【OpenMMLab-AI实战营第二期】06~MMDetection概述课
- 给出图片,用矩形框框出所有感兴趣的物体,预测物体种类。
- 物体的数量不固定,物体位置不固定,物体大小不固定
- 检测--定位-扣除图像
- 自动驾驶-环境感知/道路规划
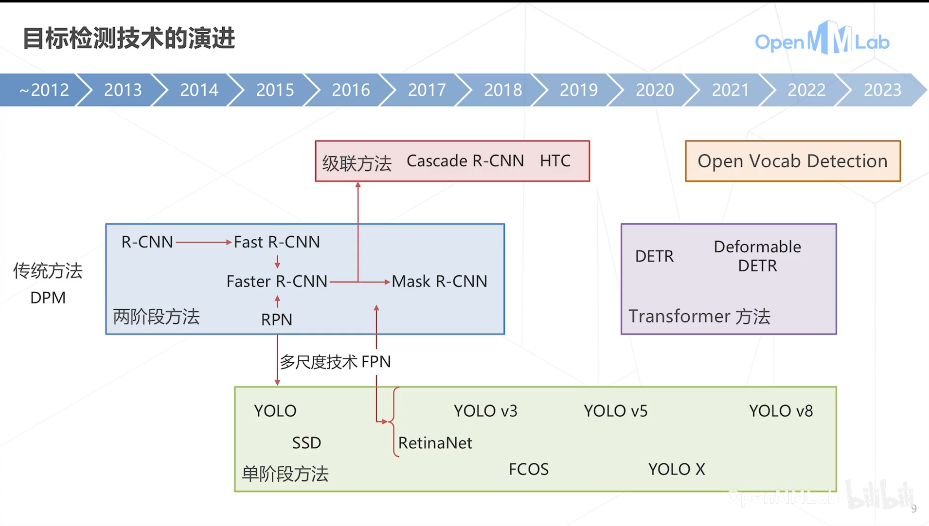
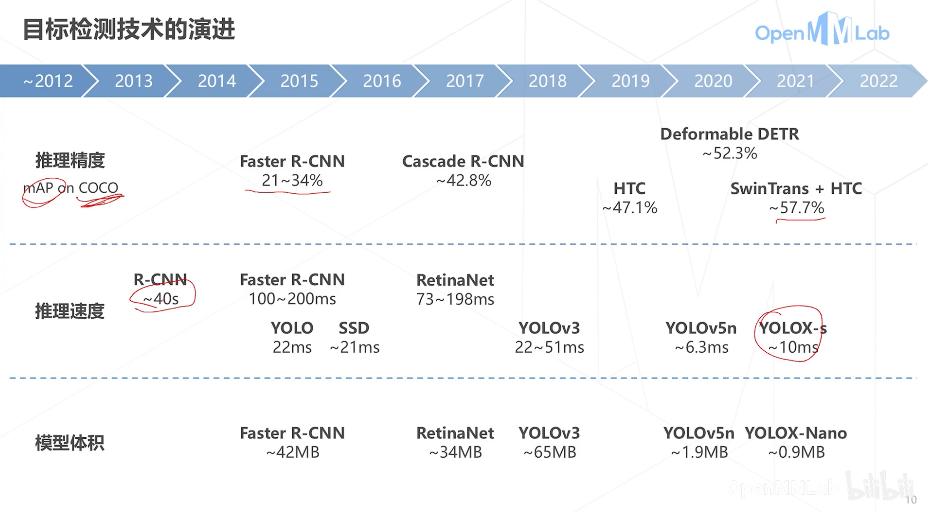
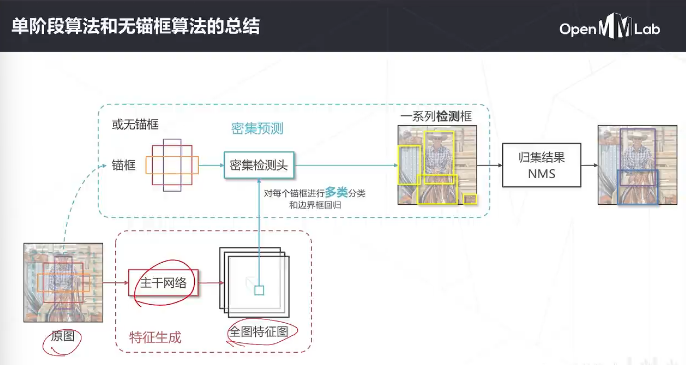
- 技术的演变历史
- 基础知识
