社区
OpenMMLab
社区活动
帖子详情
语义分割与MMSegmentation
超级蛋M
2023-06-12 21:32:49
本节主要介绍语义分割的基本思路和技术演进历程。
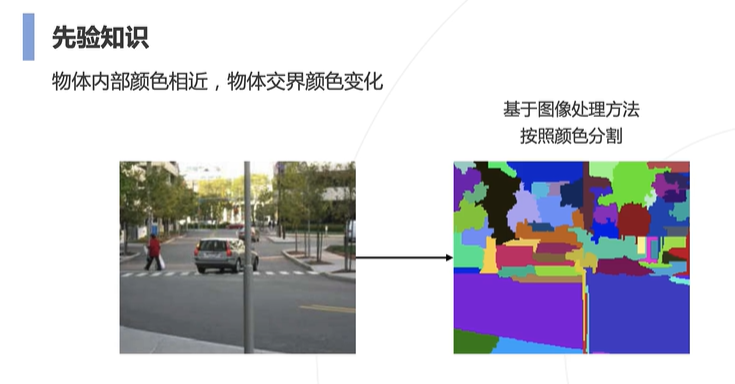
最早的最简单的思路是直接按照颜色做聚类:
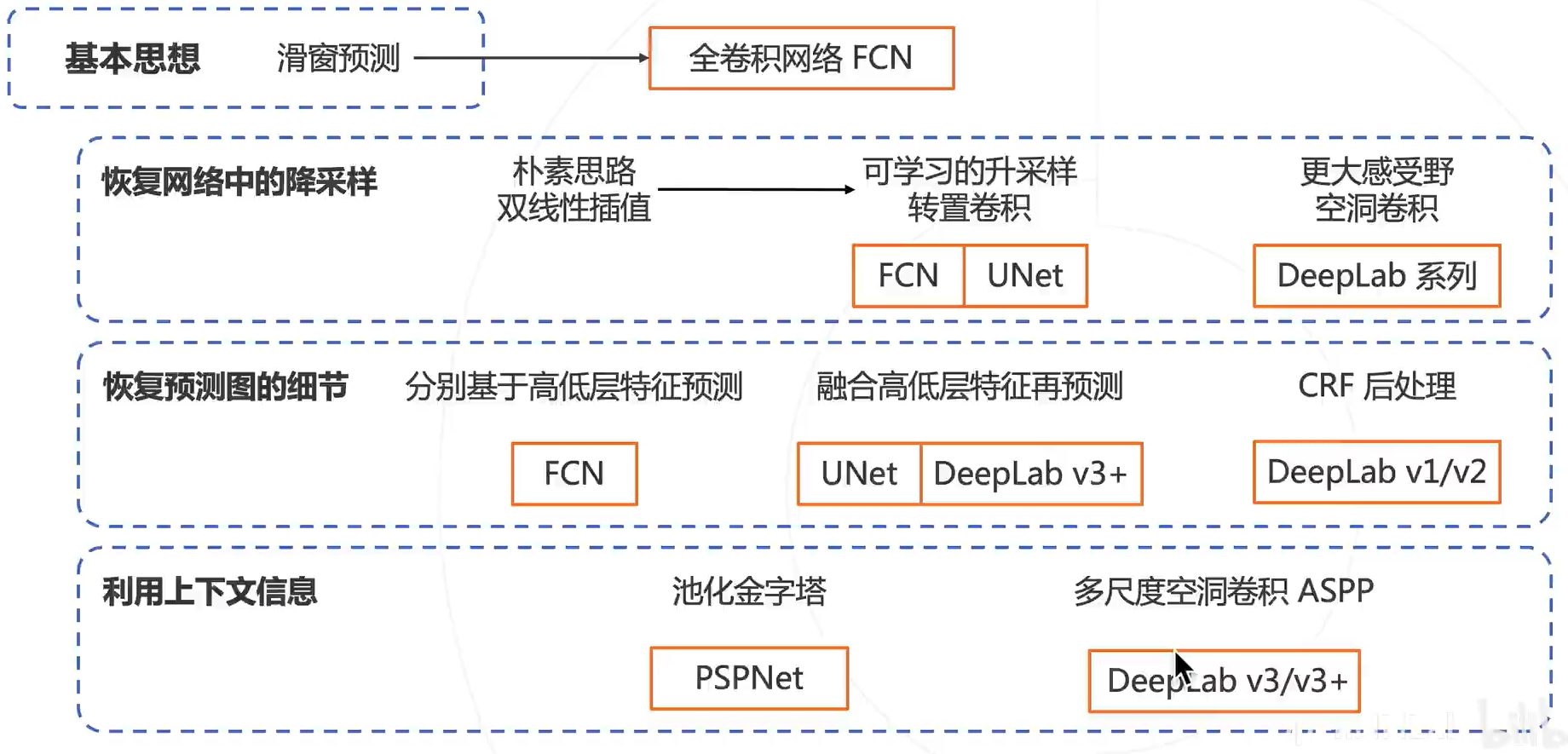
然后是卷积神经网络,与上一讲目标检测类似,为了解决滑窗预测计算成本过高的问题,引入了密集预测的方法
为突破传统卷积输入尺寸固定的局限性,设计了全卷积网络
上采样方法:插值、转置卷积、空洞卷积
其他方法:CRF后处理、特征金字塔、池化金字塔、ASPP空间金字塔等
...全文
69
回复
打赏
收藏
语义分割与MMSegmentation
本节主要介绍语义分割的基本思路和技术演进历程。 最早的最简单的思路是直接按照颜色做聚类: 然后是卷积神经网络,与上一讲目标检测类似,为了解决滑窗预测计算成本过高的问题,引入了密集预测的方法 为突破传统卷积输入尺寸固定的局限性,设计了全卷积网络 上采样
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
MMS
egmentat
ion
是一个基于 PyTorch 的
语义分割
开源工具箱 它是 OpenMMLab 项目的一部分
主要特性 统一的基准平台 我们将各种各样的
语义分割
算法集成到了一个统一的工具箱,进行基准测试。 模块化设计
MMS
egmentat
ion
将分割框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的分割模型。 丰富的即插即用的算法和模型
MMS
egmentat
ion
支持了众多主流的和最新的检测算法,例如 PSPNet,DeepLabV3,PSANet,DeepLabV3+ 等. 速度快 训练速度比其他
语义分割
代码库更快或者相当。
基于PyTorch和
MMS
egmentat
ion
框架的煤矸石图像
语义分割
深度学习项目_使用FCN网络结构进行煤矸石与煤炭的像素级识别与分类_实现对煤矿生产场景中煤矸石自动化检测与分.zip
基于PyTorch和
MMS
egmentat
ion
框架的煤矸石图像
语义分割
深度学习项目_使用FCN网络结构进行煤矸石与煤炭的像素级识别与分类_实现对煤矿生产场景中煤矸石自动化检测与分.zip
mms
egmentat
ion
框架实现
语义分割
任务,contract-dilat
ion
=True 的参数配置(含完整的程序和代码
内容概要:本文详细介绍了如何基于
mms
egmentat
ion
框架实现
语义分割
任务,重点聚焦于 contract_dilat
ion
