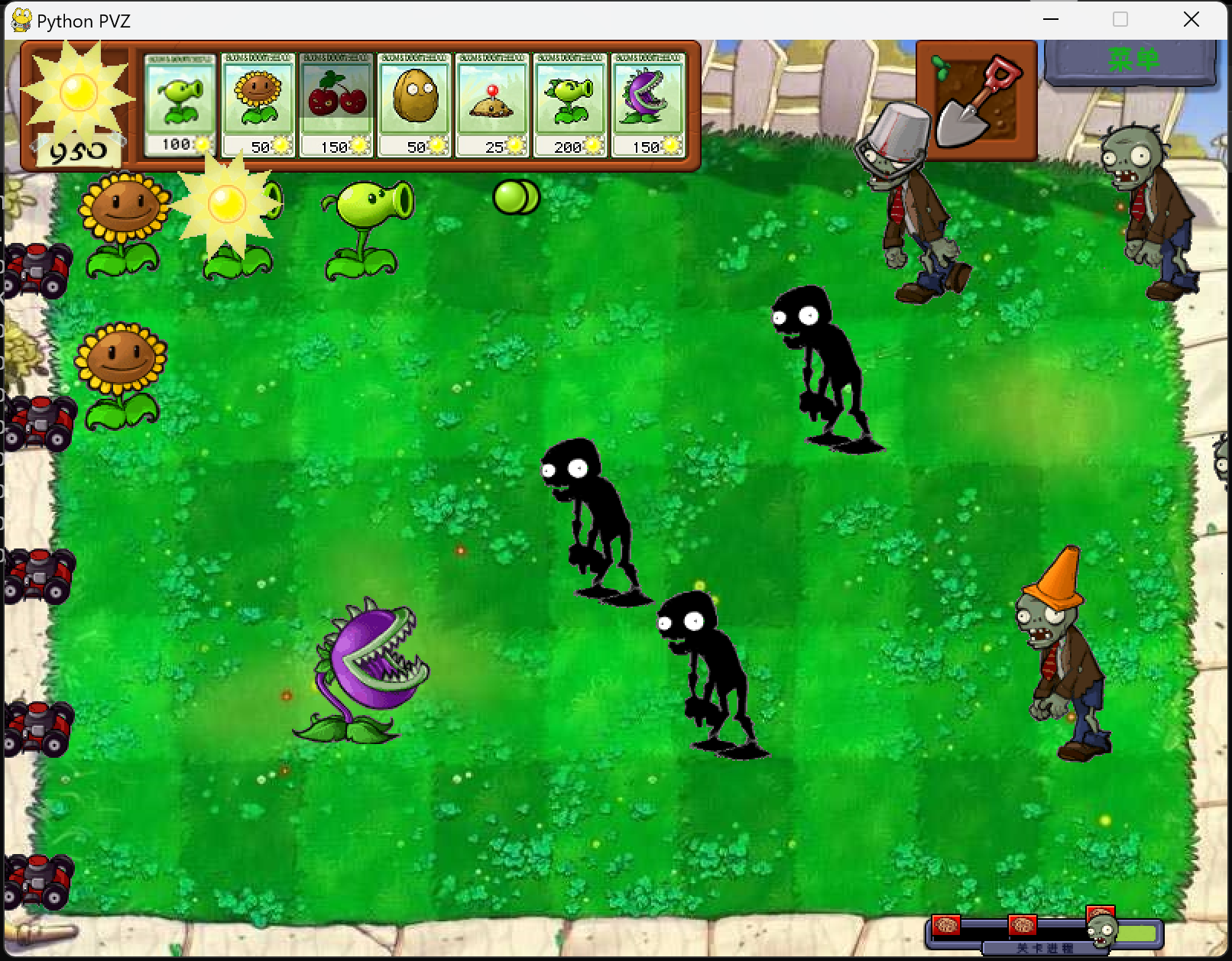
就到这里好了,这个学期还写了微博爬虫,坦克大战(但是并没有实现老师您说的ai对战,比较遗憾),五子棋,围棋(围棋这个是真难写),数独等小游戏,(贪吃蛇呢?贪吃蛇是我上学期玩剩下的)
老师原谅我吧,给个高分求求了