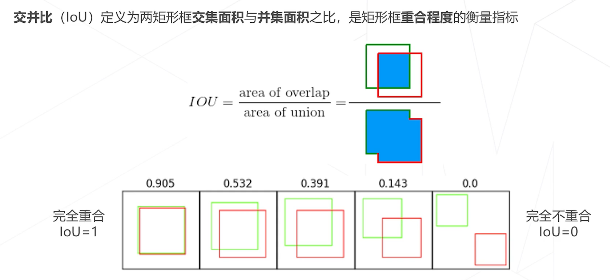
1~框和边界框

2~两个框以上的情况
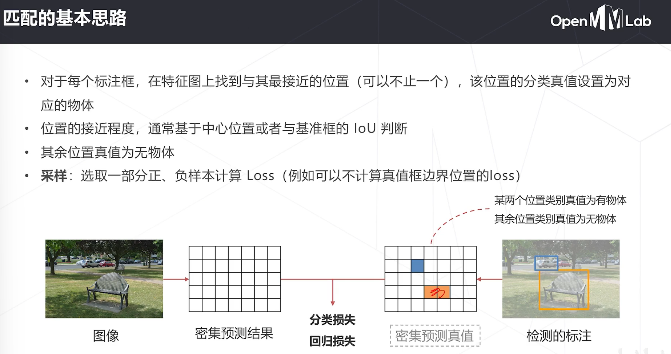
- 解决问题的思路
1-问题的难点:需要同时解决“是什么”和“在哪里” / / 图中物体位置,数量,尺度变化多样
滑窗sliding window:设定一个固定大小的窗口,遍历
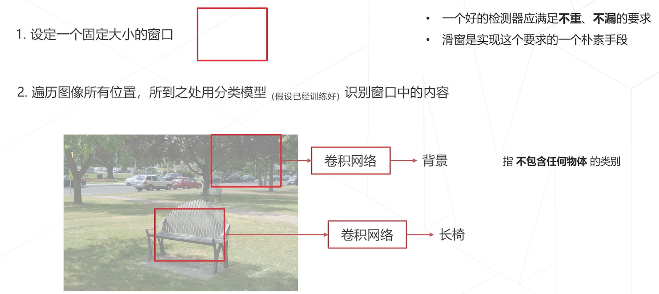

滑窗的效率问题难以解决
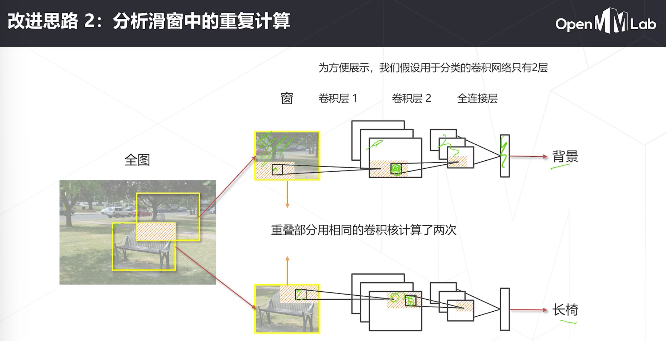