=True 参数配置的深度空洞卷积网络。文中通过具体的代码示例和模型训练步骤展示了从环境准备、GUI 界面设计到模型训练、评估及可视化的全流程。该项目提供了全面的自动化支持,包括数据导入、超参数设置、模型训练、结果可视化和模型导出等功能。 适合人群:适用于有深度学习背景的研究人员和工程师,特别是关注
语义分割
技术和空洞卷积优化的人群。 使用场景及目标:该技术广泛应用于智能城市的图像处理、医学图像分割、卫星图像处理和机器人视觉系统等领域,目标是提高分割精度和效率。
计算机视觉
语义分割
多机多卡与单机单卡训练
mms
egmentat
ion
:分布式环境配置及模型训练流程详解
内容概要:本文详细介绍了多机多卡、单机单卡、单机多卡环境下训练
mms
egmentat
ion
的步骤。对于多机多卡情况,首先规定主从节点,确保各节点的模型文件、数据文件一致且环境相同(包括 cuda、torch、python 和 MMCV 版本)。然后设置无密码 SSH访问,开放必要端口以保障节点间的数据传输,配置 NCCL网络通信参数(如指定网卡接口、禁用 InfiniBand等),并通过 NFS创建临时共享文件夹供主节点获取从节点的模型结果。最后对
mms
egmentat
ion
代码进行适当修改以适应分布式训练需求,并给出命令提交方式。对于单机情况,提供了简化操作,以附件形式给出基于 segformer模型训练自定义数据集的基本流程,涵盖创建项目文件夹、准备配置文件、调整配置参数(如数据集类型、类别数量、归一化方式)、添加自定义数据集类及提交训练命令等内容。; 适合人群:熟悉 Linux操作系统,具有深度学习框架使用经验,尤其是从事图像分割领域研究或应用开发的技术人员。; 使用场景及目标:①为科研人员或工程师提供多机多卡、单机单卡、单机多卡训练
mms
egmentat
ion
模型的具体指导;②帮助用户掌握如何针对特定任务定制
mms
egmentat
ion
配置文件,包括但不限于选择合适的预训练模型、调整超参数、集成自定义数据集等。; 阅读建议:本文档内容详尽,涉及较多命令行操作与代码修改,建议读者先通读一遍理解整体流程,再根据自身需求逐步实践各部分操作,注意记录每一步骤的结果以便于排查可能遇到的问题。同时,对于初次接触分布式训练的读者,可以从单机单卡训练开始尝试,逐渐过渡到更复杂的多机多卡环境。
mms
egmentat
ion
mms
egmentat
ion
OpenMMLab
535
社区成员
1,595
社区内容
发帖
与我相关
我的任务
OpenMMLab
构建国际领先的计算机视觉开源算法平台
复制链接
扫一扫
分享
社区描述
构建国际领先的计算机视觉开源算法平台
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享