533
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
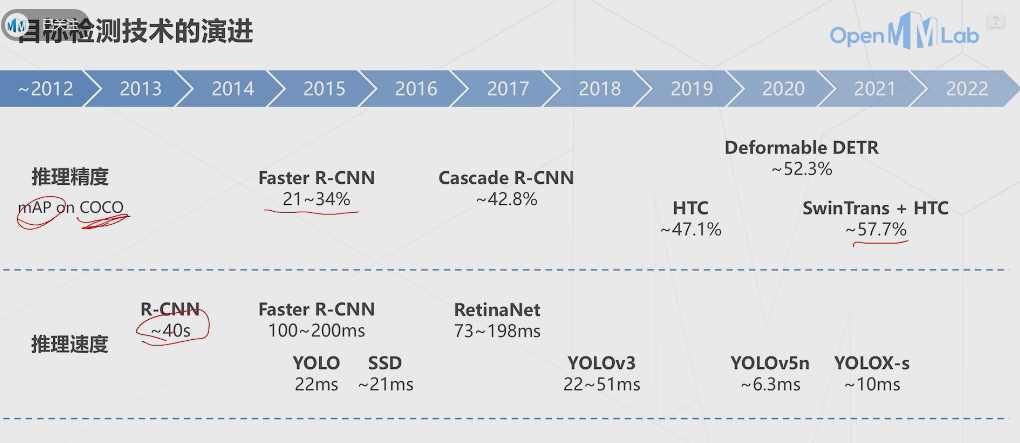
分享目标检测是计算机视觉领域的重要任务,其目标是在图像或视频中准确地识别和定位特定对象。目标检测的演进可以追溯到几十年前,以下是目标检测的主要演进过程:
基于手工特征的方法:早期的目标检测方法主要依赖于手工设计的特征,例如边缘、纹理和颜色等。这些方法通常结合使用滑动窗口和分类器,通过在图像中移动窗口并对每个窗口进行分类来检测目标。然而,这些方法受限于手工设计特征的局限性,难以应对复杂的场景和变化的目标。
基于机器学习的方法:随着机器学习的兴起,目标检测方法开始采用机器学习算法来学习特征和分类器。其中,基于Haar特征的级联分类器方法和基于HOG(方向梯度直方图)特征的SVM(支持向量机)方法成为了经典的目标检测算法。这些方法利用机器学习算法从大量标注的训练数据中学习目标的特征和分类器,从而实现目标的检测。
基于深度学习的方法:深度学习的兴起极大地推动了目标检测领域的发展。特别是卷积神经网络(CNN)的成功应用,使得目标检测的性能有了巨大的提升。深度学习方法将目标检测任务转化为一个端到端的回归或分类问题,通过在大规模数据集上训练深度神经网络,实现对目标的准确检测和定位。著名的深度学习目标检测算法包括RCNN(区域CNN)、Fast R-CNN、Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)等。
单阶段目标检测器:传统的目标检测方法通常是两阶段的,即首先生成候选区域,然后对候选区域进行分类。为了进一步提高目标检测的速度,单阶段目标检测器逐渐得到了关注。单阶段目标检测器在一个网络中同时完成目标的位置定位和分类,具有更快的检测速度。代表性的单阶段目标检测器包括YOLOv3、YOLOv4、YOLOv5和EfficientDet等。