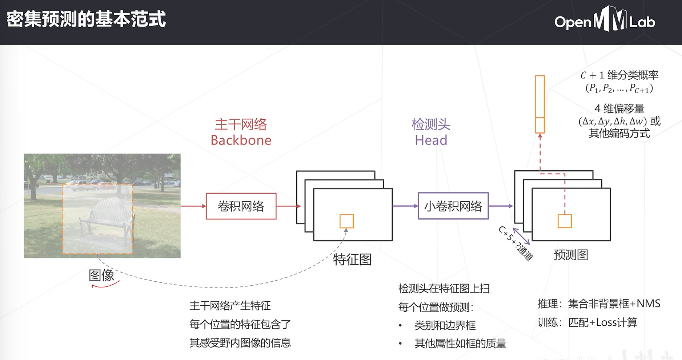
卷积是具有位置不变性的
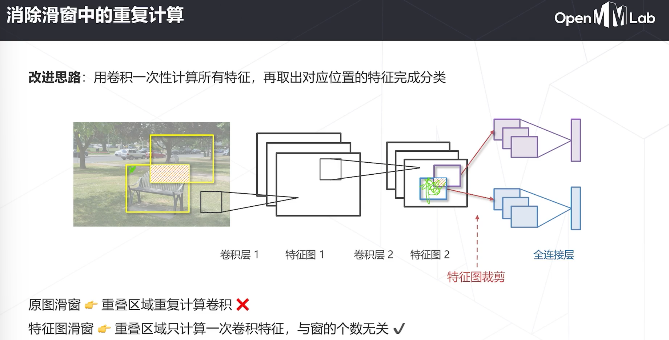


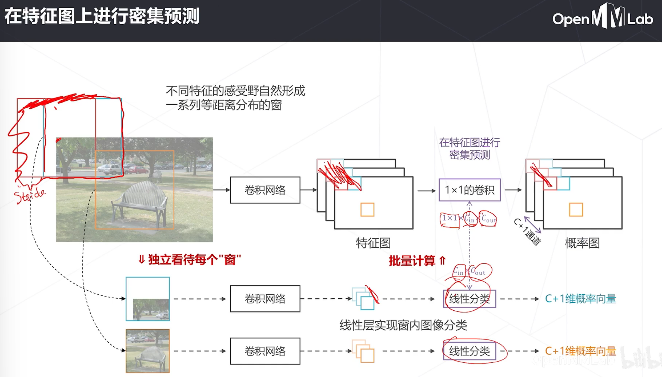
密集预测用卷积高效地实现了滑窗




- 密集预测之后的改进--多尺度预测


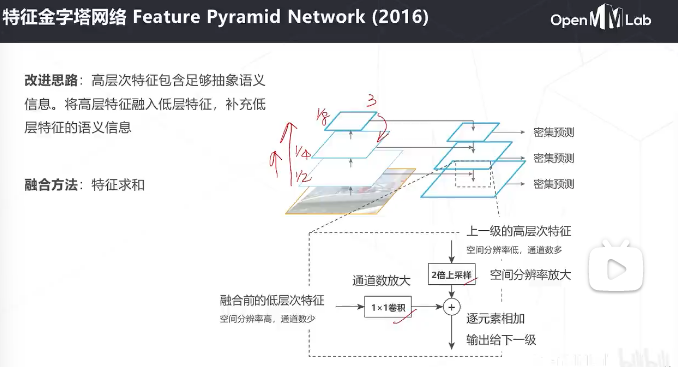
低层次定位信息好,高层次的语义信息好,将低层次的通道数放大,高层次的分辨率两倍上采样放大
