



15,231
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享大家好,最近水妈出了本新书《数据思维实践》,得到了很多老师和学生的支持。作为回报,水妈今天带来一个精品案例,分析一下市面上跟大数据相关的书籍。
相信大家都有这种感觉:每天醒来,只要打开朋友圈,到处都是“大数据”和“人工智能”。不转发两条跟“大数据”有关的推文,都不好意思在朋友圈混下去。就连中国好声音的参赛歌手,清华生物学博士宿涵都用人工智能来作词。相信你的耳朵都快被“大数据”磨出茧子了,但是跟“大数据”相关的书,你又完整读过几本呢?它们又在讲些什么呢?

《中国好声音》明星学员,宿涵

大数据神书
一提到“大数据”相关的书籍,十个人有九个都会提到《大数据时代》。这本出版于2012年的书籍,作者是维克托?迈尔?舍恩伯格。书中指出,大数据带来的信息风暴正在变革我们的生活、工作和思维。作者表示:“大数据时代最大的转变就是,放弃对因果关系的渴求,而取而代之关注相关关系。大数据的核心就是预测。大数据将为人类的生活创造前所未有的可量化的维度。”
水妈虽然没有读过这本书,但是每每面试学生,都要听学生讲一遍书中的观点。说实话,大数据的核心就是预测,这个观点水妈实在不敢赞同。请熊粉们去复习一遍熊大的数据价值观。读书固然好,但要有自己的思考才更好。
图:大数据时代信息页
除了《大数据时代》,还有很多书名特别“奇葩”的书籍。《女士品茶》就是其中一本。这本书是统计学的经典之作,但是书名一直被人“误解”。本书是以某位喝茶的英国女士的假设学说为起点,引出了近代数理统计的开创者——Fisher,以及Fisher为解决类似问题而发明的实验设计法。书中细数了二十世纪参与这场科学变革的代表性人物与事迹。可谓数理统计的“八卦史”了。

另外一本就是《黑天鹅》。“黑天鹅”其实是欧洲人的一个梗。原来欧洲人认为天鹅都是白色的,直到发现澳大利亚竟然有黑天鹅,受到认知冲击的他们就将“黑天鹅”作为了言谈与写作中的惯用语,寓意着不可预测的重大稀有的“活久见”事件。书中正是借助“黑天鹅”来说明统计学中的随机性无论在哪里都随处可见,这些“活久见”在意料之外,却又改变一切。所以我们需要改变自己的思维方式,把握“黑天鹅”带来的机会,采取应对策略,从中受益。

用“数据”说话
为了对市面上的大数据书籍有一个更为深入的了解,我们选取了“大数据”“机器学习”“人工智能”“深度学习”“数据分析”“数据科学”“数据挖掘”“统计学”等关键词,把与这些关键词相关的中文书在某网站上抓取下来。不看不知道,一看吓一跳,我们总共爬到了688本书(你没看错,数量如此之多)。
对于每一本书,我们抓取了该书的作者、出版日期、出版社、内容简介、标签、书名等,均以文本形式呈现。

数据到手,作为文本分析的必经之路,还要进行相关的文本处理。这里主要是对每本书籍的内容简介信息进行了删去空格、制表符、特殊字符、标点符号、英文、数字等操作。每一本书籍的内容简介最终都会形成一个只包含汉字的字符串。后利用jieba分词词库进行分词,得到每一本书籍所对应的词汇及相应的词频。
透过年份看“大数据”书籍
近些年,我们的日常已经被“大数据”“深度学习”包围。不管是在图书馆的书架上,还是舍友的书桌上,亦或是在电梯间的广告上,“大数据”几乎无处不在。你是否能回忆起来,这种变化到底是在哪一年开始的呢?
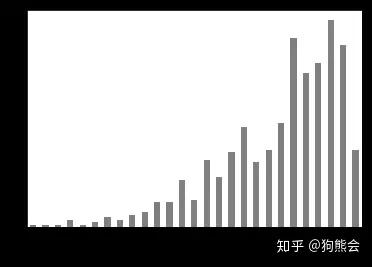
图:“数据”相关书籍年份出版量
在1990年到2000年,跟数据相关的书籍虽然出版数量一直在增长,但出版的总量相对较少,增长的幅度也比较小。这些书籍大都是统计学教科书,书中的知识更偏向于数学、概率论和数理统计,理论性比较强。2000年以后,出版数量开始呈现快速的增长。
到了2013年,书籍的出版数量开始有了一个井喷式的增长,较2012年增长了80.92%。随后的几年,出版数量一直保持在一个稳定的高产量,2016年更是创下了83本的惊人记录。也就是说,在2016年,平均每4.4天就有一本关于统计与大数据的书籍与大家见面。
因为数据爬取的时间为2018年6月,所以2018年的书籍并没有爬取完全,但按照上半年的趋势,2018年出版的书籍很有可能维持在70-80本的较高水平上。这样高的出版数量其实是这几年来“大数据”热的一个体现,也是数据应用渗透到工作和生活方方面面的体现。
透过词频看“大数据”书籍