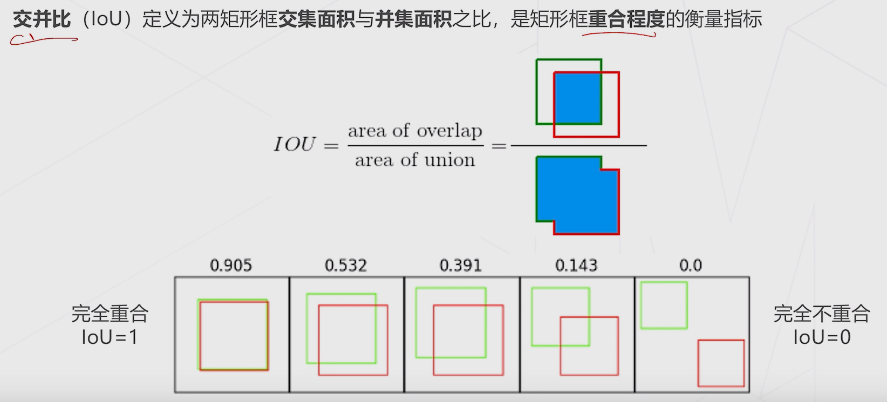
IOU的全称为交并比(Intersection over Union),是目标检测中使用的一个概念,IoU计算的是“预测的边框”和“真实的边框”的交叠率-,即它们的交集和并集的比值。最理想情况是完全重叠,即比值为1。


以目标检测为例:目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。

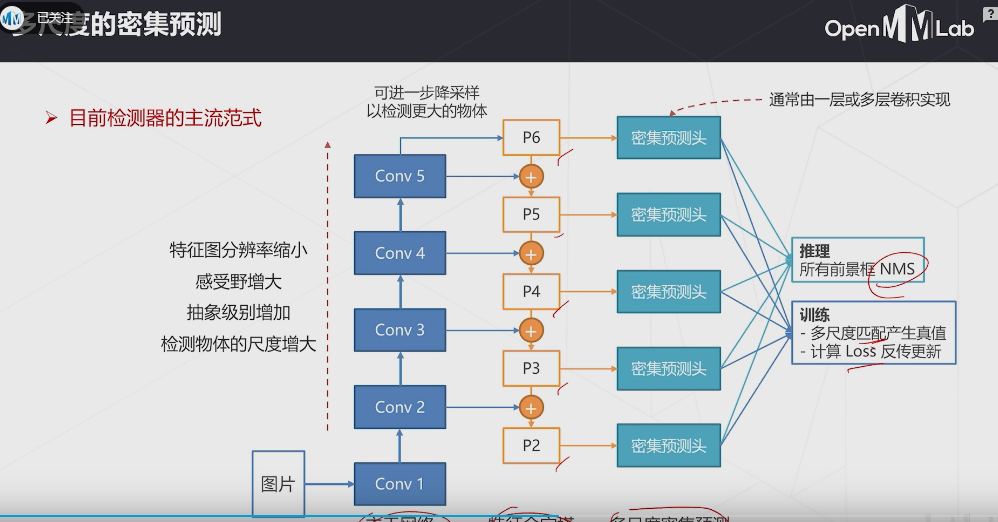
多尺度特征对于密集预测任务来说是必不可少的,包括目标检测、实例分割和语义分割。现有的SOTA方法通常先通过主干网络提取多尺度特征,然后通过轻量级模块(如 FPN)融合这些特征。 然而,我们认为通过这样的范例来融合多尺度特征可能是不够充分,因为与重量级主干网络相比,分配给特征融合的参数是有限的。
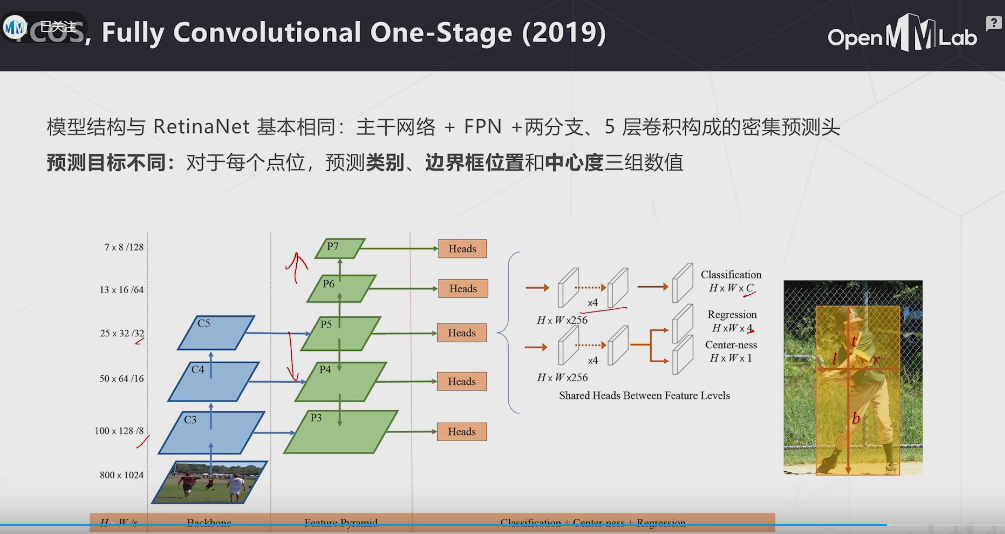
类似CornerNet、CenterNet,FCOS也是Anchor-free的检测模型,先预测下采样S倍的特征图上的各点类别,再预测各点的 l,r,t,b 四个值来确定bbox的大小位置,如下左图所示. 下右图则展示了两个重叠GT下特征图点的ambiguity问题,FCOS利用FPN和center sampling解决了这个问题. 同时提出center-ness分支,用于帮助NMS抑制低质量框,进一步提高网络的性能表现.
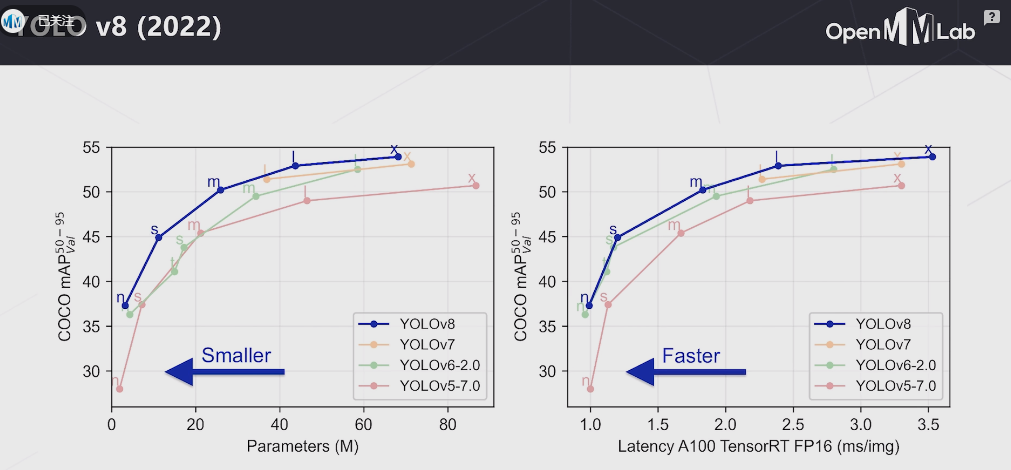
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。