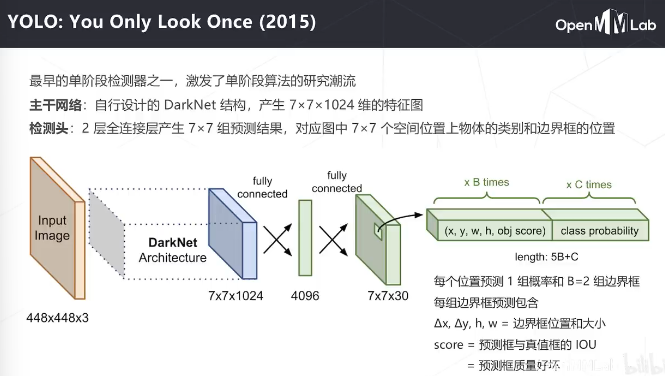
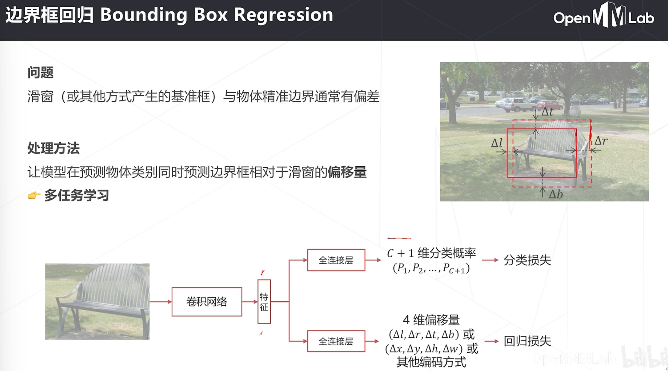
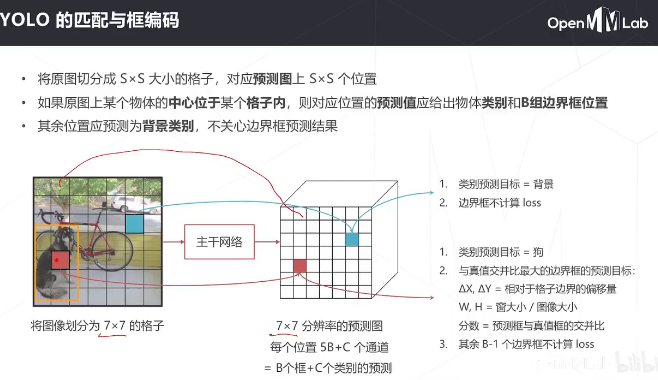
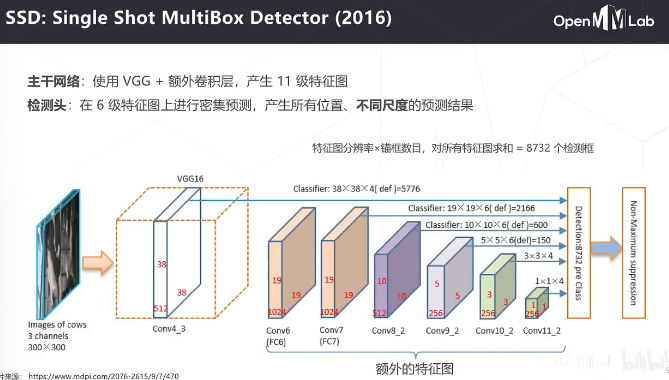
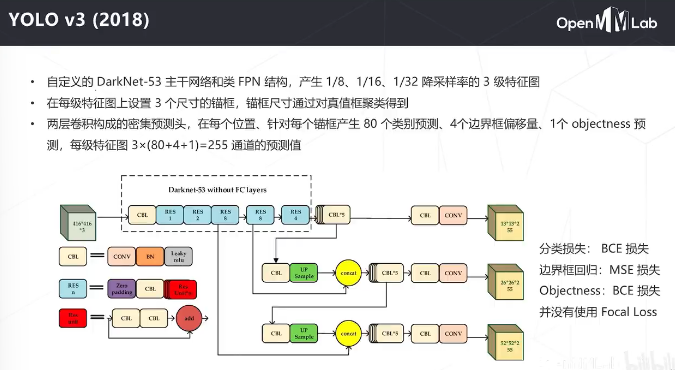
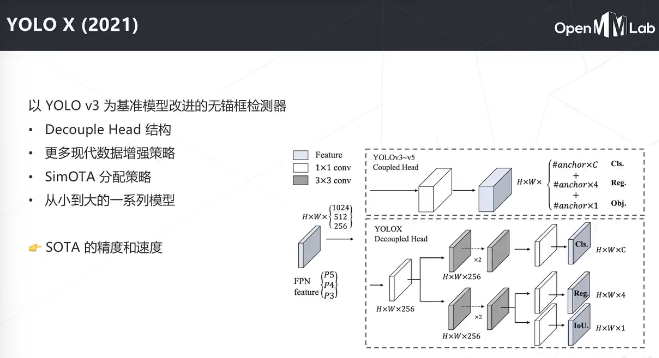
