



535
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
Github:https://github.com/open-mmlab/mmdetection/tree/tutorials
1.什么是目标检测
目标检测是计算机视觉领域的核心问题之一,其任务就是找出图像中所有感兴趣的目标,确定他们的类别和位置。由于各类不同物体有不同的外观,姿态,以及不同程度的遮挡,加上成像是光照等因素的干扰,目标检测一直以来是一个很有挑战性的问题。
目标检测任务主要可以分为四个小任务:
(1)分类classification:给定一张图像,要知道里面包含什么类别的目标。
(2)定位location:给定这个目标在图像中的位置。
(3)检测detection:定位出目标的位置并判断这个目标的类别。
(4)分割segmentation:确定每个像素属于哪个目标或者场景。
综上所述,目标检测是一个分类、回归问题的叠加。
2.目标检测的核心问题
(1)分类问题:图片(或者某个区域)属于哪个类别。
(2)定位问题:目标在图像中出现的位置。
(3)大小问题:目标在图像中的大小。
(4)形状问题:目标在图像中的姿态是什么样的。
3.目标检测算法分类

目标检测的发展可以划分为两个周期:
(1)传统目标检测算法(1998-2014):传统目标检测算法主要基于手工提取特征,具体步骤可概括为:选取感兴趣区域->对可能包含物体的区域进行特征分类->对提取的特征进行检测。虽然传统目标检测算法经过了十余年的发展,但是其识别效果并没有较大改善且运算量大,此处不再详细介绍。
(2)基于深度学习的目标检测算法(2014-):该方法主要分为Anchor-based的Two Stage和One Stage和Anchor-free两种思路
a)Two Stage:先预设一个区域,该区域称为Region Proposal,即一个可能包含待检测物体的预选框(简称RP),再通过卷积神经网络进行样本分类计算。该算法的流程是:特征提取 -> 生成RP -> 分类/回归定位。常见的Two Stage算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN等,其特点是检测精度高,但是检测速度不如One Stage方法高。
b)One Stage:直接在网络中提取特征值来分类目标和定位。该算法的流程是:特征提取 -> 分类/回归定位。常见的One Stage算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、YOLOv5、SSD、RetinaNet等,其特点是检测速度快,但是精度没有Two Stage方法高。
c)Anchor-free:该方法通过确定关键点的方式来完成检测,大大减少了网络超参数的数量。
4.目标检测的应用
(1)人脸检测:智能门控、人脸支付
(2)行人检测:智能辅助驾驶、智能监控
(3)车辆检测:自动驾驶、交通违章查询
(4)遥感检测:天气预测、军事目标检测

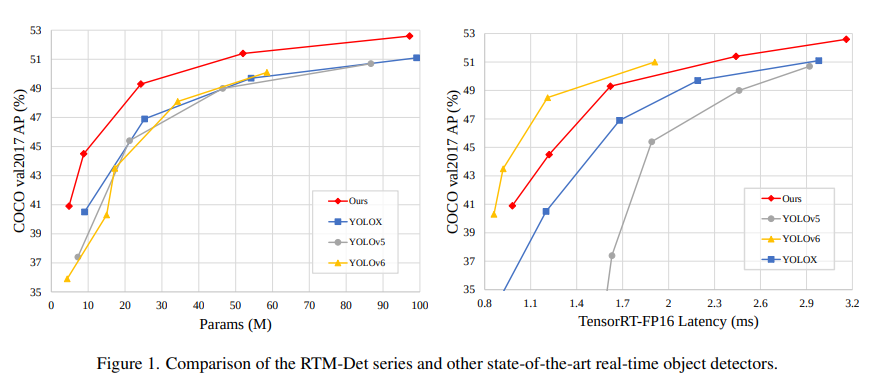
在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet, Real-time Models for Object Detection (Release to Manufacture)
RTMDet 由 tiny/s/m/l/x 一系列不同大小的模型组成,为不同的应用场景提供了不同的选择。 其中,RTMDet-x 在 52.6 mAP 的精度下达到了 300+ FPS 的推理速度。

抽象 BaseBackbone 的好处包括:
子类不需要关心 forward 过程,只要类似建造者模式一样构建模型即可。
可以通过配置实现定制插件功能,用户可以很方便的插入一些类似注意力模块。
所有子类自动支持 frozen 某些 stage 和 frozen bn 功能。
抽象 BaseYOLONeck 也有同样好处。
不同算法的主干网络继承 BaseBackbone,用户可以通过实现内部的 build_xx 方法,使用自定义的基础模块来构建每一层的内部结构。
你可以调用 demo/featmap_vis_demo.py 来简单快捷地得到可视化结果,为了方便理解,将其主要参数的功能梳理如下:
img:选择要用于特征图可视化的图片,支持单张图片或者图片路径列表。
config:选择算法的配置文件。
checkpoint:选择对应算法的权重文件。
--out-file:将得到的特征图保存到本地,并指定路径和文件名。
--device:指定用于推理图片的硬件,--device cuda:0 表示使用第 1 张 GPU 推理,--device cpu 表示用 CPU 推理。
--score-thr:设置检测框的置信度阈值,只有置信度高于这个值的框才会显示。
--preview-model:可以预览模型,方便用户理解模型的特征层结构。
--target-layers:对指定层获取可视化的特征图。
可以单独输出某个层的特征图,例如: --target-layers backbone , --target-layers neck , --target-layers backbone.stage4 等。
参数为列表时,也可以同时输出多个层的特征图,例如: --target-layers backbone.stage4 neck 表示同时输出 backbone 的 stage4 层和 neck 的三层一共四层特征图。
--channel-reduction:输入的 Tensor 一般是包括多个通道的,channel_reduction 参数可以将多个通道压缩为单通道,然后和图片进行叠加显示,有以下三个参数可以设置:
squeeze_mean:将输入的 C 维度采用 mean 函数压缩为一个通道,输出维度变成 (1, H, W)。
select_max:将输入先在空间维度 sum,维度变成 (C, ),然后选择值最大的通道。
None:表示不需要压缩,此时可以通过 topk 参数可选择激活度最高的 topk 个特征图显示。
--topk:只有在 channel_reduction 参数为 None 的情况下, topk 参数才会生效,其会按照激活度排序选择 topk 个通道,然后和图片进行叠加显示,并且此时会通过 --arrangement 参数指定显示的布局,该参数表示为一个数组,两个数字需要以空格分开,例如: --topk 5 --arrangement 2 3 表示以 2行 3列 显示激活度排序最高的 5 张特征图, --topk 7 --arrangement 3 3 表示以 3行 3列 显示激活度排序最高的 7 张特征图。
如果 topk 不是 -1,则会按照激活度排序选择 topk 个通道显示。
如果 topk = -1,此时通道 C 必须是 1 或者 3 表示输入数据是图片,否则报错提示用户应该设置 channel_reduction 来压缩通道。
考虑到输入的特征图通常非常小,函数默认将特征图进行上采样后方便进行可视化。
注意:当图片和特征图尺度不一样时候,draw_featmap 函数会自动进行上采样对齐。如果你的图片在推理过程中前处理存在类似 Pad 的操作此时得到的特征图也是 Pad 过的,那么直接上采样就可能会出现不对齐问题。

可以看看这篇文章:F-VLM: Open-vocabulary object detection upon frozen vision and language models