对书籍简介进行文本分析后,选取每年词频最高的词作为年度热词,我们发现:2012年以前的年度热词大都为数据分析、技术、理论之类的词。在“大数据”这个名词火起来之前,相关书籍更偏向理论和技术等方面。在2013年至2016年,正是“大数据”这个名词最火热的一段时期,不少人提出我们已经进入“大数据时代”,书籍内容也都会与“大数据”相关,并且热度一直在攀升。在2016年之后,大家不再把“大数据”挂在嘴边了,在一次次被机器人刷屏的时候,“人工智能”又进入了大家的眼帘。越来越火的“人工智能”也成为了2017、2018年的年度热词。
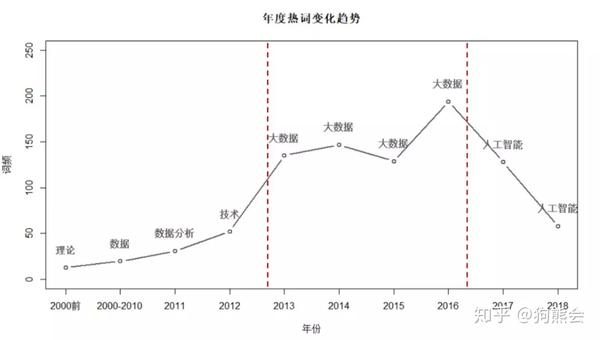
图:年度热词变化图
根据前面年度热词得出的趋势,我们将年份划分为2012年以前、2013~2016年,2017~2018年三段分别统计前5的词频,发现:2012年之前的书籍主要聚焦在:数据、统计、方法等。2013-2016年是大数据最火热的时期,其主要聚焦在大数据这个方向,并且热度有明显的提升。2017-2018年的书籍则逐渐向人工智能,深度学习方向发展。
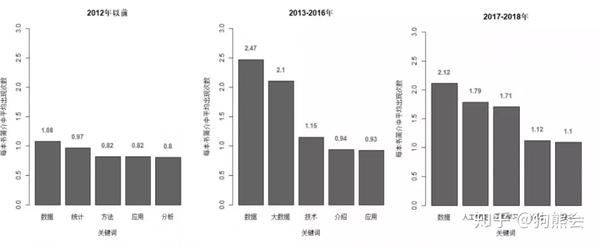
图:时代热词变化图
透过“标签”看“大数据”书籍
网友的智慧是无限哒,集读者之智慧的书籍标签,则能代表一本书籍的几个特点,那么来看一下通过各时间段的书籍标签我们能发现大数据书籍的哪一些特点吧!
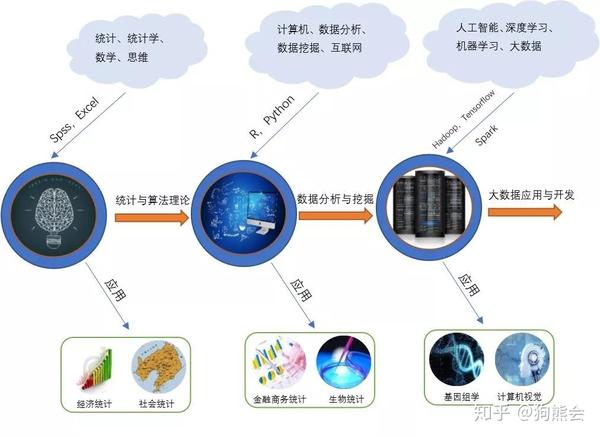
图:标签与统计学演变
将时间段分为2000年前,2000-2010年和2010-2018年,对每个时段的数据书籍标签进行统计,结果做成上图。可以看到在2000年以前,数据书籍大多理论比较强数据比较少,更多的是出现“统计”“数学”等标签。这个阶段统计和数据书籍着重研究的领域主要在统计理论,经济社会统计等方面。
到了2011年以后,性能更好的服务器和计算机制造出来。大数据和人工智能被不断结合。催生出了“机器学习”“深度学习”等研究领域。这个阶段统计和数据书籍着重研究的领域在基因组学、代谢组学的研究,计算机视觉和自然语言处理等。
那么有了数据,有了统计理论和算法后,好的编程语言、分布式架构以及数据结构是沟通这两者之间的桥梁。传统统计所使用的工具可能局限于Excel,SPSS这种图形化界面的数据处理工具。而到了数据科学时代,我们就多了R与Python这样的编程语言,再到大数据时代,我们就有了Hadoop,Spark分布式计算框架以及TensorFlow等等的机器学习框架。
图:三阶段代表性标签变化
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.czjy.cn;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。