主干是自己设计的darknet, detax和detay是相对于中心位置的偏移量,h和w是框的大小

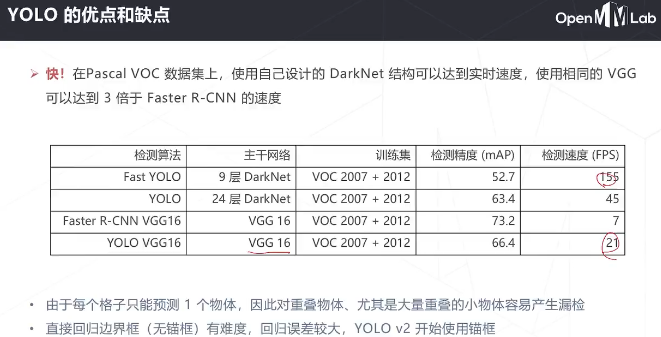
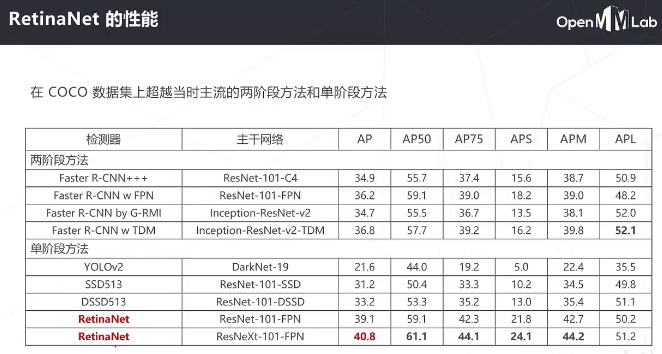
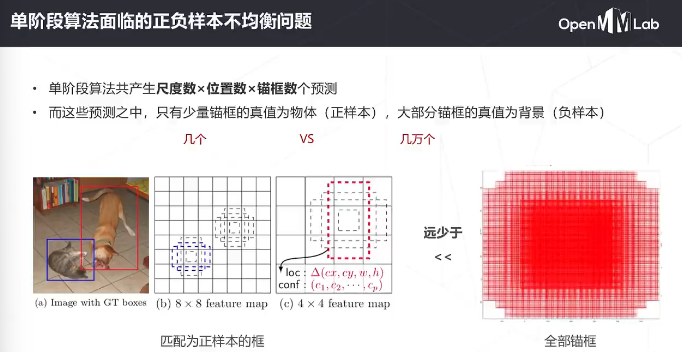

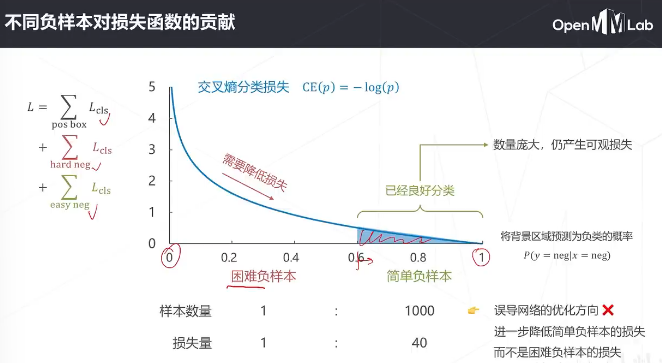
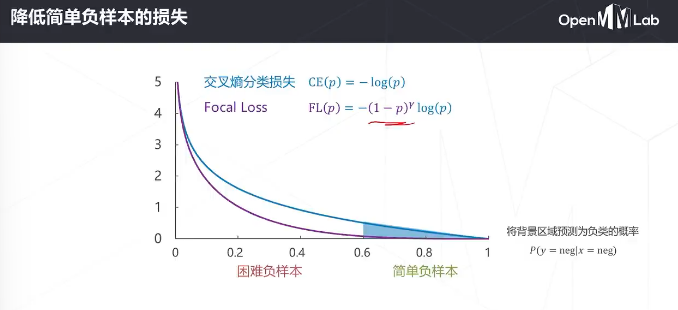
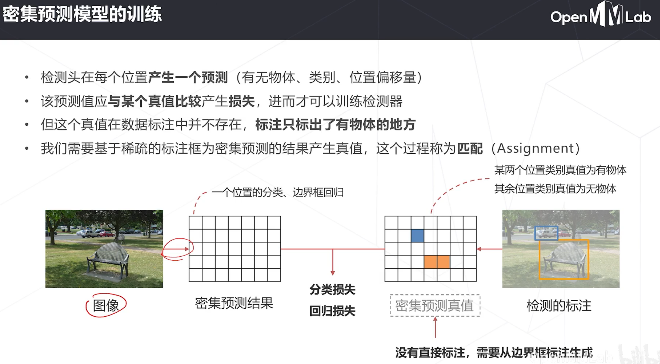
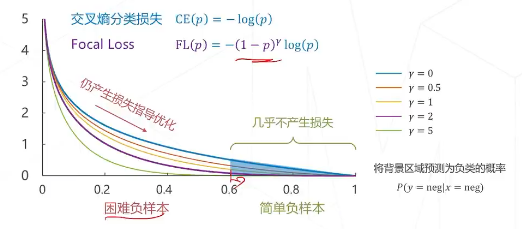
降低了简单负样本的影响

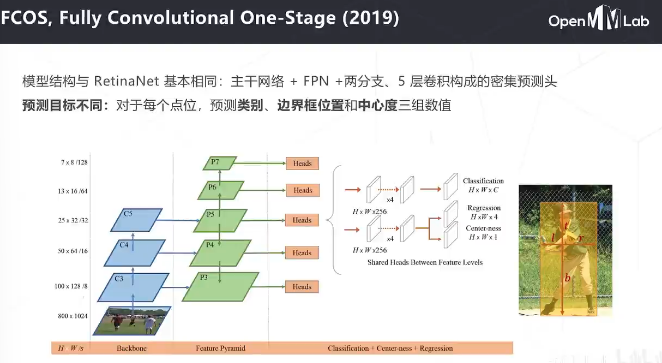

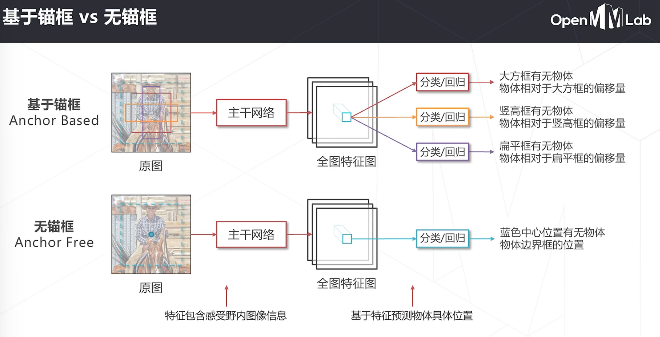
无锚框的方法存在样本重叠的问题


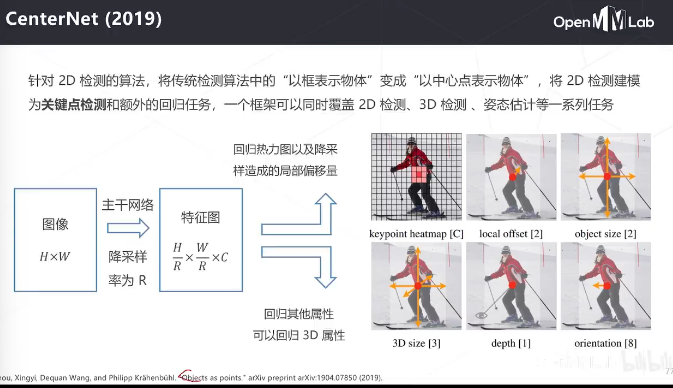
不再是基于框的检测方法
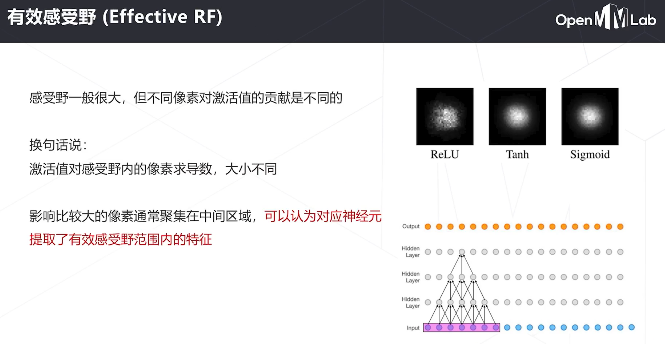
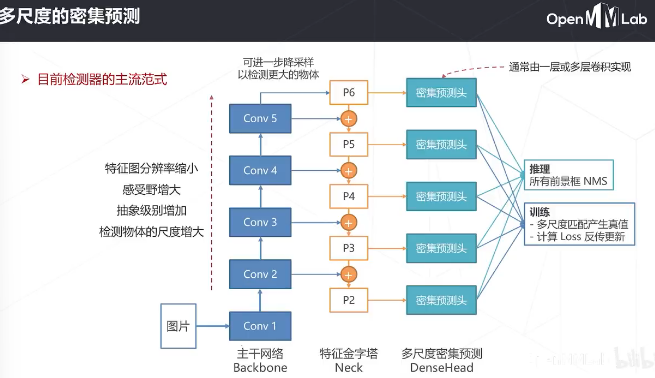
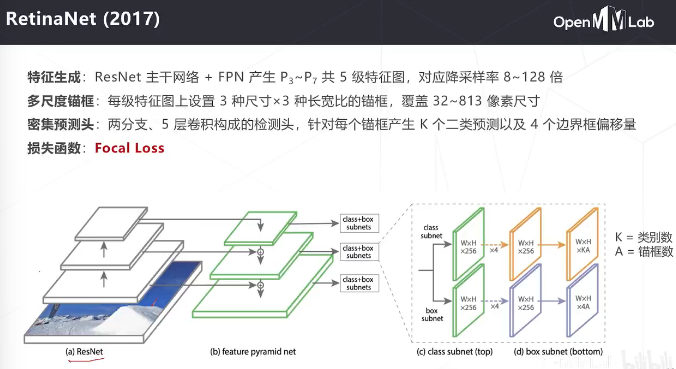
多级特征图有不同感受野的尺寸和不同的抽象层级,通常低层级的感受野比较小,抽象程度比较低,定位精度比较高;而高层的语义信息更丰富,但是定位精度会低一些。这时候采用FPN的结构对多级特征图进行融合,让高层次和低层次的特征图都有丰富的语义信息,同时低层次的特征图还有更高的定位精度:得到多层次的特征图。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

